
在php的逻辑漏洞中,有很大一部分trick跟编码转换机制有关(典型的如宽字节注入),其中除了受到php本身的编码函数如iconv、mb_convert_encoding等影响之外,很多payload源于mysql内部的编码转换机制。这篇文章主要从实例角度出发,以图说话,深入mysql编码转换机制。
0×01 准备知识
常见编码
ascii
编码范围:00-7F
超过7F的属于其他字符集,所以你看到所有的字符trick的首字节,必定在80-FF
latin
编码范围:00-FFmysql默认字符集,可以把其他所有字符集的序列都看成latin1
gbk
编码范围:8140-FEFE第一字节81-FE第二字节40-FE
UTF-8
编码范围:
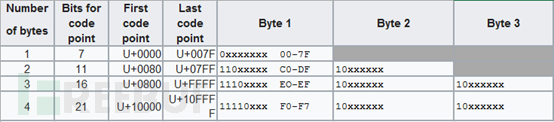
每种编码也可能存在自身的限制,比如GBK 在某些情况下第二字节不能为7F
UTF-8,某些首字节编码不允许出现等等,这些特例就不在这介绍了,如果在实际操作中如果遇到特别奇怪的现象,一般就是有一些特殊限制或者编码实现的bug
准备代码
仅针对windows环境,linux环境会有部分差异
MYSQL表
create table shadow4u( id int auto_increment not null, name varchar(50),
shadow varchar(50),
primary key (id)
)default charset=utf8; PHP代码
<?php $a=$_GET['a'];
var_dump(bin2hex($a));
$sql="insert intoshadow4u(name,shadow) values('$a','zzz')";
$conn=mysql_connect("localhost","root","shadow4u");
$result=mysql_query('show variables like"char%"') or die(mysql_error()); echo"---------------------<br/>"; while($row=mysql_fetch_array($result))
echo$row[0].' : '.$row[1]."<br/>";
mysql_query('set names gbk'); echo"---------------------<br/>";
$result=mysql_query('show variables like"char%"') or die(mysql_error()); while($row=mysql_fetch_array($result))
echo$row[0].' : '.$row[1]."<br/>";
mysql_select_db("test",$conn);
mysql_query($sql,$conn) ordie(mysql_error()); ?>
0×02 MYSQL字符集
在mysql命令行下输入命令
show variables like ‘char%’ 即可看到相应的字符集的设置情况
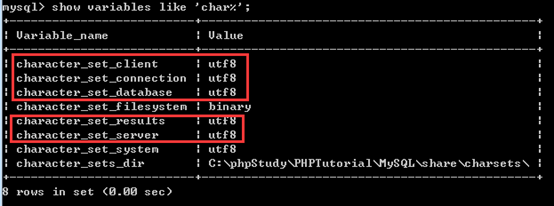
我们重点关注红框中的部分
| 客户端相关 | |
|---|---|
| character_set_client | 客户端数据来源使用的字符集 |
| character_set_connection | 连接层使用的字符集 |
| character_set_results | 查询结果字符集 |
| 服务端相关 | |
|---|---|
| character_set_server | 默认的内部操作字符集(字符集) |
| character_set_database | 当前选中数据库的默认字符集 |
在执行SQL语句之前,一般先通过setnames xx设置客户端相关的字符集
相当于
set character_set_client=xx
set character_set_connection=xx
set character_set_results=xx
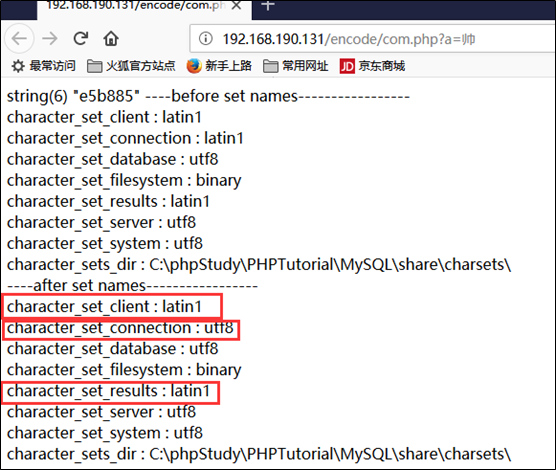
客户端的字符集跟具体的客户端有关,不同的客户端连接的字符集不一样,mysql命令行的client connection results对PHP连接mysql相应的值没有任何参考价值。对同一个数据库的连接,mysql命令行显示客户端连接相关字符集都是utf8,而php连接mysql的字符集如下图
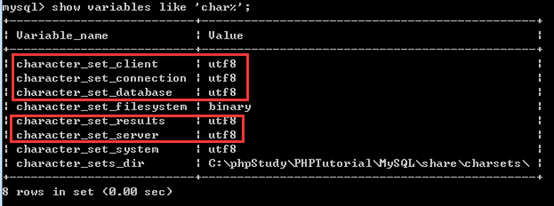
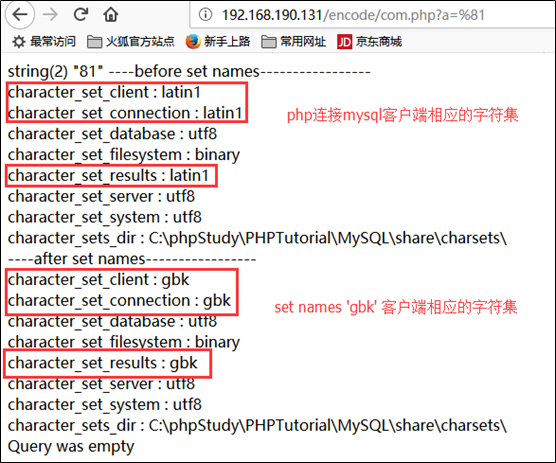
访问php页面,可以看到在set names之前默认客户端相关的编码都是latin1,
所以,不要和mysql命令行中敲下命令showvariables like ‘char%’显示的字符集和php代码中连接mysql的字符集混为一谈。
设置set names gbk之后,可以看到相应的三个字段的值被设置为gbk
在继续研究之前,请一定理解不同的客户端连接数据库的字符集是有可能不同的,所以一般都会setnames 确保字符集被设置为需要的值。
字符集编码转换顺序
那么整个字符集的编码转换顺序是怎样的
一般来说

