
整个六月你我都很忙,你忙着钓鱼、我忙着封锁 IP,一份邮件把我从紧张的氛围中拉了出来,邮件大意为“蓝队的朋友想要加分么?你如果能协助国际刑警修复从犯罪嫌疑人电脑上取证的受损图片,那么便可以在演习行动中为你加分,国际刑警求助信息 We received this PNG file, but we’re a bit concerned the transmission may have not quite been perfect,受损图片见附件”。
无疑,这是一封来自红队的钓鱼邮件,收件是我的办公邮箱 yangfoobar@sc.chinamobile.com,发送人邮箱地址用 swaks 伪造为 @110.com 的邮件域名,我在沙盒中简单分析了下附件图片,文件类型幻数 89 50 4E 47 0A 1A 0A 看起来像似 PNG,IHDR、IDAT、IEND 等等关键数据块也有,所以,从框架上来说,它应该是个 PNG 格式的图片;另外,IEND 后,出现了大量 powershell 脚本,我基本上可以研判,它是用 Invoke-PSImage 制作的图片马。传统意义上的图片马,指的是,将一句话写入图片,图片上传至 web 目录,结合 web 的解析漏洞或者文件包含漏洞,实现 getshell 的目的;而钓鱼邮件中的图片马并非此类,它内嵌反弹命令的 shellcode,用 wireshark 抓取 CC 的 IP,结合威胁情报,可溯源到红队归属的安全企业。
溯源不是本文的重点,我搜索了国际刑警的留言信息,找到了原始图片,原本是 PlaidCTF 在 2015 年出的一道取证的题目 PNG_Uncorrupt,刚好演习结束了,我得给自己找找乐子,在几乎安全取证相关技术背景为零的情况下,决定研究下这道题目,或许能获得新知识。
题意可知,文件传输可能导致该 PNG 文件破损,得尝试修复。先确认文件类型:
file 命令通过文件类型幻数分析文件类型,既然它无法识别,可能幻数错误,确认下: 这与 PNG 正确的幻数 89 50 4E 47 0D 0A 1A 0A 不一致,缺少 0D,用十六进制工具编辑该文件,在第一个 0A 前插入 0D 后另存为 new.png:
这与 PNG 正确的幻数 89 50 4E 47 0D 0A 1A 0A 不一致,缺少 0D,用十六进制工具编辑该文件,在第一个 0A 前插入 0D 后另存为 new.png:
再次识别文件类型:
cool,BUT,仍然无法渲染:
没事、没事,看下错误详情:
原来是位于 0×00071 的 IDAT 数据块 CRC 校验失败,该 IDAT 数据块的实际内容有 131072 个字节,任意字节的任意位错误,都可能导致 CRC 失败,若是暴力猜解,有 2 ** 8 ** 131072 种可能,显然无法落地。不可蛮力、只能巧劲!
PNG 图片内含多个数据块(chunk),每个数据块依次由四个域组成:长度(length)、类型代号(chunk type code)、实际内容(chunk content)、循环冗余校验码(CRC,cyclic redundancy check):
长度域,4 字节,指定实际内容域的大小,而非该数据块的大小;
类型代号域,4 字节,指定该数据块的类型;
实际内容域,长度域所指定的字节数,存放该数据块的实际内容数据;
校验码域,4 字节,由类型代号域和实际内容域组合计算而得。
我用十六进制编辑器分析该数据块。跳至 0×00071 处:
蓝色部分为长度域(即,0×00020000);黄色高亮为该数据块的类型代号域(即,”IDAT”);紫色为该数据块的实际内容域(即,具体像素),从位于 112 + 0×05 的位置开始,应该在哪个位置结束?从PNG 规范可知,PNG 内含多个 IDAT 数据块,依次连续且无间隔,上个 IDAT 数据块的最后一个字节后面一定是下个 IDAT 数据块的第一个字节:
换言之,我只要找到下个关键字 IDAT 的位置,往前退 4 个字节的长度域,再往前退 4 个字节的校验码域,所在位置就是当前 IDAT 数据块的实际内容的结束位置。具体而言,我找到第二个 IDAT 关键字,往前退 4 + 4 个字节,到达字节 DD 字节所在的位置 131184 + 0×03 就是结束位置:
逻辑上,长度域的值应该等于实际内容域的字节数量,前者为0×20000,即 131072,后者为 (131184 + 0×03) – (112 + 0×05) + 1,即 131071,咦~咦,怎么不等呢?捋一捋,位于 0×00071 的 IDAT 数据块,本应存放 131072 个字节的实际内容,但却因某些原因丢失了一个字节(131072 – 131071),这个字节可能是任意内容、可能出现在任意位置,若是暴力猜解,有 2 ** 8 * 131072 = 33554432 种可能,嗯,可以接受,接下来,我得实现个暴破脚本。
PNG 规范可知,校验码域是通过 CRC32 算法对类型代号域和实际内容域求值而来,脚本在实际内容域的第一个字节前依次尝试插入 [0, 255] 范围内的值,验证 CRC32 结果是否等于校验码域,若不等继续尝试在第二个字节前插入,直到找到或者完成所有可能的验证。python 内置的 zlib.crc32() 函数支持 CRC32 算法:
参数必须是 bytes 类型,所以我得以二进制模式读入文件。为了减少干扰,我把位于 0×00071 的 IDAT 数据块的类型代号域和实际内容域的数据转存至文件 idat1 中:
三下五除二,实现了暴破功能,如下: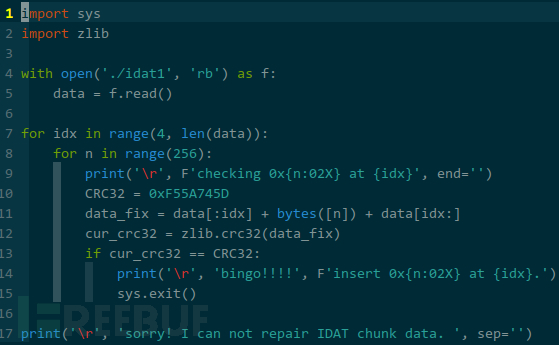
跑起来,20s 不到就收到好消息: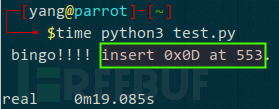
酷,哈`哈`哈!
看看位置 553 是啥内容,0x0A,等一等,感觉之前见过,思索思索,最开始修复文件幻数时,在 0x0A 前插入了 0x0D,修复这个 IDAT 数据块时,也是在 0x0A 前插入了 0x0D,结合题目所述”文件传输可能导致该 PNG 文件破损“,印象中,win 采用 0x0D0x0A 换行,而 linux 采用 0x0A 换行,我可以合理猜测,该 PNG 文件传输时,0x0D0x0A 被替换成 0x0A,所以,代码无需尝试在任意位置插入任意字节,只需验证在哪些 0x0A 前插入 0x0D,但不是每个 0x0A 前插入 0x0D,优化代码: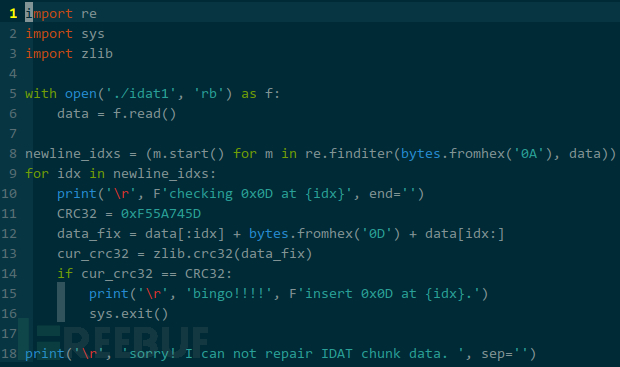
秒秒钟出来: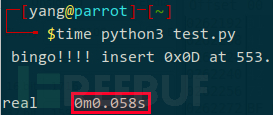
另外,由于 idat1 位于 new.png 的 113 位置,所以 idat1 中的 553 位置就对应 new.png 的 113 + 553 即 666 处,插入字节 0x0D 后另存为 new_fix1.png:
打开试试:
WTF!!不应该,思路没问题啊,看看错误详情:
哦哦,原来报错的是另一个 IDAT 数据块,先前位于 0×00071 的 IDAT 数据块已经成功修复,还是有点不放心,要是有工具能渲染已经修复的那部分图像数据就好了。linux 严格遵循 PNG 规范,CRC 校验不通过就无法渲染,好像 win 不那么严苛,到 win 下试着打开 new_fix1.png:
WOW,有点小兴奋呢 :-)。你看,我们常诟病 win 不遵循行业规范,在这里反而变成”超强容错“的优点,事物永远都有两面性,用辨证的眼光去….(滚!!),sorry!
