
前言
几天前,我在FreeTalk北京站演讲了《数据清洗在网络安全中的应用》,由于时间关系,很多内容并没有讲到,会议结束后很多人也私信问我很多问题。其实在这个信息大爆炸的时代,数据清洗可以应用在众多的领域,包括但不限于农业,军事产业,信息安全产业,工业,旅游业,金融行业,房地产业等等。在会议上我展示的两个模型只是非常基础的两个数据处理模型,我司还有很多极其复杂的模型并没有展示。
先举一个例子,就拿社工库来说,可能很多人的理解就是把互联网泄露的信息索引进去并且进行搜索就完了,真是天真。社工库的鼻祖应该是DIS系统,全称为Distributed Interactive Simulation System,是美国国防高级研究计划局早期的项目之一,DIS系统具有互操作性(Interoperability)、可伸缩性(Scalability)和仿真的时空一致性(Time-Space Coherence)等三大特性。
例子
这里说一个我碰到的真实例子,警方已经确定有两个犯罪人员小A和小B,目前只知道小A的真实信息,另外一人完全不知道,如果强行逮捕小A,那么可能会让另外一个犯罪分子逃脱。这个两个人在网络上没有任何的交流,没有相互加过QQ,微信等,甚至连电话号码也没有留过,全部都采用加密软件交流,而且也不在一起搭乘交通工具。但是最后警方还是通过DIS系统成功找到了小B。虽然他们线上线下都很谨慎,但是警方发现,有有个人的QQ号经常和小A的QQ号出现在一个网吧,成功逮捕了两名犯罪人员。这里DIS系统发挥主要功能就是仿真的时空一致性,而要完成这个功能需要非常稳定的数据关联。
