
前言
Base64 算法可能是大家接触最多的算法吧,Base64 指定了一个编码表,方便统一转换,大家在逆向中是否遇到似是而非的base64 编码啊?比如 ”aHVsbH8=” 这种貌似是 base64,但解码后是 “hull” 。但是我告诉你解码错误,正确答案是 “hello”。因为我给 base64Table 替换了。遇到这种情况,就要寻找编码表,此时如果 Base64 被代码虚拟化了,怎么办?
第一章 Base64原理
Base64 编码要求把 3 个 8 位字节(3*8=24)转化为 4 个 6 位的字节(4*6=24),之后在 6 位的前面补两个 0 ,形成 8 位一个字节的形式。 如果剩下的字符不足 3 个字节,则用 0 填充,输出字符使用 ‘=’,因此编码后输出的文本末尾可能会出现 1 或 2 个 ‘=’。
为了保证所输出的编码位可读字符,Base64 制定了一个编码表,以便进行统一转换。编码表的大小为 2^6=64,这也是 Base64 名称的由来。
Base64 编码表
| 码值 | 字符 | 码值 | 字符 | 码值 | 字符 | 码值 | 字符 |
|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w |
| 1 | B | 17 | R | 33 | h | 49 | x |
| 2 | C | 18 | S | 34 | i | 50 | y |
| 3 | D | 19 | T | 35 | j | 51 | z |
| 4 | E | 20 | U | 36 | k | 52 | 0 |
| 5 | F | 21 | V | 37 | l | 53 | 1 |
| 6 | G | 22 | W | 38 | m | 54 | 2 |
| 7 | H | 23 | X | 39 | n | 55 | 3 |
| 8 | I | 24 | Y | 40 | o | 56 | 4 |
| 9 | J | 25 | Z | 41 | p | 57 | 5 |
| 10 | K | 26 | a | 42 | q | 58 | 6 |
| 11 | L | 27 | b | 43 | r | 59 | 7 |
| 12 | M | 28 | c | 44 | s | 60 | 8 |
| 13 | N | 29 | d | 45 | t | 61 | 9 |
| 14 | O | 30 | e | 46 | u | 62 | + |
| 15 | P | 31 | f | 47 | v | 63 | / |
第二章 替换 Base64 编码表
const char * base64Table = "BADCFEHGIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; char * base64_encode(const unsigned char * bindata, char * base64, int binlength) { int i, j; unsigned char current; for (i = 0, j = 0; i < binlength; i += 3)
{
current = (bindata[i] >> 2);
current &= (unsigned char)0x3F;
base64[j++] = base64Table[(int)current];
current = ((unsigned char)(bindata[i] << 4)) & ((unsigned char)0x30); if (i + 1 >= binlength)
{
base64[j++] = base64Table[(int)current];
base64[j++] = '=';
base64[j++] = '='; break;
}
current |= ((unsigned char)(bindata[i + 1] >> 4)) & ((unsigned char)0x0F);
base64[j++] = base64Table[(int)current];
current = ((unsigned char)(bindata[i + 1] << 2)) & ((unsigned char)0x3C); if (i + 2 >= binlength)
{
base64[j++] = base64Table[(int)current];
base64[j++] = '='; break;
}
current |= ((unsigned char)(bindata[i + 2] >> 6)) & ((unsigned char)0x03);
base64[j++] = base64Table[(int)current];
current = ((unsigned char)bindata[i + 2]) & ((unsigned char)0x3F);
base64[j++] = base64Table[(int)current];
}
base64[j] = '\0'; return base64;
}base64Table 已经被我替换了,
BADCFEHGIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/不再是默认的
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/此时用这个改良后的base64对信息进行加解密,当然关键地方vmp一下,防止别人找到base64Table。
第三章 分析原理
看下图

我们知道 3 字节 base64 加密后是 4 字节 base64 编码。如果我们要推出 base64 编码表只需要让查表的索引从 0-64 走一遍,我们就可以得到编码表。
编码表一共有 64 字节,那么我们就可以计算出编码前的字节数 (64*6)/8=48
也就是说如果我用 48 字节进行 base64 编码,编码后的长度肯定是 64 字节,
48 字节我们分三位一组,一共循环 16 组就 ok 了,
根据上图 我们要让查表索引为 0,1,2,3,…..63 的话
也就是让0,1,2,3 四个字节转换成三个字节,就 ok
现在来拼凑第一个字节
//0x=(i * 4) <<2;(对应上图数字0 把他左移2位)
y = (i * 4 + 1) >> 4;(对应上图 数字1 右边移动四位,剩下2位,)
BaseTable[z * 3] = x+y;一个字节8位,数字0占了6为,我们再从数字1中移出2位,正好拼凑第一个字节
拼凑第二个字节
//1x=((i * 4+1)&0xf)<<4; (对应上图数字1的后四位)
y = (i * 4 + 2) >> 2; (对应上图数字2的前四位)
BaseTable[z * 3 + 1] = x+y; 一个字节8位,取数字1的后四位和数字2的前四位,正好是第二个字节
拼凑第三个字节
//2x= ((i * 4 + 2)&3)<<6 ;(对应上图数字2的后二位)
y = (i * 4 + 3);(对应上图数字3 全部获取6位)
BaseTable[z * 3 + 2] = x+y; 一个字节 8 位,取数字 2 的后二位和数字3的6位,正好是第三个字节
第三章 代码实现
int x = 0; int y = 0; unsigned char BaseTable[65] = { 0 }; int z = 0; for (size_t i = 0; i < 16; i++)
{ //每四个为一个单元 //0 x=(i * 4) <<2;
y = (i * 4 + 1) >> 4;
BaseTable[z * 3] = x+y; //1 x=((i * 4+1)&0xf)<<4;
y = (i * 4 + 2) >> 2;
BaseTable[z * 3 + 1] = x+y; //2 x= ((i * 4 + 2)&3)<<6 ;
y = (i * 4 + 3);
BaseTable[z * 3 + 2] = x+y;
z++;
}测试一下效果
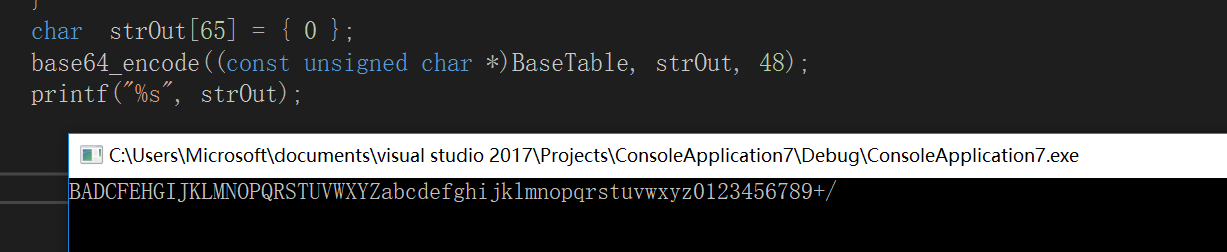
拿到 base64Table 后我们就可以对数据进行编码解码了
* 本文作者:刀郎