
Python黑客工具简述
- 前言
- 准备
- requests介绍
- bs4简单介绍
- python爬西刺代理
- python爬站长之家写一个信息搜集器
- python进行各类API的使用
- python写一个md5解密器
- python调用shodan API
- 额外篇:python dns查询与DNS传输漏洞查询
- 好书推荐
前言
Python工具小脚本,希望给学习python安全新手带来一些福音。
准备
环境:windows python版本:python3.7
所用到的库:requests,bs4,optparse
安装requests:pip install requests
安装bs4:pip install bs4
requests介绍
相比urllib等模块,requests与一些爬虫框架。比urllib等模块 使用起来简便许多。
requests中文文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
bs4模块介绍
bs4是一个爬虫框架,我们只需要用到 bs4里面的一些函数就行了。
中文文档:http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
四件套 — python爬西刺代理
import requests import re import dauk from bs4 import BeautifulSoup import time def daili(): print('[+]极速爬取代理IP,默认为99页') for b in range(1,99):
url="http://www.xicidaili.com/nt/{}".format(b)
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:58.0) Gecko/20100101 Firefox/48.0'}
r=requests.get(url,headers=header)
gsx=BeautifulSoup(r.content,'html.parser') for line in gsx.find_all('td'):
sf=line.get_text()
dailix=re.findall('(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)',str(sf)) for g in dailix:
po=".".join(g)
print(po) with open ('采集到的IP.txt','a') as l:
l.write(po+'\n')
daili() def dailigaoni(): print('[+]极速爬取代理IP,默认为99页') for i in range(1,99):
url="http://www.xicidaili.com/nn/{}".format(i)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1 Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header)
bks=r.content
luk=re.findall('(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)',str(bks)) for g in luk:
vks=".".join(g)
print(vks) with open('采集到的IP.txt','a') as b:
b.write(vks+'\n')
dailigaoni() def dailihtp(): print('[+]极速爬取代理IP,默认为99页') for x in range(1,99):
header="{'User-Agent':'Mozilla/5.0 (Windows NT 6.1 Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}" url="http://www.xicidaili.com/wn/{}".format(x)
r=requests.get(url,headers=header)
gs=r.content
bs=re.findall('(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)',gs) for kl in bs:
kgf=".".join(kl)
print(kgf) with open ('采集到的IP.txt','a') as h:
h.write(kgf)