目前中国大量的DIS系统主要是采用redis这种内存数据库来进行检索和数据处理,因此需要极高的内存配置,并且无法进行多人同时查询。据了解,中国某个部门的DIS系统需要125GB的内存才能运行。但是,如果提前就将数据进行清洗,把具有关联的数据进行输出和入库。那么查询的时候不会再回到内存中做数据清洗,而是直接从数据库中检索,这样可以节约大量的系统资源,并且可以多人同时查询。
字典清洗模型制作
不聊家常了,接下来先进入正题。几年前猪猪侠在Wooyun发布了一个全国弱口令TOP 100,而我打算发一个全国弱口令Top 1000。
以下为源数据截图,里面的数据非常杂乱,保护MD5加密密码,中文用户名,空密码,空用户名等。
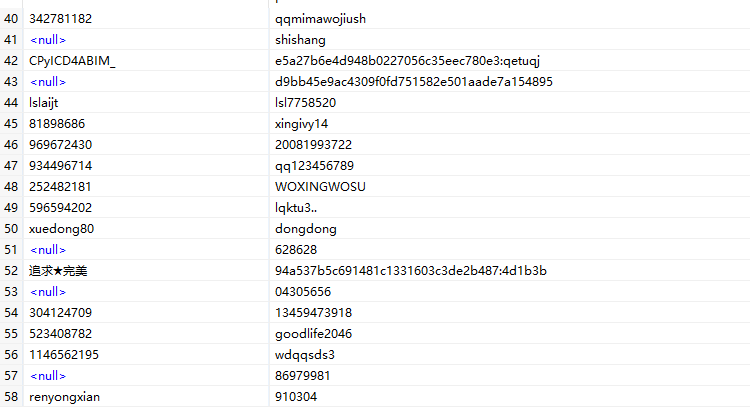
首要任务是先在Kettle Spoon上将源数据进行输入。在Spoon是我使用的模块是文本文件输入。
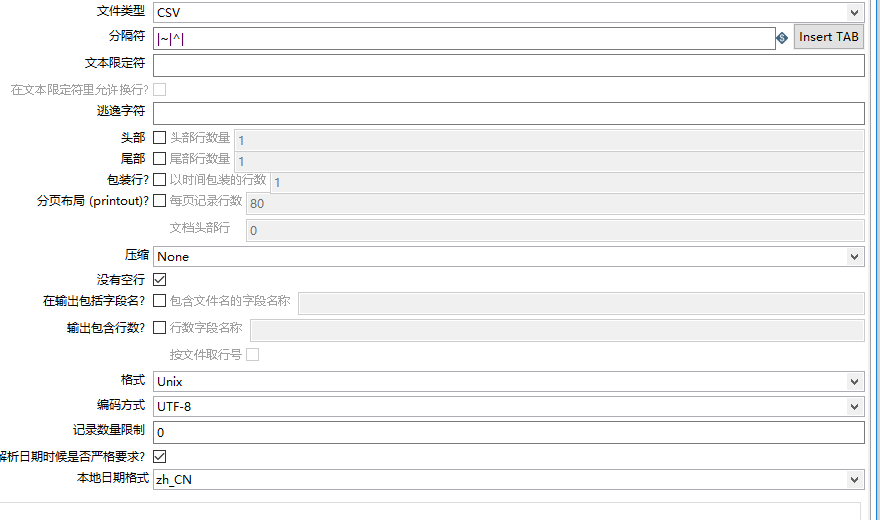
我要制作全国弱口令Top 1000,那么首要任务是对数据中的password进行排序。这里使用的模块是排序记录模块。排序的真正作用是为了分组模块能够对数据进行正确,使用分组模块前一定要先对数据进行排序。
