
背景
在分析日志的时候发现有些日志中参数中包含其他的URL,例如:
http://www.xxx.cn/r/common/register_tpl_shortcut.php?ico_url=http://www.abcfdsf.com/tg_play_1121.php&supplier_id=3&ep=tg&style=szsg_reg_tg03
http://b.xxx.cn?c=<IMG src="http://www.thesiteyouareon.com/somecommand.php?somevariables=maliciouscode">
http://b.xxx.cn?c=<SCRIPT a=">" src="http://xss.ha.ckers.org/a.js"></SCRIPT>
提取请求参数中的URL(xss.ha.ckers.org),再对比威胁情报数据库,如果命中黑名单直接标黑。如果不在黑名单,也不在公司的白名单里可以先做个标记,后续着重分析。
提取URL
关于URL的提取网上有很多文章,大部分都是是使用正则表达式,方法简单但是不太准确。我这里提供一种方法:采用词法分析,提取域名和IP。思路借鉴了这篇文章:https://blog.csdn.net/breaksoftware/article/details/7009209,有兴趣的可以去看看,事实证明跟着大神确实涨姿势。
原文是用C++版本,这里我用Python写了一个类似的,供大家参考。
常见的URL分类
IP形式:192.168.1.1,10.20.11.1
Domain形式:baidu.com、www.sina.com,freebuf.com
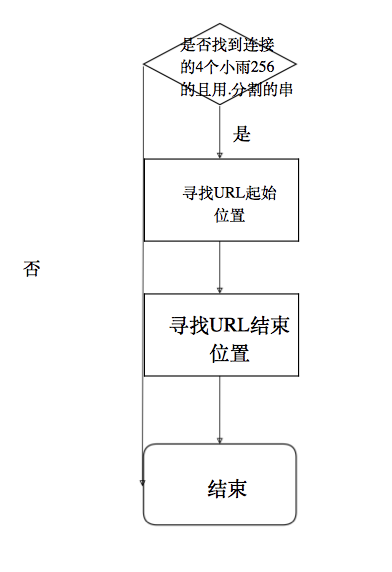
观察可以见得:IP形式的URL结构最为简单:4个小于255的数字被.分割;domain形式比较复杂,但是它们有共性:都具有顶级域名.com。
定义合法字符:
legalChars = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ-_" legalNumers = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] 顶级域名列表:
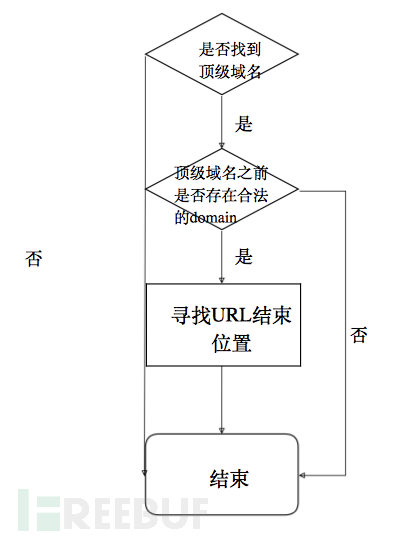
topLevelDomain = ['biz', 'com', 'edu', 'gov', 'info', 'int', 'mil', 'name', 'net', 'org', 'pro', 'aero', 'cat', 'coop', 'jobs', 'museum', 'travel', 'arpa', 'root', 'mobi', 'post', 'tel', 'asia', 'geo', 'kid', 'mail', 'sco', 'web', 'xxx', 'nato', 'example', 'invalid', 'test', 'bitnet', 'csnet', 'onion', 'uucp', 'ac', 'ad', 'ae', 'af', 'ag', 'ai', 'al', 'am', 'an', 'ao', 'aq', 'ar', 'as', 'at', 'au', 'aw', 'ax', 'az', 'ba', 'bb', 'bd', 'be', 'bf', 'bg', 'bh', 'bi', 'bj', 'bm', 'bn', 'bo', 'br', 'bs', 'bt', 'bv', 'bw', 'by', 'bz', 'ca', 'cc', 'cd', 'cf', 'cg', 'ch', 'ci', 'ck', 'cl', 'cm', 'cn', 'co', 'cr', 'cu', 'cv', 'cx', 'cy', 'cz', 'de', 'dj', 'dk', 'dm', 'do', 'dz', 'ec', 'ee', 'eg', 'eh', 'er', 'es', 'et', 'eu', 'fi', 'fj', 'fk', 'fm', 'fo', 'fr', 'ga', 'gb', 'gd', 'ge', 'gf', 'gg', 'gh', 'gi', 'gl', 'gm', 'gn', 'gp', 'gq', 'gr', 'gs', 'gt', 'gu', 'gw', 'gy', 'hk', 'hm', 'hn', 'hr', 'ht', 'hu', 'id', 'ie', 'il', 'im', 'in', 'io', 'iq', 'ir', 'is', 'it', 'je', 'jm', 'jo', 'jp', 'ke', 'kg', 'kh', 'ki', 'km', 'kn', 'kp', 'kr', 'kw', 'ky', 'kz', 'la', 'lb', 'lc', 'li', 'lk', 'lr', 'ls', 'lt', 'lu', 'lv', 'ly', 'ma', 'mc', 'md', 'me', 'mg', 'mh', 'mk', 'ml', 'mm', 'mn', 'mo', 'mp', 'mq', 'mr', 'ms', 'mt', 'mu', 'mv', 'mw', 'mx', 'my', 'mz', 'na', 'nc', 'ne', 'nf', 'ng', 'ni', 'nl', 'no', 'np', 'nr', 'nu', 'nz', 'om', 'pa', 'pe', 'pf', 'pg', 'ph', 'pk', 'pl', 'pm', 'pn', 'pr', 'ps', 'pt', 'pw', 'py', 'qa', 're', 'ro', 'rs', 'ru', 'rw', 'sa', 'sb', 'sc', 'sd', 'se', 'sg', 'sh', 'si', 'sj', 'sk', 'sl', 'sm', 'sn', 'so', 'sr', 'st', 'su', 'sv', 'sy', 'sz', 'tc', 'td', 'tf', 'tg', 'th', 'tj', 'tk', 'tl', 'tm', 'tn', 'to', 'tp', 'tr', 'tt', 'tv', 'tw', 'tz', 'ua', 'ug', 'uk', 'um', 'us', 'uy', 'uz', 'va', 'vc', 've', 'vg', 'vi', 'vn', 'vu', 'wf', 'ws', 'ye', 'yt', 'yu', 'za', 'zm', 'zw'] 域名形式提取:如www.baidu.com。
