
0×00 某些网站有反爬虫的机制
对于刚学习了几天python的我,对爬虫颇有兴趣,但是某些“想要的”网站上具有反爬虫机制,如果说使用延迟或者代理,这样的效率并不高,于是想了一种奇异的办法来高效率的绕过爬虫机制。(大佬口下留情)
0×01 写个爬虫(简单的介绍一下,各位都是爬虫大佬)
我找了一个比较典型的网站来进行爬虫,(已经打码)
第一页
第二页

只是more_XX.html中XX的改变。
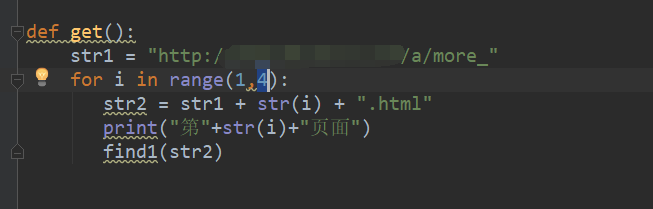
用python写一个生成不同页面的函数,如下图所示:
分析一下网页的源码

我们还需要获取一层链接,如果生来的话就是简单的缩略图。
写了一个这样的正则

具体找到这层链接的代码如下:

这层链接里面就是需要的高清大图,如下图:

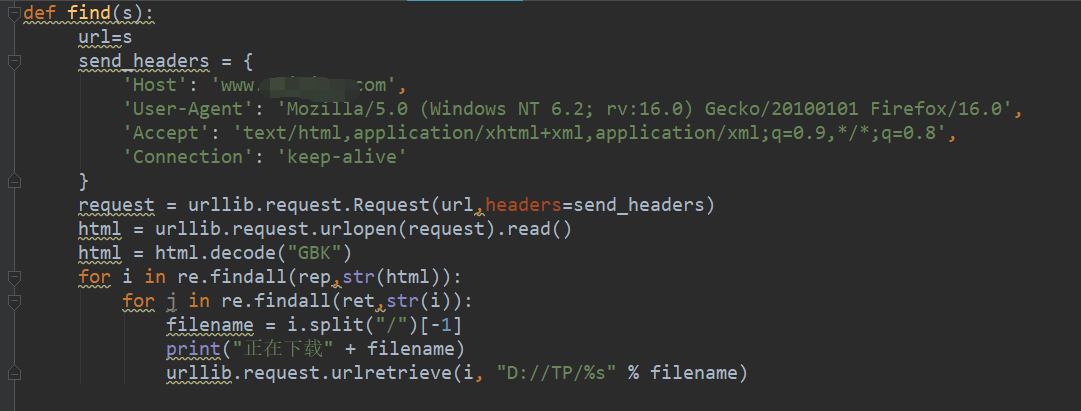
再写一个正则:

函数如下:
接下来原本以为用urllib.request.urlretrieve就可以直接下载了,但是没想到。
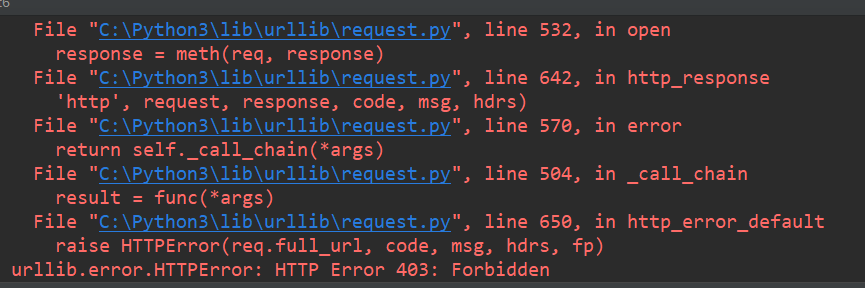
原来是做防爬机制。
0×02解决问题
我想到的是哪里的东西写错了么?
我们输出一下正则匹配过后的东西。
修改如下:
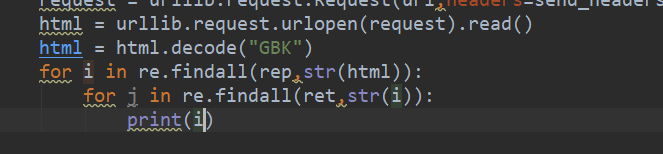
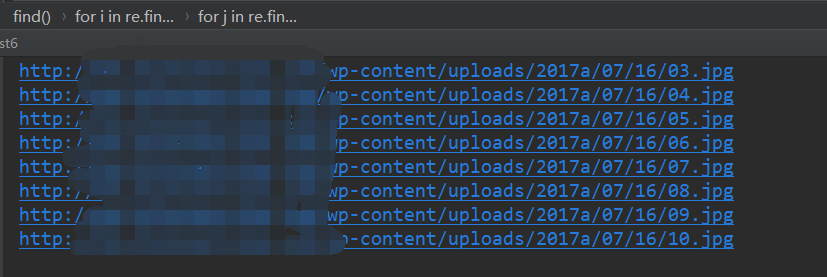
没问题啊!!怎么办呢?
想到了一个感觉可以实行的办法。
把连接保存到TXT里面,用迅雷批量?
修改一下代码
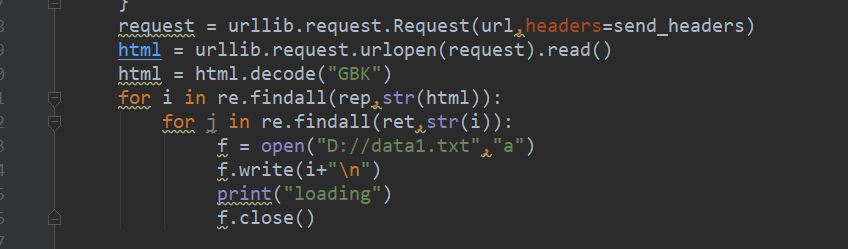
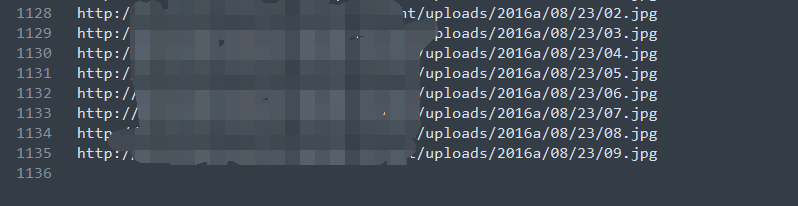
重要的问题就是这样的行为太傻了。
导出来的是URL,是否能够通过URL直接下载?
(导出了4个页面的)
我想到了C++的一个URL下载的函数。
URLdownloadtofile
以下是我写的一个下载函数

两个参数分别是url地址,第二个是保存路径格式。
这样的想法是能够快速的爬出来我们想要的东西,因为如果说使用代理的话,或者是延迟爬虫,这样影响效率,(只是个人的感觉)。
0×03 效果
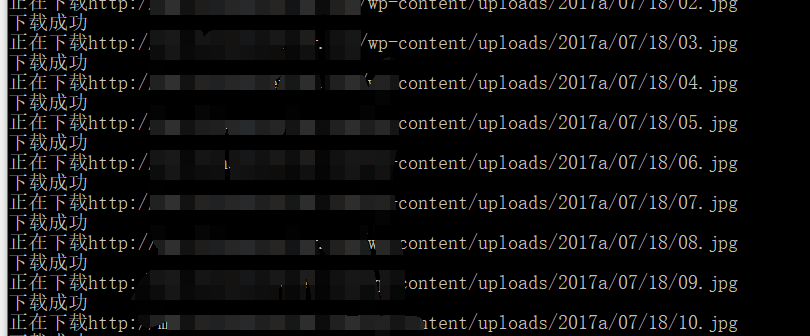
感觉速度很快!
1128个图片,用了3分钟,还没做优化,就是单一的下载。
我们来看看是否下载成功。
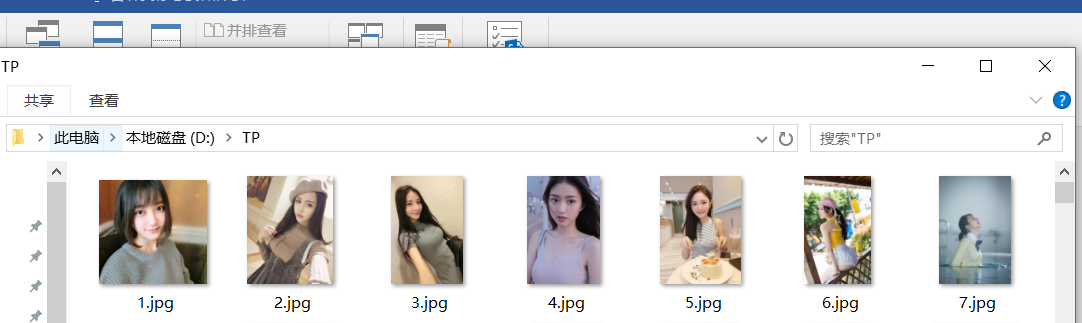
只能说是可能还有更好的解决方案,作为一个刚入门的新手爬虫,只能想到这样的解决方法。
大佬们有什么建议可以提供给我,或者更好的解决方案,可以私下沟通一下。
* 本文作者:我的gtr弹射起步