用相同方式,我继续分析位于 131196 的 IDAT 数据块。先从 new.png 提取该数据块,将 131184 + 0x0C 作为开始地址:
将 262256 + 0x0C 作为结束地址:
右键选择 save as dump,另存为 idat2。分析过程与之前类似,预期实际内容为 0×020000 个字节,而真实只有 (262256 + 0x0C) – (131184 + 0x0C + 4) + 1 个,缺失 3 个字节,按先前的预判,均为 0x0A 前的 0x0D,基于这一思路,继续优化代码,让其实现猜测多个字节。
缺失 3 个字节比 1 个字节在代码实现上要所谓麻烦些。比如,aaaa,若为在 a 前丢失 1 个字节(x)后的字符串,反推原始字符串,只需依次在每个 a 前添加 x 就好,即, xaaaa、axaaa、aaxaa、aaaxa 四种可能;若为在 a 前丢失 2 个字节(x)后的字符串, 则原始字符串可能为 xaxaaa、xaaxaa、xaaaxa、axaxaa、axaaxa、aaxaxa六种可能,也就是,从 4 个中选出 1 个有几种可能,以及, 从 4 个中选出 2 个又有几种可能,python 的 itertools.combinations() 函数可以帮我实现:
回到题目中,我先找出所有 0x0A 的位置(newline_idxs),缺失多少个(lost_bytes_cnt)字节,就从中选出多少个组合:
另外,由于位置是相对的,插入元素将导致后面元素的位置发生变化,这得注意。比如,有一字符串 aaaa,四个 a 的位置依次为 0、1、2、3,若我在第一个 a 的位置 0 前插入 x 后,要想在第二个 a 前继续插入 x,则必须使用 1 + 1 的位置,因为当前字符串已经变为 xaaaa,这比较麻烦,所以,我换了个方式,从后往前插入,位置 3 的 a 插入后为 aaaxa、位置 2 的 a 插入后为 aaxaxa。回到题目中,我将需要插入 0x0D 的位置先作逆向排序:
代码如下:
大约运行 1M 后出结果:
由于找到的位置是 idat2 中的位置,idat2 又从 new.png 的131196 位置开始,所以,对应至 new.png 中的位置,131196 + 125131 即 256327、131196 + 26274 即 157470、131196 + 502 即 131698,另外,idat1 丢失的字节位置为 666,所以,我依次在 256327、157470、131698、666 前插入字节 0x0D,并且一定得从后往前插入(●﹏● 18+),另存为 new_fix2.png。
经确认,第一、二个 IDAT 数据块修复成功,第三个报错: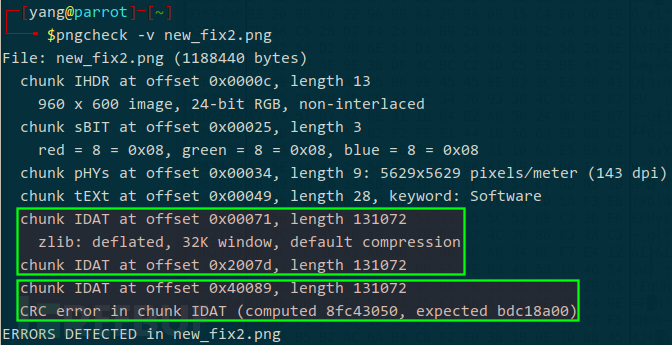
看看渲染后的效果: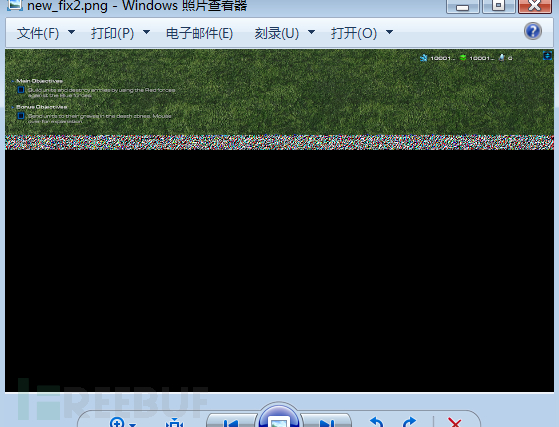
不错!
