
注:本文下面的内容仅讨论绕过思路,作为技术交流之用。大家下载论文还是应该通过正规渠道,付费下载,尊重各位站长的劳动成果。敏感图片和代码中涉及站点的内容均已打码。
有时候要研究技术,我们也需要下载一些论文来看看的。一些论文站点,虽然提供预览功能,但是下载却是收费的。
举个例子,如下站点:
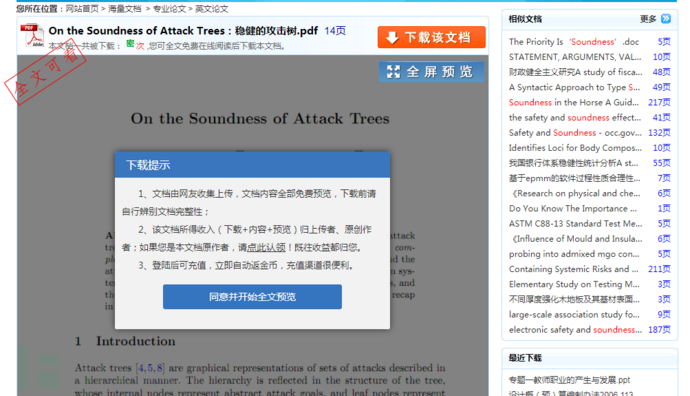
当我们点击“同意并开始全文预览”按钮时,是有一个弹出窗口来预览论文的。

但是当我们点击“下载”按钮时,却提示需要收费。

一方面它单篇论文的收费实在是挺贵的;另外一方面,我们可能更倾向于把论文批量下载到本地,等到有时间时慢慢读完。这该怎么办呢?
我们F12看看预览页面的内容:

可以清晰的看到,id=”pdf”的div下的每个子节点div对应着论文的每一页,而每一个子div中包含的img标签对应的图片则是每一页的内容。我们将img标签的src中的链接复制出来,粘贴在浏览器的新页签中,其实是可以看到本页论文内容,而右键“保存图片”是可以将此页论文保存到本地的。