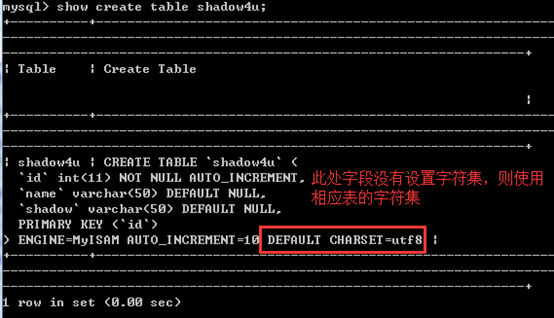
这个所谓内部操作字符集是啥呢,依次是字段、表、库、Server相应的字符集
一般来说,使用命令show create table xx即可,如果字段没有设置,则使用相应的表default charset值,一般来说表都会有default值为latin1,如果没有,则使用上面提到的character_set_database,如果db也没设置,则使用character_set_server
字段的字符集通过charcter set xx即可设置
0×03 admin%81=admin的原因
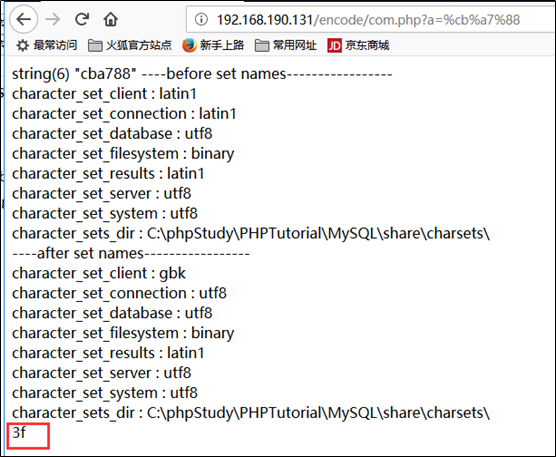
以上表设置utf8为例,注意是set names utf8,这是个坑,如果写成utf-8,mysql不识别
<?php $a=$_GET['a'];
var_dump(bin2hex($a));
$sql="insert intoshadow4u(name,shadow) values('$a','zzz')";
$conn=mysql_connect("localhost","root","shadow4u");
$result=mysql_query('show variables like"char%"') or die(mysql_error()); echo "----before setnames-----------------<br/>"; while($row=mysql_fetch_array($result))
echo$row[0].' : '.$row[1]."<br/>";
mysql_query('set names utf8'); echo "----after setnames-----------------<br/>";
$result=mysql_query('show variables like"char%"') or die(mysql_error()); while($row=mysql_fetch_array($result))
echo$row[0].' : '.$row[1]."<br/>";
mysql_select_db("test",$conn);
$result=mysql_query($sql,$conn) ordie(mysql_error());所以转换顺序为
utf8=>utf8=>utf8
字符集设置都是一样,一般情况下将不会产生错误
以我们的输入为例
http://192.168.190.131/encode/com.php?a=%81
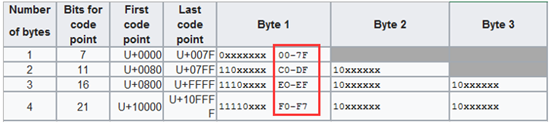
还记得上面的编码范围吗
UTF-8
编码范围:
我们试着插入一个合法的utf-8字符