dailihtp() def dailihttps(): print('[+]极速爬代理IP,默认为99页') for s in range(1,99):
url="http://www.xicidaili.com/wt/{}".format(s)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1 Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header)
kl=r.content
lox=re.findall('(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)',kl) for lk in lox:
los=".".join(lk)
print(los) with open('采集到的IP.txt','a') as lp:
lp.write(los)
dailihttps()
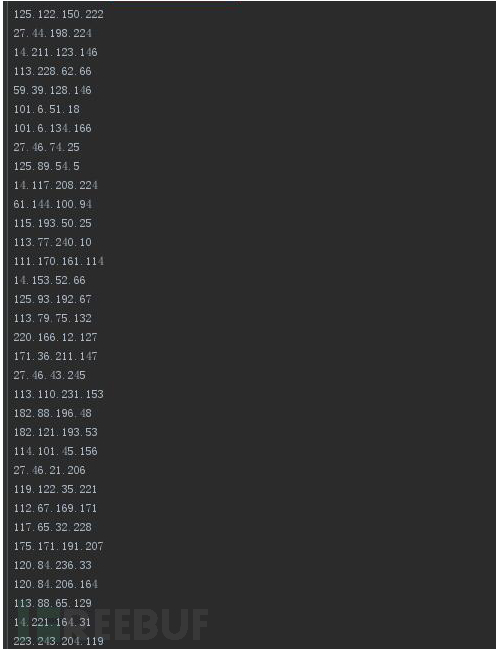
运行效果图:
五件套 — python爬站长之家写一个信息搜集器
import optparse import requests import re import sys from bs4 import BeautifulSoup def main(): usage="[-z Subdomain mining]" \ "[-p Side of the station inquiries]" \ "[-x http status query]" parser=optparse.OptionParser(usage)
parser.add_option('-z',dest="Subdomain",help="Subdomain mining")
parser.add_option('-p',dest='Side',help='Side of the station inquiries')
parser.add_option('-x',dest='http',help='http status query')
(options,args)=parser.parse_args() if options.Subdomain:
subdomain=options.Subdomain
Subdomain(subdomain) elif options.Side:
side=options.Side
Side(side) elif options.http:
http=options.http
Http(http) else:
parser.print_help()
sys.exit() def Subdomain(subdomain): print('-----------Subdomains quickly tap-----------')
url="http://m.tool.chinaz.com/subdomain/?domain={}".format(subdomain)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header).content
g = re.finditer('<td>\D[a-zA-Z0-9][-a-zA-Z0-9]{0,62}\D(\.[a-zA-Z0-9]\D[-a-zA-Z0-9]{0,62})+\.?</td>', str(r)) for x in g:
lik="".join(str(x))
opg=BeautifulSoup(lik,'html.parser') for link in opg.find_all('td'):
lops=link.get_text()
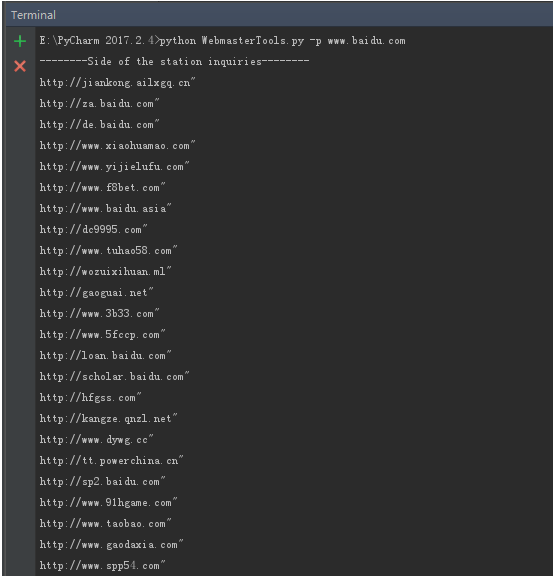
print(lops) def Side(side): print('--------Side of the station inquiries--------')
url="http://m.tool.chinaz.com/same/?s={}".format(side)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header).content
g=r.decode('utf-8')
ksd=re.finditer('<a href=.*?>[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?</a>',str(g)) for l in ksd:
ops="".join(str(l))