思路清晰了、方向明确了,用相同的方法处理其他 IDAT 数据块,就能修复整个图片文件。前面思路中,提取 IDAT 数据块的类型代号域和实际内容域、分析缺失的字节数量、图片文件中插入新数据等等,这些人工完成的工作,都应由脚本实现。
我在十六进制编辑器中找出所有 IDAT 关键字: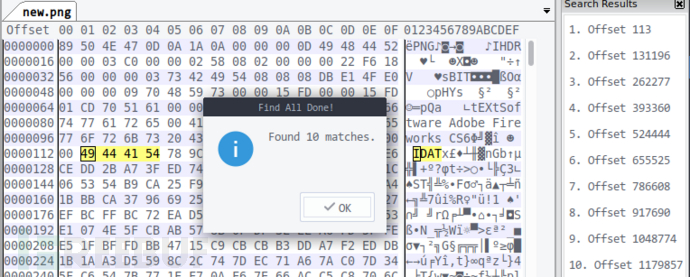
有十个 IDAT 数据块啊,我得继续优化前面的代码,让它自动提取 IDAT 数据块、分析缺失字节数量、找出应在哪些 0x0A 前插入 0x0D,简单封装,实现类 PngIncompleteIdatChunks: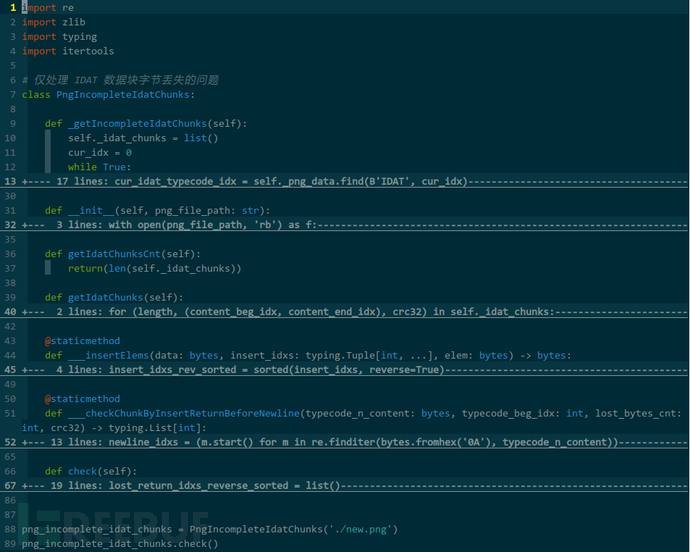
运行代码: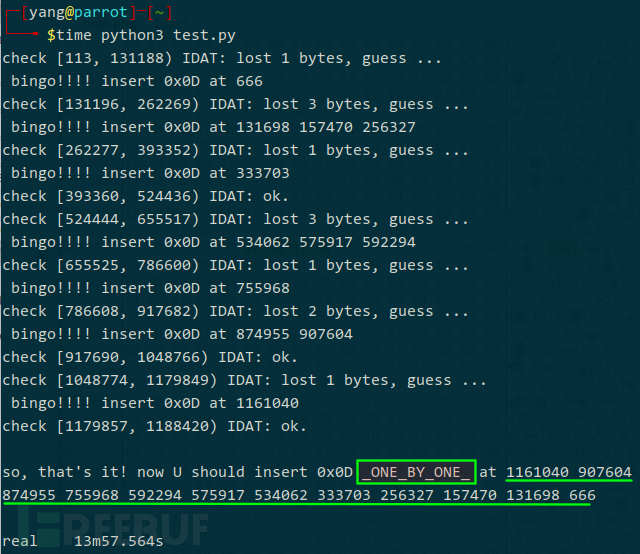
漫长的等待,十四分钟后找回了所有丢失的 0x0D 字节!中途一度怀疑某些临界环境未考虑周全,刚好何阳同志过来找我出去抽了根烟,回来就出结果了。现在,只需按脚本提示,将 0x0D 依次从后往前插入new.png 的对应位置即可修复整张图片,但是,作为食物链顶端的我,怎么能屈尊去做这些低端低级的体力活儿呢,还得有劳脚本。
在类 PngIncompleteIdatChunks 中增加了 suggest()、fix() 两个成员函数,前者用于显示图片修复建议,后者实际修复图片,如下: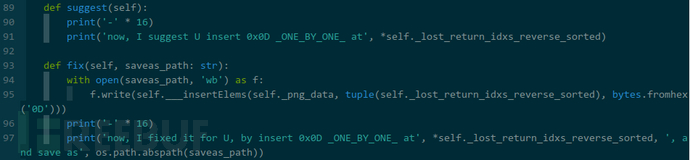
整个 PoC 完整代码如下:
import re import os import zlib import typing import itertools # 仅处理 IDAT 数据块字节丢失的问题 class PngIncompleteIdatChunks: def __init__(self, png_file_path: str): with open(png_file_path, 'rb') as f:
self._png_data = f.read()
self._getIncompleteIdatChunks()
self._check()
def _getIncompleteIdatChunks(self): self._idat_chunks = list()
cur_idx = 0 while True:
cur_idat_typecode_idx = self._png_data.find(B'IDAT', cur_idx)
if cur_idat_typecode_idx == -1:
break
# 提取长度域 length = self._png_data[cur_idat_typecode_idx - 4: cur_idat_typecode_idx]
# 提取实际内容域的起止位置 next_typecode_idx = self._png_data.find(B'IDAT', cur_idat_typecode_idx + 4)
if next_typecode_idx == -1:
next_typecode_idx = self._png_data.find(B'IEND', cur_idat_typecode_idx + 4)
idat_content_end_idx = next_typecode_idx - 4 - 4 idat_content_beg_idx = cur_idat_typecode_idx + 4 # 提取校验码域 crc32 = self._png_data[idat_content_end_idx: idat_content_end_idx + 4]
self._idat_chunks.append((length, (idat_content_beg_idx, idat_content_end_idx), crc32))
cur_idx = next_typecode_idx
def getIdatChunksCnt(self): return(len(self._idat_chunks))