以上就是手动绕过限制下载论文的思路。但是有的论文页数实在太多,手动逐个复制链接下载实在有些效率低下,所以我们可以写个脚本来提升效率。
#coding:utf-8 import traceback
import urllib2
import urllib
import sys
import Queue
import os
import time
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Firefox()
driver.implicitly_wait(30)
host = "此处打码" searchurl = "https://" + host + "/index.php?m=Search&a=index" dstpath = "h:/downloadpdf" download_queue = Queue.Queue()
reload(sys)
sys.setdefaultencoding("utf-8") class UnicodeStreamFilter: def __init__(self, target):
self.target = target
self.encoding = 'utf-8'
self.errors = 'replace'
self.encode_to = self.target.encoding
def write(self, s):
if type(s) == str:
s = s.decode("utf-8")
s = s.encode(self.encode_to, self.errors).decode(self.encode_to)
self.target.write(s)
if sys.stdout.encoding == 'cp936':
sys.stdout = UnicodeStreamFilter(sys.stdout) def get_search_result(keywords): data = {"q":keywords}
headers = {"cookie":"访问论文站点时f12看到的cookie填入此处,此处打码"}
req = urllib2.Request(url=searchurl,data=urllib.urlencode(data),headers=headers)
res = urllib2.urlopen(req)
content = res.read()
soup = BeautifulSoup(content, features="lxml")
divlist = soup.find_all(class_="item-title")
if divlist is not None and len(divlist) > 0: for divitem in divlist: alist = divitem.find_all("a")
if alist is not None and len(alist) > 0: ahref = alist[0].attrs["href"]
title = alist[0].attrs["title"]
download_queue.put([
"http://%s%s"%(host,ahref,),
title
]) def save_pdf(title, imgls, chost): headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "__cfduid=dd7361d04f439dbfd27d12f286b72afdb1520244765; Hm_lvt_5d91dc9c92e499ab00ba867fc2294136=1520385180",
"Upgrade-Insecure-Requests": 1,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146
Safari/537.36" }
if not os.path.exists(dstpath): os.mkdir(dstpath)
curdst = dstpath + os.sep + str(title).replace(".pdf","").decode()
if not os.path.exists(curdst): os.mkdir(curdst)
pageindex = -1 for imgitem in imgls: if imgitem.attrs["src"].find("loading") != -1: continue
src = imgitem.attrs["src"]
src = "http://%s/%s"%(chost,src[3:],) pageindex = pageindex + 1 realpath = curdst + os.sep + str(pageindex) + ".png" with open(realpath, "wb") as f: req = urllib2.Request(url=src,headers=headers)
f.write(urllib2.urlopen(req).read())
f.flush()
print "下载",title,"完成" else: print curdst,"已存在" def download_pages(): while not download_queue.empty(): url,title = download_queue.get()
html = urllib.urlopen(url).read()
signal = "javascript:viewLogin.viewDl('" if html.find(signal) != -1: cid = html[html.find(signal) + len(signal):]
cid = cid[:cid.find("'")]
pagerequest_url = "http://%s/index.php?g=Home&m=View&a=viewUrl&cid=%s&flag=1"%(host,cid,) pagereal_url = urllib.urlopen(pagerequest_url).read()
chost = pagereal_url[2:].split("/")[0]
pagereal_url = "http:%s"%(pagereal_url,) driver.get(pagereal_url)
try: time.sleep(3)
#每次移动滚动条的距离 distance = 300 #统计img标签的个数,下拉时会新增img标签 pimgnum = 0 #img标签个数不再发生变化的次数 samecount = 0 while True: driver.execute_script('$("#pdf").scrollTop(%s);'%distance)
time.sleep(2)
distance = distance + 300 cimgnum = len(driver.find_elements_by_tag_name("img"))
if cimgnum != pimgnum: pimgnum = cimgnum
samecount = 0 continue
else: samecount = samecount + 1 #当img标签不再发生变化的次数达到20次时,则表明全部加载完毕 if samecount >= 20: break
pagecontent = driver.page_source
soup = BeautifulSoup(pagecontent, features="lxml")
imgls = soup.find_all("img")
if imgls is not None and len(imgls) > 0: save_pdf(title, imgls, chost)
except Exception,e: traceback.print_exc() if __name__ == '__main__': keywords = "攻击树" get_search_result(keywords)
download_pages()
driver.quit() 脚本主要步骤如下:
1.根据传入的关键字(keyword字段),模拟搜索请求;得到与该关键字相关的论文的标题以及url
2.打开论文对应的url,此时的页面还不是真实的论文全文页面;定位到预览关键字段cid(在javascript:viewLogin.viewDl()方法中),发送请求,得到论文真实全文页面的对应的url
3.由于论文预览采用了逐步加载的模式,即最初显示3页,然后随着滚动条的拖动再逐渐加载后续内容;所以使用selelium模拟滚动页面内容,判断是否有新页面被加载出来,直至页面内容不再发生变化为止
4.此时基于第三部加载出的全部页面内容,提取img字段,逐个保存到本地;即对应着论文的每一页
脚本运行效果如下:

得到的论文:
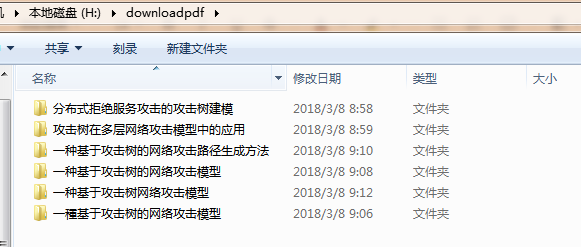

如果网络效果不是很好,可以适当将sleep时间延长。跑个脚本吃个饭回来,论文都下好了,还是很爽的。
* 本文作者:tammypi