pods=BeautifulSoup(ops,'html.parser') for xsd in pods.find_all('a'):
sde=re.findall('[a-zA-z]+://[^\s]*',str(xsd))
low="".join(sde)
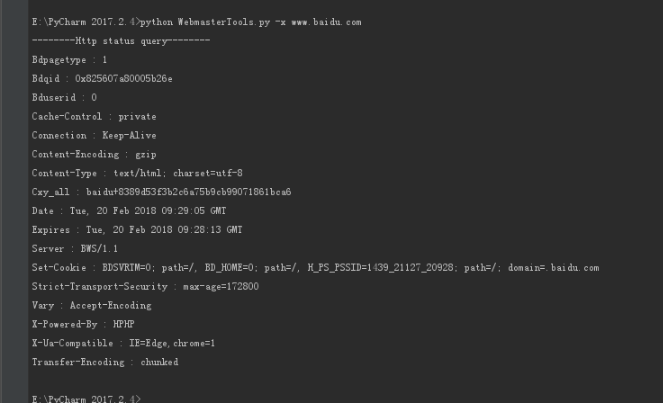
print(low) def Http(http): print('--------Http status query--------')
url="http://{}".format(http)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header)
b=r.headers for sdw in b:
print(sdw,':',b[sdw]) if __name__ == '__main__':
main()
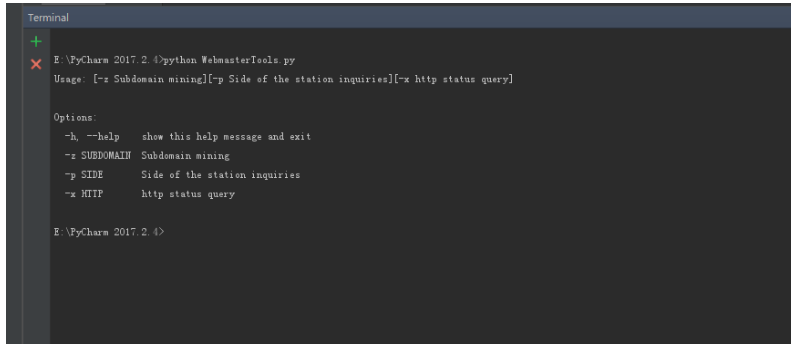
运行截图:
-h 帮助
-z 子域名挖掘
-p 旁站查询
-x http状态查询
-z 截图

-p 截图
-x
六件套 — python进行各类API的使用
这里的json的水比较深,在此我推荐一个 json优化网站:https://www.bejson.com/ API网站:http://www.avatardata.cn
import requests import optparse import json def main(): usage='usage:[-i IP query]' \ ' [-m National wifi lat]' \ ' [-l National wifi lon]' \ ' [-x Daily News]' \ ' [-t Info querry]' parser=optparse.OptionParser(usage)
parser.add_option('-i',dest='ip',help='ip to query')
parser.add_option('-m',dest='wifi',help='National wifi lat')
parser.add_option('-l',dest='wifilon',help='National wifi lon')
parser.add_option('-x',action='store_true',dest='Daily',help='Daily News')
parser.add_option('-t',dest='info',help='info to query')
(options,args)=parser.parse_args() if options.ip:
ipquery=options.ip
Ipquery(ipquery) elif options.wifi and options.wifilon:
wifi=options.wifi
wifilon=options.wifilon
Wifi(wifi,wifilon) elif options.Daily:
Daily() elif options.info:
info=options.info
Info(info) else:
parser.print_help()
exit() def Ipquery(ipquery): url="http://api.avatardata.cn/IpLookUp/LookUp?key=6a4c1df4ba10453da7ee1d50165bfd08&ip={}".format(ipquery)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header)
sdw=r.content.decode('utf-8')
lks=json.loads(sdw)
print('[*]ip',ipquery)
print('[*]area:',lks['result']['area'])
print('[*]location:',lks['result']['location']) def Wifi(wifi,wifilon): url = "http://api.avatardata.cn/Wifi/QueryByRegion?key=你的key&lon={}&lat={}&r=3000&type=1".format(wifi,wifilon)
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r = requests.get(url, headers=header)
sds = r.json()