def getIdatChunks(self): for (length, (content_beg_idx, content_end_idx), crc32) in self._idat_chunks:
yield(int(length.hex(), 16), (content_beg_idx, content_end_idx), int(crc32.hex(), 16))
@staticmethod
def ___insertElems(data: bytes, insert_idxs: typing.Tuple[int, ...], elem: bytes) -> bytes: insert_idxs_rev_sorted = sorted(insert_idxs, reverse=True)
for insert_idx in insert_idxs_rev_sorted:
data = data[:insert_idx] + elem + data[insert_idx:]
return(data)
@staticmethod
def ___checkChunkByInsertReturnBeforeNewline(typecode_n_content: bytes, typecode_beg_idx: int, lost_bytes_cnt: int, crc32) -> typing.List[int]: newline_idxs = (m.start() for m in re.finditer(bytes.fromhex('0A'), typecode_n_content))
maybe_return_idxs_combin = itertools.combinations(newline_idxs, lost_bytes_cnt)
for maybe_return_idxs in maybe_return_idxs_combin:
print('\r', 'try to insert 0x0D at', *maybe_return_idxs, end='')
data_fix = PngIncompleteIdatChunks.___insertElems(typecode_n_content, maybe_return_idxs, bytes.fromhex('0D'))
if zlib.crc32(data_fix) == crc32:
return_idxs = [idx + typecode_beg_idx for idx in maybe_return_idxs] # 相对位置转绝对位置 print('\r', 'bingo!!!! insert 0x0D at', *return_idxs)
return(list(return_idxs))
print('\r', 'sorry! I can not repair IDATA chunk. ', sep='')
return(list())
def _check(self): self._lost_return_idxs_reverse_sorted = list()
for (length, (content_beg_idx, content_end_idx), crc32) in self.getIdatChunks():
print(F'check [{content_beg_idx - 4}, {content_end_idx}) IDAT: ', end='')
context_bytes_cnt = content_end_idx - content_beg_idx
if length == context_bytes_cnt:
print('ok. ')
continue elif length < context_bytes_cnt:
print('too many bytes. ')
continue
lost_bytes_cnt = length - context_bytes_cnt
print(F'lost {lost_bytes_cnt} bytes, guess ...')