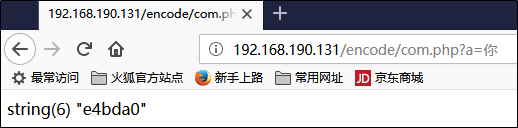
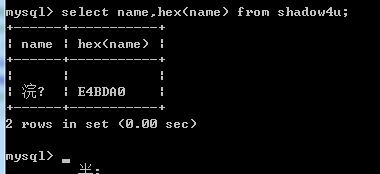
可以看到,正确插入了数据库
然后,我们在”你”字的后面插入%81

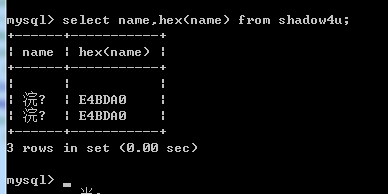
可以看到%81被忽略
然后我们试着在”你”字的前面插入81
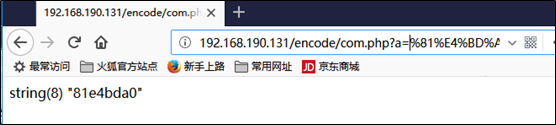
可以看到后面的字符被截断
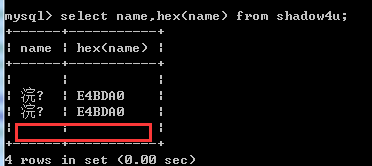
这里就涉及到Mysql的一个特性,无效的编码将被截断
比如转码顺序utf-8 utf-8 utf-8,如果输入不是一个有效utf-8字符,将在client转换的时候直接被截断
无效的概念有两个,一个是编码根本不在这个范围,比如首字节为81,根本不在UTF-8编码后的首字节范围,另一个就是不完整,比如”你”的编码是e4bda0,我们只输入e4bd,可以看到插入的还为空
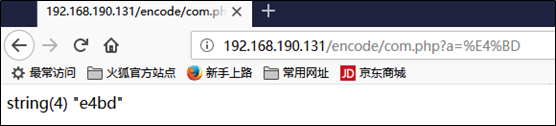

所以这里就涉及到php中常见的一个逻辑漏洞
$name=$_GET['name'];
select * from shadow4u where name=’$name’中
输入admin%81和admin查询的结果是一样的
实际上php代码本身并没有问题,而mysql在编码转换过程中出现的问题。
类比php编码转换函数
这一点有点类似于php中iconv
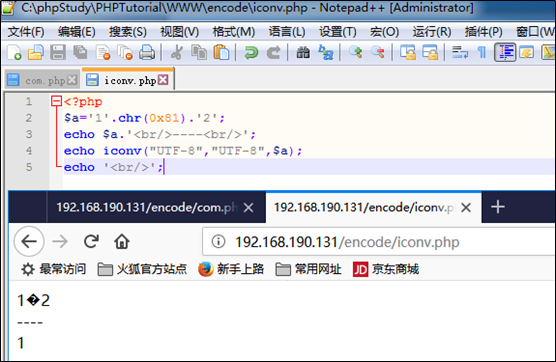
<?php $a='1'.chr(0x81).'2'; echo $a.'<br/>----<br/>';
echoiconv("UTF-8","UTF-8",$a); echo '<br/>';
阶段总结
1.先对字符集总结一下,mysql在编码转换的过程中会将无效的编码kill掉
2.客户端的编码设置一般通过setnames xxx一般表的默认字符集可以通过show create tables xxx来查看,实际上mysql编码转换的过程只和上述两个操作看到的字符集有关系
0×04 宽字符注入的秘密
<?php $a=$_GET['a'];
var_dump(bin2hex($a)); $a=addslashes($a); $sql="select*fromshadow4uwherename='$a'"; $conn=mysql_connect("localhost","root","shadow4u");
mysql_query('setnamesgbk');
mysql_select_db("test",$conn); $result=mysql_query($sql,$conn)ordie(mysql_error()); while($row=mysql_fetch_array($result)) echo$row[0].''.$row[1]."<br/>";上面代码大意:
为了防止SQL注入,先addslashes,然后再select * from shadow4u where name=’$a’
只不过有一句mysql_query(‘set names gbk’);
我们输入a=%81%27