poswe = sds['result']['data'][0:] for k in poswe:
print("名字:", k['name'], "详细位置:", k['intro'], "地址:", k['address'], "纬度:", k['google_lat'], "经度:",k['google_lon'], "城市:", k['city']) def Daily(): url = "http://api.avatardata.cn/TouTiao/Query?key=你的key&type=top" header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r = requests.get(url, headers=header)
sds = r.json()
poswe = sds['result']['data'][0:] for k in poswe:
print("标题:", k['title'], "日期:", k['date'], "网站来源:", k['author_name'], "新闻url:", k['url']) def Info(info): url = "http://api.avatardata.cn/Weather/Query?key=你的key={}".format(info)
header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r = requests.get(url, headers=header)
sds = r.json()
print('-------------今天天气-----------------')
print("风度:", sds['result']['realtime']['wind']['direct'], "风力:", sds['result']['realtime']['wind']['power'])
print("天气:", sds['result']['realtime']['weather']['info'], "温度:",
sds['result']['realtime']['weather']['temperature'])
print("时间:", sds['result']['realtime']['date'], "地点:", sds['result']['realtime']['city_name'], "农历:",
sds['result']['realtime']['moon'])
print("空调:", sds['result']['life']['info']['kongtiao'], "运动:", sds['result']['life']['info']['yundong'])
print("紫外线:", sds['result']['life']['info']['ziwaixian'], "感冒:", sds['result']['life']['info']['ganmao'])
print('洗车:', sds['result']['life']['info']['xiche'], "污染:", sds['result']['life']['info']['wuran'])
print('穿衣:', sds['result']['life']['info']['chuanyi'])
print('---------------未来几天-----------------')
lijs = sds['result']['weather'][0:] for b in lijs:
print("日期:", b['date'], "星期几:", b['week'], "农历:", b['nongli'], "早上天气:", b['info']['dawn'], "中午天气:",
b['info']['day'], "晚上天气:", b['info']['night']) if __name__ == '__main__':
main()
一共实现了4个参数
-i截图 IP查询
-m和-l 截图 全国免费wifi查询
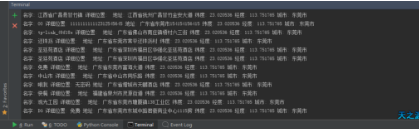
-x截图 新闻
-t截图 天气预告

七件套 — python写一个md5解密器
之前一直想写md5解密器,然而找不到 对应的接口。这次不用接口了,直接用burp 抓包然后改参数得了。。 md5:pmd5.com
设置好代理
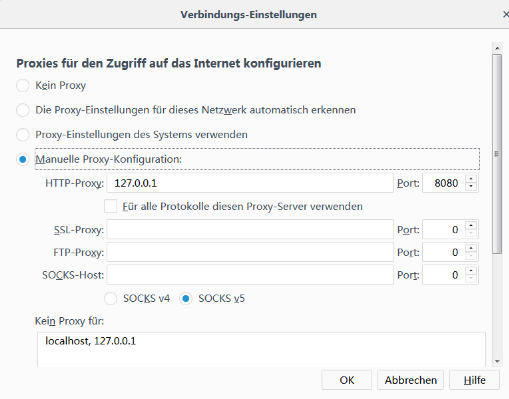
开启burpsuite
开启抓包
随便输个md5,点提交
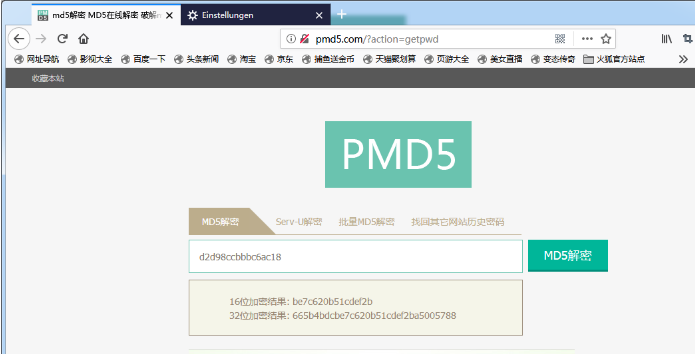
