
在此之前我收到了一些读者对我的反馈,他们希望我能够在文中解释相关解析器的开发流程。为了满足大家的需求,我决定和你们分享一个我非常重要的项目的完整实施过程。话不多说,让我们现在就开始!
当我开发这些脚本时,我对图像处理或其中的算法没有任何的了解或认知。最开始时我所能想到的就是:
图像基本上是一个矩阵,像素作为单独的单元格。
彩色图像具有每个像素的元组(红,绿,蓝)值,灰度图像具有单个值,并且一般图像中每个像素值的范围在(0,255)。
以下是我大学网站的登录界面:
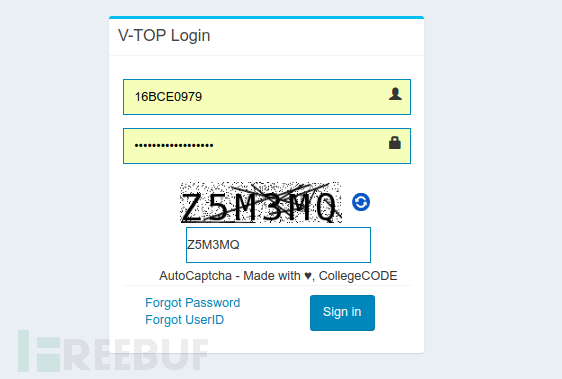
首先,我对验证码做了初步的观察分析。总结如下:

验证码中的字符位数始终为6位,并且是灰度图像;
字符之间的间隔看起来始终保持相同的间隔;
每个字符都是完全定义的;
图像有许多杂散的暗像素,以及穿过图像的线条
我决定下载一个图片验证码,并借助这款工具以二进制可视化图像(0表示黑色,1表示白色像素)。
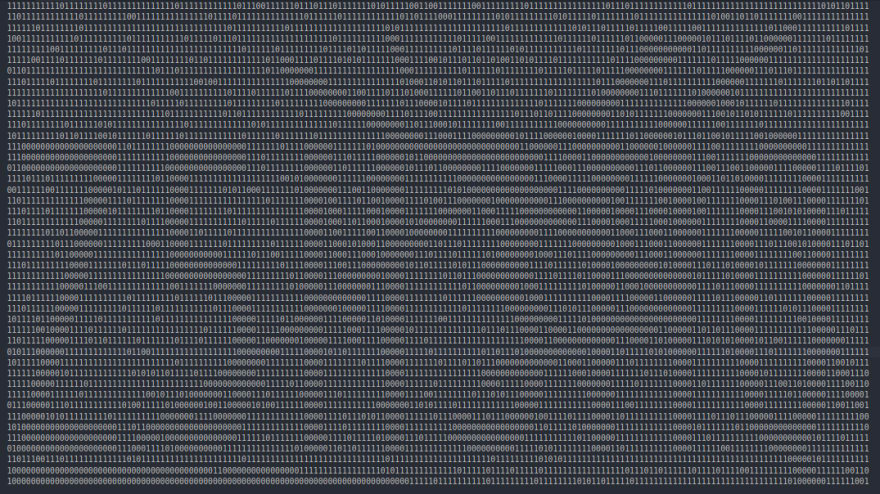
我的观察是正确的 – 图像尺寸为45×180,每个字符被分配一个30像素的空间来拟合,从而使它们均匀间隔。
因此,我的第1步是
将图像裁剪成6个不同的部分,每部分的宽度为30像素。
这里我选择使用Python作为我的开发语言,因为它的库最易使用和实现。
通过简单的搜索后,我找到了PIL库。我决定使用Image模块,因为我的操作仅限于裁剪并将图像作为矩阵加载。
所以,根据文档,裁剪图像的基本语法如下:
from PIL import Image
image = Image.open("filename.xyz")
cropped_image = image.crop((left, upper, right, lower))在本例中,如果你想裁剪第一个字符,
from PIL import Image
image = Image.open("captcha.png").convert("L") # Grayscale conversion cropped_image = image.crop((0, 0, 30, 45))
cropped_image.save("cropped_image.png")被裁剪保存的图像:

我将其包装在一个循环中,写了一个简单的脚本,从该站点获取500个验证码图像,并将所有裁剪后的字符保存到一个文件夹中。
第三次观察 – 每个字符都有明确的定义。为了“清理”图像中的裁剪字符(删除不必要的线和点),我使用了以下方法。
字符中的所有像素都是纯黑色(0)。我用了一个简单的逻辑 – 如果它不是完全黑色的,就视为白色。因此,对于值大于0的每个像素,将其重新分配为255。使用load()函数将图像转换为45×180矩阵,然后对其进行处理。
pixel_matrix = cropped_image.load() for col in range(0, cropped_image.height): for row in range(0, cropped_image.width): if pixel_matrix[row, col] != 0:
pixel_matrix[row, col] = 255 image.save("thresholded_image.png")为了更加清晰,我将代码应用至原始图像上。
原图:

处理后:
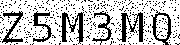
可以看到处理后的图像中的非纯黑像素都已被移除,其中包括穿插图像的线条。
直到项目完成后,我才知道上述方法被称为图像处理中的阈值处理。
第四次观察 – 图像中有许多杂散像素。
循环遍历图像矩阵,如果相邻像素为白色,与相邻像素相对的像素也为白色,且中心像素为黑色的,则使中心像素为白色。
for column in range(1, image.height - 1): for row in range(1, image.width - 1): if pixel_matrix[row, column] == 0 \ and pixel_matrix[row, column - 1] == 255 and pixel_matrix[row, column + 1] == 255 :
pixel_matrix[row, column] = 255 if pixel_matrix[row, column] == 0 \ and pixel_matrix[row - 1, column] == 255 and pixel_matrix[row + 1, column] == 255:
pixel_matrix[row, column] = 255输出:
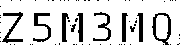
可以看到,此时图像中的字符基本已被单独分离出来了。
我将上述算法应用于所有裁剪的字符,并将它们存储在一个新文件夹中。下一个任务是为每个字符命名“abcDfgjnMnopqrStuvVXY012335667”。我以每个字符作为名称,如下:

随着这一步的完成,我现在有了每个字符的骨架图像(skeleton image)。
为了获取到字符在所有图像中的最佳图像,我运行了其他几个脚本,例如,如果有20个’A'字符图像,那么暗像素最少的图像显然是干扰最少的图像, 因此也最适合于骨架图像。 所以有两个脚本:
一个将按照字符排序的相似图像分组(约束条件:暗像素数量,相似度>= 90 – 95 %)
一个从每个分组字符中获得最佳图像
因此现在已生成了库图像。将它们转换为像素矩阵,并将“位图”存储为JSON文件。
最后,这是解决任何新的验证码图像的算法。
使用相同的算法减少新图像中不必要的干扰
对于新验证码图像中的每个字符,通过我生成的JSON位图强制执行。根据对应的暗像素匹配来计算相似度。
这意味着,如果一个像素为暗像素,在图像中的位置为(4,8),并且如果该像素在我们的骨架图像/位图中的相同位置处为暗像素,则计数值会递增1。
该计数与骨架图像中暗像素的数量相比,用于计算百分比匹配。
选择匹配率最高的字符。
import json
characters = "123456789abcdefghijklmnpqrstuvwxyz" captcha = "" with open("bitmaps.json", "r") as f:
bitmap = json.load(f) for j in range(image.width/6, image.width + 1, image.width/6):
character_image = image.crop((j - 30, 12, j, 44))
character_matrix = character_image.load()
matches = {} for char in characters:
match = 0 black = 0 bitmap_matrix = bitmap[char] for y in range(0, 32): for x in range(0, 30): if character_matrix[x, y] == bitmap_matrix[y][x] and bitmap_matrix[y][x] == 0:
match += 1 if bitmap_matrix[y][x] == 0:
black += 1 perc = float(match) / float(black)
matches.update({perc: char[0].upper()}) try:
captcha += matches[max(matches.keys())]
except ValueError:
print("failed captcha")
captcha += "0" print captcha最终得到的结果如下:

可以看到验证码被成功识别为Z5M3MQ!
总结
这个项目对于我本人而言,也是一次非常好的学习经历。我还开发了一个Chrome插件,目前有1800+的用户,欢迎大家安装使用!此外,如果你有任何的意见和建议也欢迎向我提出。以上的代码我已托管在GitHub,你可以在这里找到。
*参考来源:dev,FB小编 secist 编译,转自FreeBuf