if self.isLegalChar(zv): i = 0 reti = 0 tokenType = TK_OTHER while (i < len(z) and self.isLegalChar(z[i])): i = i + 1 reti = i while i < len(z) and z[i] == '.': i = i + 1 urltoken_str = z[i:len(z)]
urltoken_str = urltoken_str.lower() if urltoken_str in topLevelDomain: i = i + len(urltoken_str)
reti = i
tokenType = TK_DOMAIN while (i < len(z) and self.isLegalChar(z[i])): i = i + 1 reti = i if i < len(z) and z[i] == ':': i = i + 1 while (i < len(z) and z[i].isdigit()): i = i + 1 reti = i if tokenType == TK_DOMAIN: check_url = z[0:i] if check_url.find(':') >= 0: check_url = check_url[0:check_url.find(':')] for item in topLevelDomain: pos = check_url.find('.' + item) if pos > -1 and (pos + len(item) + 1 == len(check_url)): self.urls.append(z[0:i]) IP形式提取:如192.168.1.1。
while (i < len(z) and z[i].isdigit()):
i = i + 1 ip_v1 = True reti = i if i < len(z) and z[i] == '.':
i = i + 1 reti = i else:
tokenType = TK_OTHER
reti = 1 while (i < len(z) and z[i].isdigit()):
i = i + 1 ip_v2 = True if i < len(z) and z[i] == '.':
i = i + 1 else: if tokenType != TK_DOMAIN:
tokenType = TK_OTHER
reti = 1 while (i < len(z) and z[i].isdigit()):
i = i + 1 ip_v3 = True if i < len(z) and z[i] == '.':
i = i + 1 else: if tokenType != TK_DOMAIN:
tokenType = TK_OTHER
reti = 1 while (i < len(z) and z[i].isdigit()):
i = i + 1 ip_v4 = True if i < len(z) and z[i] == ':':
i = i + 1 while (i < len(z) and z[i].isdigit()):
i = i + 1 if ip_v1 and ip_v2 and ip_v3 and ip_v4: self.urls.append(z[0:i]) return reti, tokenType else: if tokenType != TK_DOMAIN:
tokenType = TK_OTHER
reti = 1
混合形式提取:如1234.com。
扫描前半部分1234,符合IP形式的特征,但是发现代码会报异常,所以需要IP处理代码段添加判断:判断后缀是否是顶级域名:
urltoken_str = z[i:len(z)]
urltoken_str = urltoken_str.lower() if urltoken_str in topLevelDomain:
i = i + len(urltoken_str)
reti = i
tokenType = TK_DOMAIN 结果测试
测试数据:
192.168.1.1 mp3.com http:www.g.cn http:\www.g.cn http:\\/\www.g.cn admin:@www.g.cn http://10.10.10.10:8080/?a=1 file://192.168.1.1:8090/file mailto:majy@corp.com username:password@g.cn 运行结果:
192.168.1.1 ['192.168.1.1']
mp3.com ['mp3.com'] http:www.g.cn ['www.g.cn'] http:\www.g.cn ['www.g.cn'] http:\/\www.g.cn ['www.g.cn'] admin:@www.g.cn ['www.g.cn'] http://10.10.10.10:8080/?a=1 ['10.10.10.10:8080'] file://test11.com:8090/file ['test11.com:8090'] mailto:majy@corp.com ['corp.com'] username:password@g.cn ['g.cn'] 这只是个初步的版本,如果有BUG欢迎大家指正。
结束语
以前只顾着闷着头的写代码,忽略了事后的思考和总结。现在尝试着改变一下,一边工作,一边提炼和总结,遇到感觉不错的,尝试写成工具开源出来,与大家共勉。
代码传送门:
https://github.com/skskevin/UrlDetect/blob/master/tool/domainExtract/domainExtract.py
*本文作者:littlegrass,转自FreeBuf