我们可以在burp上见到抓的包
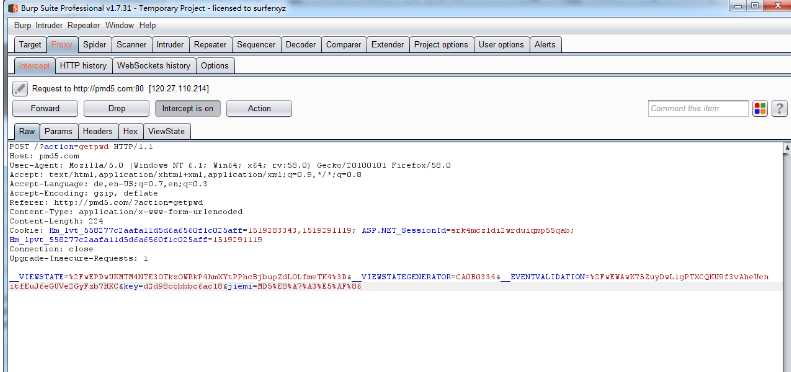
在burp中我们可以看到,数据是被url加密了的,我们去将数据解密
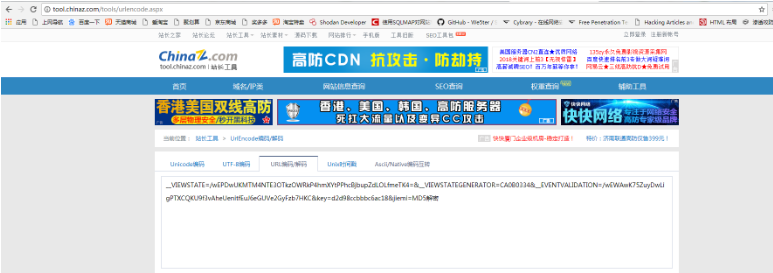
然后将解密的数据转换为字典

然后编写代码:
import requests from bs4 import BeautifulSoup import optparse def main(): usage="[-m md5 decryption]" parser=optparse.OptionParser(usage)
parser.add_option('-m',dest='md5',help='md5 decryption')
(options,args)=parser.parse_args() if options.md5:
md5=options.md5
Md5(md5) else:
parser.print_help()
exit() def Md5(md5): header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
data = { '__VIEWSTATE': '/wEPDwUKMTM4NTE3OTkzOWRkP4hmXYtPPhcBjbupZdLOLfmeTK4=', '__VIEWSTATEGENERATOR': 'CA0B0334', '__EVENTVALIDATION': '/wEWAwK75ZuyDwLigPTXCQKU9f3vAheUenitfEuJ6eGUVe2GyFzb7HKC', 'key': '{}'.format(md5), 'jiemi': 'MD5解密' }
url = "http://pmd5.com/" r = requests.post(url, headers=header, data=data)
sd = r.content.decode('utf-8')
esdf = BeautifulSoup(sd, 'html.parser') for l in esdf.find_all('em'):
g = l.get_text()
print('--------[*]PMD5接口--------')
print(g) if __name__ == '__main__':
main()
八件套 — python调用shodan API
shodan介绍:
shodan是互联网上最可怕的搜索引擎。 CNNMoney的一篇文章写道,虽然目前人们都认为谷歌是最强劲的搜索引擎,但Shodan才是互联网上最可怕的搜索引擎。 与谷歌不同的是,Shodan不是在网上搜索网址,而是直接进入互联网的背后通道。Shodan可以说是一款“黑暗”谷歌,一刻不停的在寻找着所有和互联网关联的服务器、摄像头、打印机、路由器等等。每个月Shodan都会在大约5亿个服务器上日夜不停地搜集信息。 Shodan所搜集到的信息是极其惊人的。凡是链接到互联网的红绿灯、安全摄像头、家庭自动化设备以及加热系统等等都会被轻易的搜索到。Shodan的使用者曾发现过一个水上公园的控制系统,一个加油站,甚至一个酒店的葡萄酒冷却器。而网站的研究者也曾使用Shodan定位到了核电站的指挥和控制系统及一个粒子回旋加速器。
Shodan真正值得注意的能力就是能找到几乎所有和互联网相关联的东西。而Shodan真正的可怕之处就是这些设备几乎都没有安装安全防御措施,其可以随意进入。
Rapid 7 的首席安全官HD Moore,表示:你可以用一个默认密码登陆几乎一半的互联网。就安全而言,这是一个巨大的失误。 如果你搜索“默认密码”的话,你会发现无数的打印机,服务器及系统的用户名都是“admin”,密码全都是“1234”。还有很多系统根本不需要认证,你所需要做的就是用浏览器进行链接。所以如果你在使用默认密码的话,请现在就改换新的密码。 如果Shodan落入坏人之手的话,那真是一个可怕的东西。 而更大的问题是很多设备根本不需要链接到互联网。
很多公司常常会买一些他们能够控制的系统,比如说一个电脑控制的热力系统。而他们又是如何把热力系统链接到网上的呢?为什么不直接控制呢?很多IT部门就直接把这些系统插入到网络服务器上,殊不知,这样就和世界分享这些系统了。 Shodan的研发者Matherly表示,这些链接到网上的设备根本没有安全防御措施,他们根本就不应该出现在互联网上。 而好消息就是Shodan几乎都是用在了好的方面。
