
Skype-Type(简称S&T)是一款功能强大的键盘声音窃听器,这款新颖的安全研究工具将允许他人执行键盘声音窃听攻击。简而言之,S&T可以通过窃听目标用户的键盘声音来窃取数据。

首先,S&T可以用目标用户键盘的每一个按键声音来训练一个机器学习模块,然后使用这个模块并根据用户敲击键盘的声音来判断他所输入的数据。
该项目是意大利帕多瓦大学(SPRITZ Group)和美国加州大学欧文分校(SPROUT)的一个合作研究项目。如果你想了解更多相关信息,可以访问该项目主页。【传送门】
如果你打算在自己的研究项目中使用S&T的话,请在你的报告中引用我们的论文:
Compagno, A., Conti, M., Lain, D., &Tsudik, G. (2017, April).
Don’t Skype & Type!: AcousticEavesdropping in Voice-Over-IP.
In Proceedings of the 2017 ACM on AsiaConference on Computer and Communications Security (pp. 703-715). ACM.
工具介绍
S&T是建立在操作链概念之上的,并通过基本模块的组合来实现其功能。这种模块化的设计将允许用户能够对每一个阶段的操作进行自定义配置。
操作链主要由以下四大主模块组成:监听器模块、调度器模块、机器学习模块和输出模块。每一个模块都可以加载不同的功能函数,并且还可以与之前的或之后的模块进行协同工作。每一个功能函数都有自己的子进程,并且使用了multiprocessing.Queue来进行通信。
监听器功能负责加载声音文件,然后将其传递给调度器。接下来,调度器会从音频文件或音频流中提取出键盘的击键声音,然后将其传递给机器学习模块来进行分类。最后的结果会传递给输出模块,然后给用户展示结果。
目标用户视角:
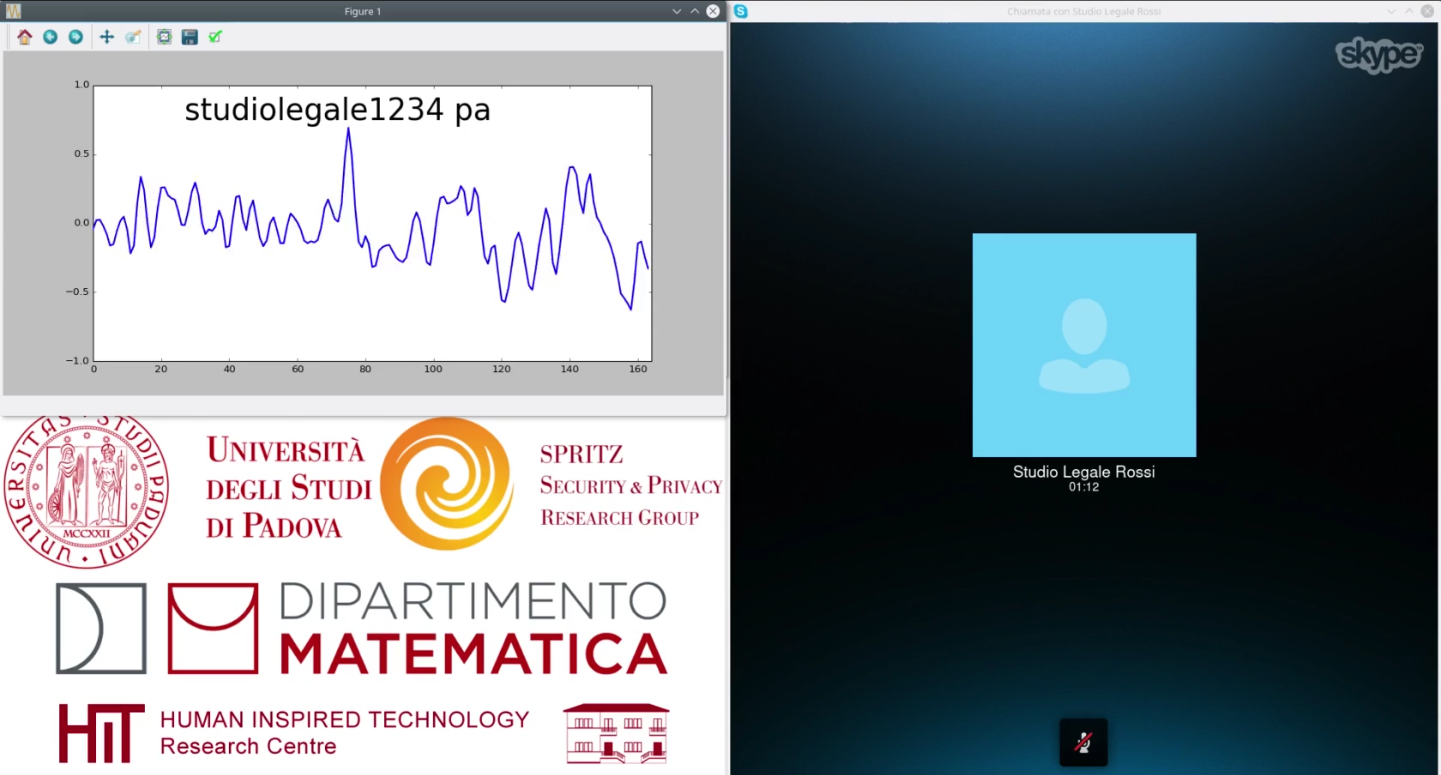
攻击者视角:
工具使用
首先,你需要生成一个sklearn.Pipeline,其中包含有一个分类器以及其他你需要转换的数据。比较简单的方法就是使用generate_model来完成这一步操作,然后向其发送训练数据:
generate_model.pytraining_files_and_folders output_model [...]所有的训练数据(文件)都以参数的形式进行传递,训练模块将会保存在特定路径。需要注意的是,训练用的声音数据必须是.wav格式,然后与wav文件同名的.txt文件中必须包含相对应的Groud Truth(简言之就是机器学习中的真实值),每一个目标为一行。Groud Truth中空格不会被当作字符,请用其他的字符替换。
启动S&T之后,我们可以通过命令行接口参数来手动指定操作链:
main.py --listener wavfile --dispatcheroffline ...或者也可以直接使用opmodes来进行自动加载:
main.py --opmode from_file使用样例
利用file1.wav、file1.txt以及folder1和folder2中的所有文件(训练数据)来生成一个机器学习模块,然后将生成的模块保存在folder3/model目录下:
generate_model.py file1.wav file1.txtfolder1 folder2 folder3/model运行S&T,记录下的目标键盘声音文件为targer.wav,使用folder3/model目录下的pipeline:
main.py --opmode from_file --targettarget.wav --pipeline folder3/model运行S&T,记录下的目标键盘声音文件为targer.wav,使用folder3/model目录下的pipeline,手动指定监听器以及程序调度块:
main.py --listener wavfile --dispatcheroffline --target target.wav --pipeline folder3/model工具要求
此后我们会为该软件提供一个完整的安装程序以及依赖组件管理功能。但目前来说,你需要手动安装该工具的依赖组件:
sklearn
numpy
python_speech_features
除此之外,如果你想利用S&T来窃取目前所有已知语言的信息,你可以在/dictionaries目录下存放你自己的字典文件。
未完成的内容
-编写完整的操作文档;
-上传单元测试;
* 参考来源:Skype-Type, FB小编Alpha_h4ck编译