“乗”字的编码是%81%5c

所以addslashes之后,$a值变为%81\’,但是%81\组成了”乗”,单引号被独立出来,于是完成了注入
输入a=%81%27 union select 1,user(),3%23
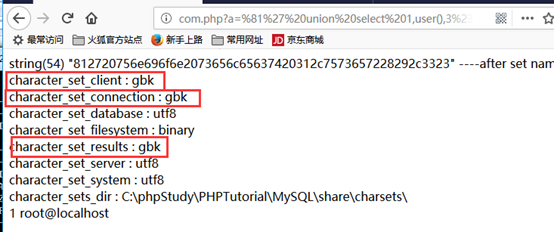
决定性的character_set_client
宽字符型注入决定性作用的是实际上是character_set_client,一般习惯性用set names xxx来设置
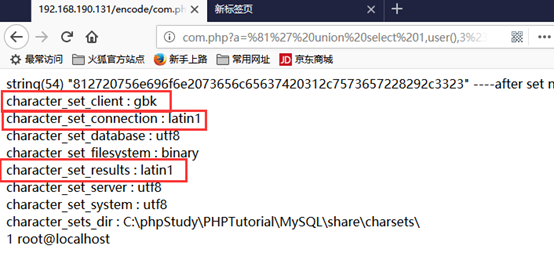
比如,我们只设置character_set_client=gbk,
mysql_query(‘set character_set_client=gbk’);
照样可以完成注入
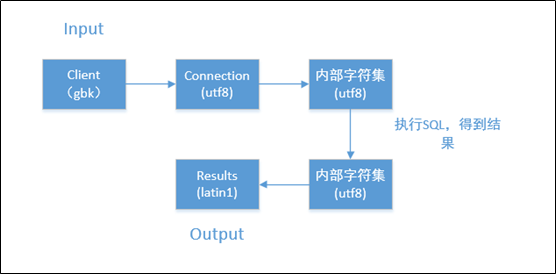
0×05 整个编码转换的过程
最后,我们来完成一个完整的mysql编码转换过程
这里的设置
mysql_query(‘set character_set_client=gbk,character_set_connection=utf8,character_set_results=latin1′);
当然弄清楚整个编码过程后,可以随便玩,比如更改表字段的编码类型等
”帅”的gbk编码为\xcb\xa7
我们输入帅+88

输入为%cb%a7%88
其中cba7通过gbk=>utf8e5b885
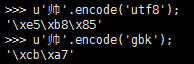
单独的88属于不完整的gbk编码,也就是无效编码,截断,所以只会存入e5b885
查看insert到表中的数据

utf8-latin
因为latin只支持\u00-\uFF的编码,”帅”的unicode编码为\u5e05
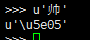
latin1不识别,所以转换成为3f
再来一个latin1-utf8-latin1
比如输入latin
a=%e5%b8%85
1 latin-utf8
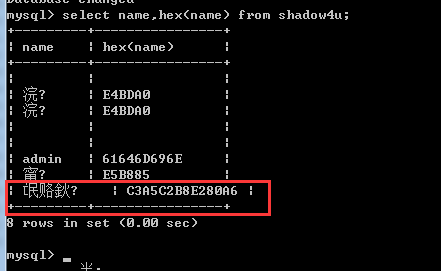

结果不是应该为c3a5 c2b8 c285吗
最后不应该是c285么,怎么变成了e280a6
我们直接将表转换为latin1,看看什么效果
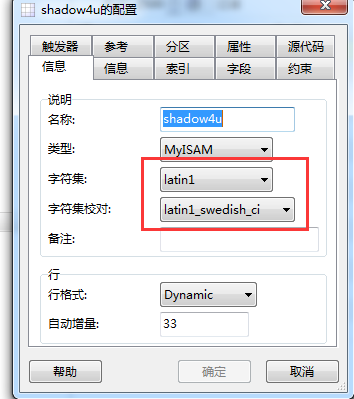

utf-8转latin1还真是85,这是什么鬼?其实这就是mysql实现的方式。每种编码规则只是一个规则,真正的表现取决于实现,编码中还可能存在一些特殊情况,如果大部分操作都跟你的预想一样,但是有一些操作却跟你的预想不一样的时候,很可能就是编码存在特殊情形
2 utf8-latin1的结果显示

0×06 总结
1 mysql编码转换的顺序为:
client-connection-内部字符集-results (内部字符集的值可以一般通过show create table 表名来进行查看)

2 mysql编码过程中无效编码将被截断,后面的内容将被抛弃
3 宽字符注入过程中,起决定性作用的实际上是character_set_client
mysql如果设置了character_set_client=gbk或者set names gbk,然后如果通过addslashes对单引号’进行转义,则可以通过注入%81%27,由于单引号%27被转义,整个注入字符串被改为%81%5c%27,这个时候由于mysql认为客户端编码是gbk,%81%5c被组合成汉字乗,从而成功注入一个单引号

*本文作者:shadow4u