lost_return_idxs = self.___checkChunkByInsertReturnBeforeNewline(self._png_data[content_beg_idx - 4: content_end_idx], content_beg_idx - 4, lost_bytes_cnt, crc32)
self._lost_return_idxs_reverse_sorted.extend(lost_return_idxs)
def suggest(self): print('-' * 16)
print('now, I suggest U insert 0x0D _ONE_BY_ONE_ at', *self._lost_return_idxs_reverse_sorted)
def fix(self, saveas_path: str): with open(saveas_path, 'wb') as f:
f.write(self.___insertElems(self._png_data, tuple(self._lost_return_idxs_reverse_sorted), bytes.fromhex('0D')))
print('-' * 16)
print('now, I fixed it for U, by insert 0x0D _ONE_BY_ONE_ at', *self._lost_return_idxs_reverse_sorted, ', and save as', os.path.abspath(saveas_path))
png_incomplete_idat_chunks = PngIncompleteIdatChunks('./new.png')
png_incomplete_idat_chunks.fix('./new_fixed.png')
运行结果:
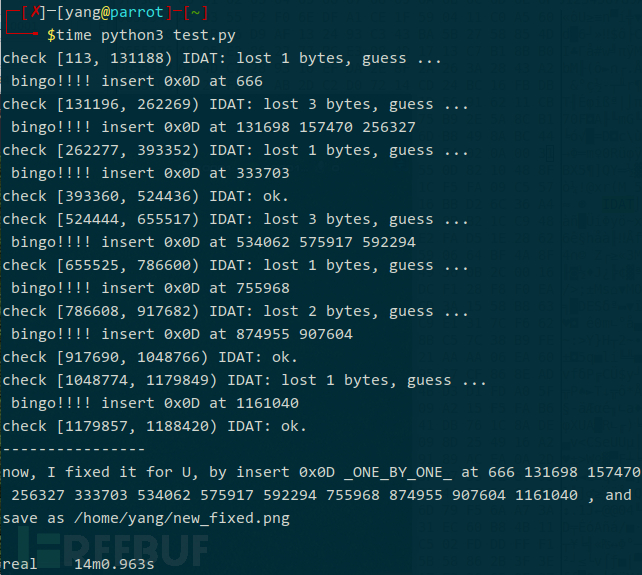
看看修复效果: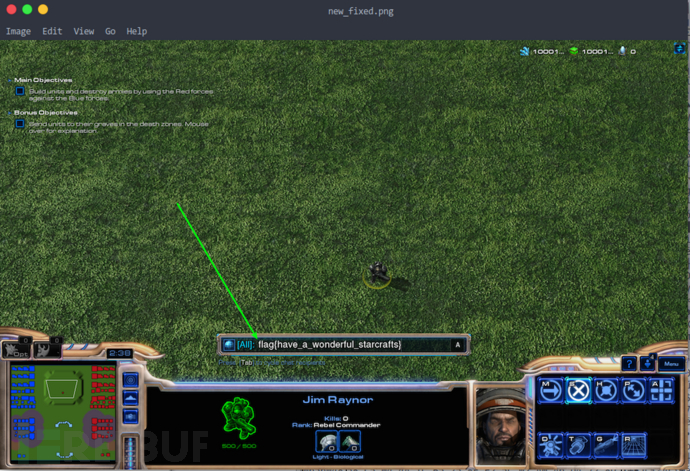
成功找到 flag,还没完,如果正式比赛,还得提交文字版本的 flag,看着图片手输?不行,不够洋气,光学字符识别,于是,我把 new_fixed.png 适当放大后,截取 flag 部分另存为 flag.png:
接着 OCR:
文本 flag 出来了,拷贝提交即可。
最后,被我溯源的那台 CC 并没写入蓝队报告中,因为,虽然我在蓝队,但有颗红心!另外,六月未丢分的企业,并不能证明你们的安全做到位了,只能说明系统下线、封锁网段的临时防御手段有效,七月重新上线的、没有 7 × 24 监控的系统,没准一打一个中。成绩,是静态的,安全,是动态的,你知道我在说什么。
(BTW,借助 IM 工具 LX 的漏洞去拿蓝队终端的手法,大赞 :)
*本文作者:yangyangwithgnu