Matherly对搜索数量也进行了限制。比如没有账户的用户最多提供10个搜索结果,而有账户的用户则可以享受50个搜索结果。如果你想要Shodan提供的所有信息,那Matherly会就你所要搜索的内容,要求你提供更多的信息且付费。 同时,Matherly也承认坏蛋会使用Shodan,但到目前为止,大多数网络攻击都集中在窃取财物和知识产权上。坏蛋们还没有试图摧毁一栋大楼或毁坏市内的红绿灯。 安全防御措施的专业人士们都不希望使用Shodan时搜索到这些没有防御措施的设备及系统。但同时,互联网上有太多可怕的东西,那些没有防御措施的设备只能等着被攻击。
引用百度百科
shodan文档:http://shodan.readthedocs.io/en/latest/tutorial.html
shodan:https://www.shodan.io/
key的获取方法:请自己上shodan官网进行注册获取key
代码:
import optparse import shodan import requests def main(): usage='[usage: -j Type what you want]' \ ' [-i IP to search]' \ ' [-s Todays camera equipment]' parser=optparse.OptionParser(usage)
parser.add_option('-j',dest='jost',help='Type what you want')
parser.add_option('-i',dest='host',help='IP to search')
parser.add_option('-s',action='store_true',dest='query',help='Todays camera equipment')
(options,args)=parser.parse_args() if options.jost:
jost=options.jost
Jost(jost) elif options.host:
host=options.host
Host(host) elif options.query:
query() else:
parser.print_help()
exit() def Jost(jost): SHODAN_API_KEY='ZmgQ9FZf1rnRuR0MLhT5SXw0xBE8LDLc' api=shodan.Shodan(SHODAN_API_KEY) try:
result=api.search('{}'.format(jost))
print('[*]Results found:{}'.format(result['total'])) for x in result['matches']:
print('IP{}'.format(x['ip_str']))
print(x['data']) with open('shodan.txt','a') as p:
p.write(x['ip_str']+'\n')
p.write(x['data']+'\n') except shodan.APIError as e:
print('[-]Error:',e) def Host(host): SHODAN_API_KEY='ZmgQ9FZf1rnRuR0MLhT5SXw0xBE8LDLc' try:
api=shodan.Shodan(SHODAN_API_KEY)
hx=api.host('{}'.format(host))
print("IP:{}".format(hx['ip_str']))
print('Organization:{}'.format(hx.get('org','n/a')))
print('Operating System:{}'.format(hx.get('os','n/a'))) for item in hx['data']:
print("Port:{}".format(hx['port']))
print('Banner:{}'.format(hx['data'])) except shodan.APIError as g:
print('[-]Error:',g) def query(): header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url = "https://api.shodan.io/shodan/query?key=ZmgQ9FZf1rnRuR0MLhT5SXw0xBE8LDLc" r = requests.get(url, headers=header)
sd = r.json()
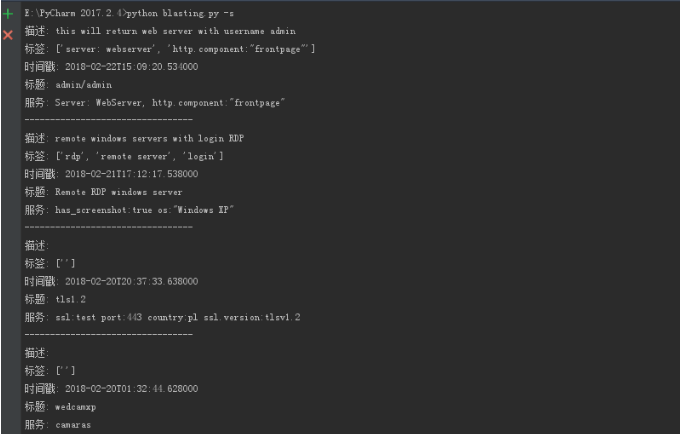
sg = sd['matches'][0:] for b in sg:
print("描述:", b['description'])
print('标签:', b['tags'])
print('时间戳:', b['timestamp'])
print('标题:', b['title'])
print('服务:', b['query'])
print('---------------------------------') if __name__ == '__main__':
main()
这个脚本实现了3个参数
-j shodan里面搜索
-i 搜索IP
-s 搜索弱口令摄像头
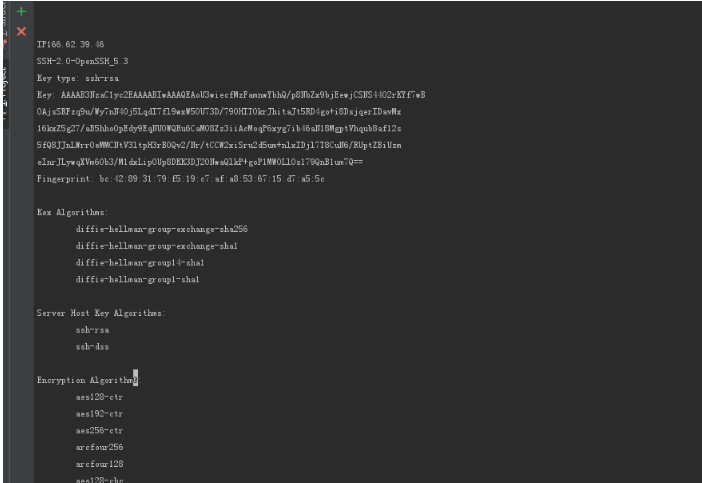
-j 搜有ssh服务的主机,并写入到shodan.txt
-i IP搜索 没目标- -

-s 弱口令摄像头查询
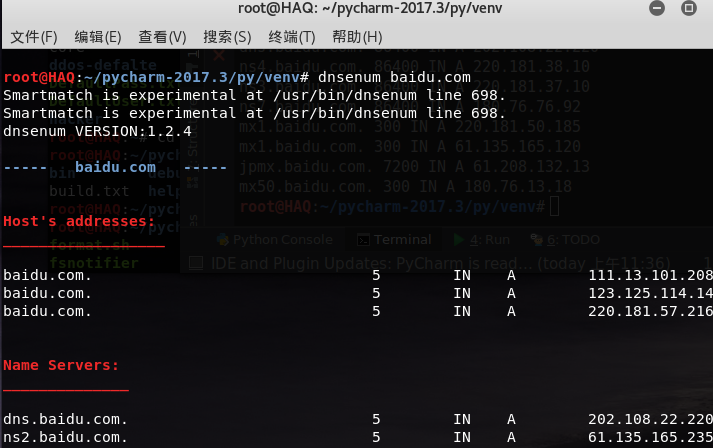
九件套 — python dns查询与DNS传输漏洞查询
DNS传输漏洞介绍:
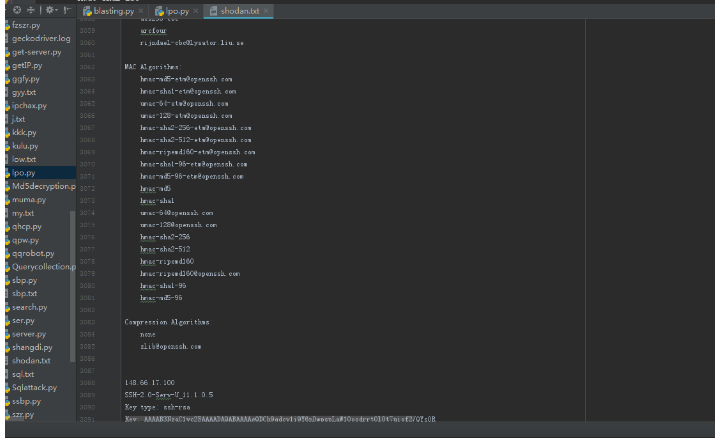
—– baidu.com —–
Host’s addresses:
baidu.com. 5 IN A 111.13.101.208
baidu.com. 5 IN A 123.125.114.144
baidu.com. 5 IN A 220.181.57.216
Name Servers:
dns.baidu.com. 5 IN A 202.108.22.220
ns2.baidu.com. 5 IN A 61.135.165.235
ns3.baidu.com. 5 IN A 220.181.37.10
ns4.baidu.com. 5 IN A 220.181.38.10
ns7.baidu.com. 5 IN A 180.76.76.92
Mail (MX) Servers:
jpmx.baidu.com. 5 IN A 61.208.132.13
mx50.baidu.com. 5 IN A 180.76.13.18
mx.maillb.baidu.com. 5 IN A 220.181.3.85
mx.n.shifen.com. 5 IN A 220.181.3.85
mx1.baidu.com. 5 IN A 61.135.165.120
mx1.baidu.com. 5 IN A 220.181.50.185
安装dnsknife模块 [!]widnows下会报错所以我在Linux下写的。
环境是py2 pip install dnsknife
或者去https://pypi.python.org/pypi/dnsknife/0.11下载该包 然后 python steup.py install 编写代码:
from dnsknife.scanner import Scanner import dnsknife import optparse import sys def main(): usage="[-i Fast query] " \ "[-d DNS domain transmission vulnerability detection]" parser=optparse.OptionParser(usage)
parser.add_option('-i',dest='Fastquery',help='Quickly check some dns records')
parser.add_option('-d',dest='detection',help='Detects possible DNS transmission vulnerabilities')
(options,parser)=parser.parse_args() if options.Fastquery :
Fastquery=options.Fastquery
query(Fastquery) elif options.detection :
detection=options.detection
vulnerability(detection) else:
sys.exit() def query(Fastquery): print '--------mx record--------' try:
dns=dnsknife.Checker(Fastquery).mx() for x in dns: print x except Exception , c: print '[-]wrong reason:',c print '--------txt record--------' try:
dnstxt=dnsknife.Checker(Fastquery).txt() print dnstxt except Exception , g: print '[-]wrong reason:',g try: print '--------spf record------' dnsspf=dnsknife.Checker(Fastquery).spf() print dnsspf except Exception , l: print '[-]wrong reason:',l def vulnerability(detection): print '--------DNS transmission vulnerability detection-----------' try:
dnschuan=Scanner(detection).scan() for list in dnschuan: print list except Exception , p: print '[-]Wrong reason:',p if __name__ == '__main__':
main()
运行结果
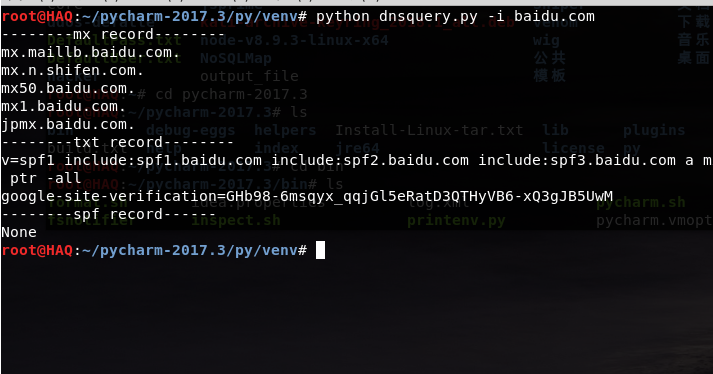
www.baidu.com. 1200 IN CNAME www.a.shifen.com.
mail.baidu.com. 7200 IN CNAME
autodiscover.baidu.com. 600 IN CNAME
email.maillb.baidu.com. test.baidu.com. 7200 IN CNAME
testatmp.n.shifen.com.support.baidu.com. 7200 IN CNAME
pheonest.e.shifen.com. baidu.com. 600 IN A 123.125.114.144
baidu.com. 600 IN A 220.181.57.216
baidu.com. 600 IN A 111.13.101.208
baidu.com. 86400 IN NS ns4.baidu.com.
baidu.com. 86400 IN NS ns2.baidu.com.
baidu.com. 86400 IN NS ns7.baidu.com.
baidu.com. 86400 IN NS ns3.baidu.com.
baidu.com. 86400 IN NS dns.baidu.com.
baidu.com. 7200 IN MX 20 jpmx.baidu.com.
baidu.com. 7200 IN MX 20 mx50.baidu.com.
baidu.com. 7200 IN MX 10 mx.maillb.
baidu.com. baidu.com. 7200 IN MX 15 mx.n.shifen.com.
baidu.com. 7200 IN MX 20 mx1.baidu.com.
baidu.com. 7200 IN TXT “google-site-verification=GHb98-6msqyx_qqjGl5eRatD3QTHyVB6-xQ3gJB5UwM”
baidu.com. 7200 IN TXT “v=spf1 include:spf1.baidu.com include:spf2.baidu.com include:spf3.baidu.com a mx ptr -all”
forum.baidu.com. 7200 IN A 10.26.109.19
git.baidu.com. 7200 IN A 10.42.4.104
admin.baidu.com. 7200 IN A 10.26.109.19
ns4.baidu.com. 86400 IN A 220.181.38.10
ns2.baidu.com. 86400 IN A 61.135.165.235
ns7.baidu.com. 86400 IN A 180.76.76.92
ns3.baidu.com. 86400 IN A 220.181.37.10
dns.baidu.com. 86400 IN A 202.108.22.220
jpmx.baidu.com. 7200 IN A 61.208.132.13
mx50.baidu.com. 300 IN A 180.76.13.18
mx1.baidu.com. 300 IN A 61.135.165.120
mx1.baidu.com. 300 IN A 220.181.50.185
结尾:好书推荐
python:python绝技,python黑帽子,python网络数据采集,python网络编程
安全方面:黑客攻防技术宝典:web篇,黑客攻防技术宝典:浏览器实战篇
网络方面:思科网络技术学院教程(上)(下)