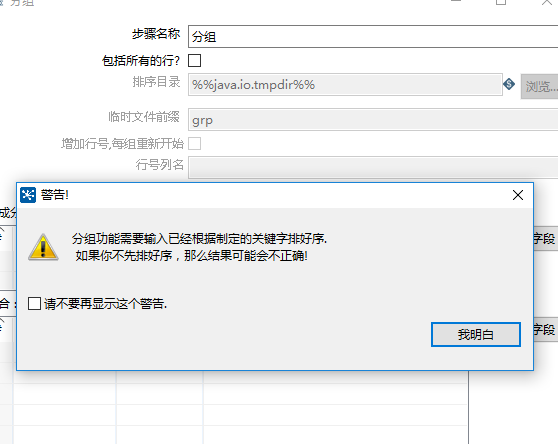
在分组模块中,我新建了一个SumNumber字段,目的是为了对password字段中内容的出现次数进行计算。
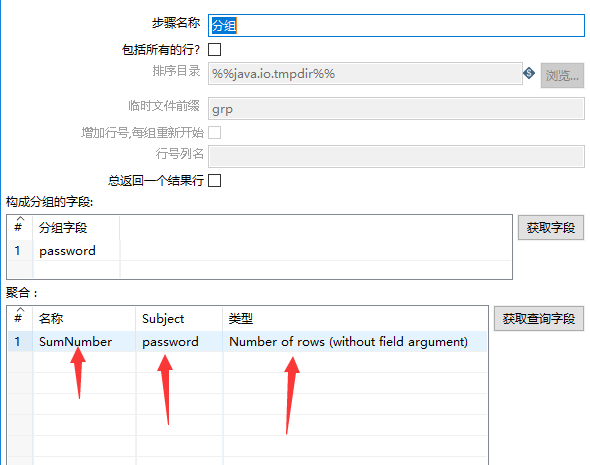
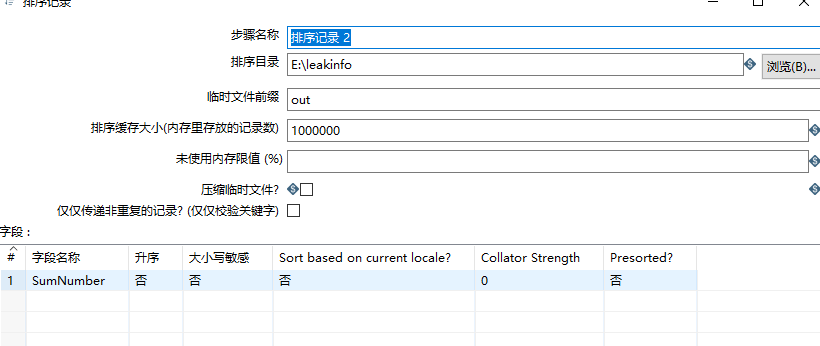
随后再对Sumnumber字段进行排序,目的是为了能够直观的了解到密码出现次数的一个排名。
因为源数据中出现了MD5值,空值等,所以我们还要对数据再进行二次清洗。这里我采用了Java代码模块,自己写了一段java将大于16位数的密码,小于3位数的密码和空密码给过滤了。并且将过滤后得到的密码赋值给passwordnew1字段。
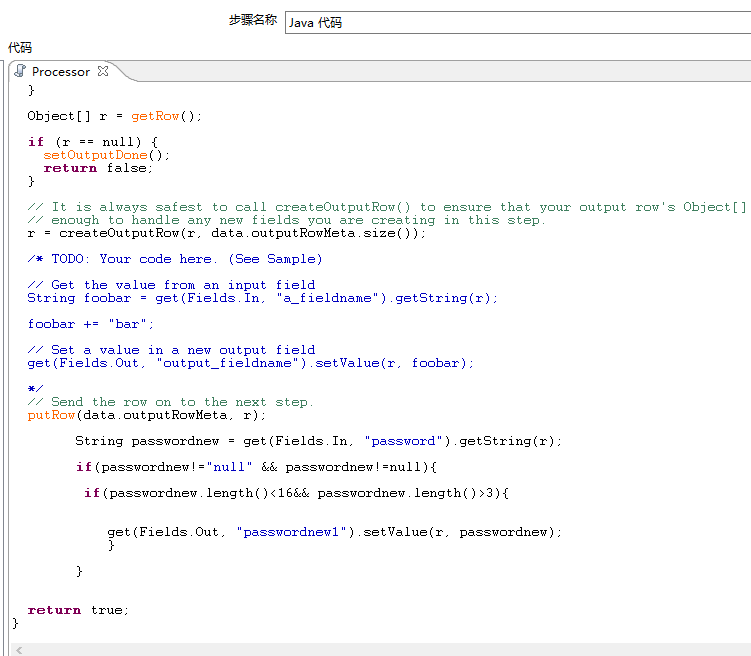
因为以上过滤后的密码将会以NULL来替换,所以又写了一个过滤规则将NULL密码给过滤了。

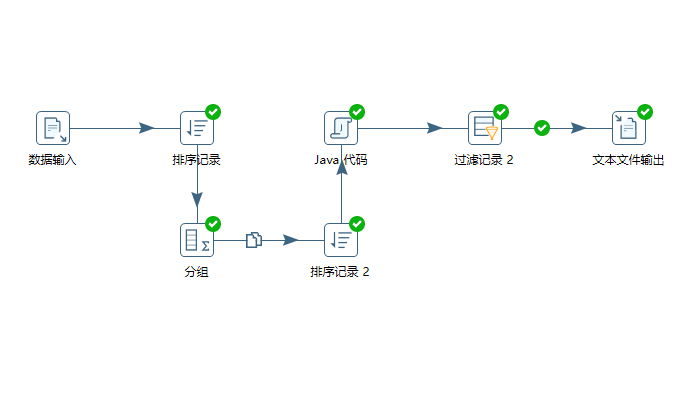
最后再将全部清洗好的数据用输出模块输出到指定的目录下。以下是整个模型的概览。
下面是清洗好的数据,左边是密码,右边是密码出现的次数。
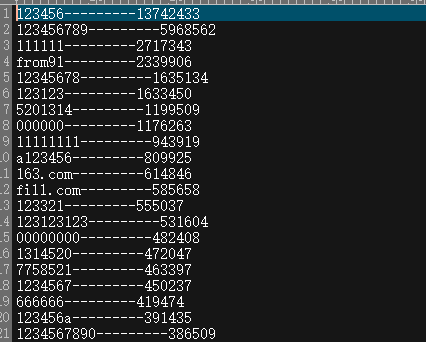
因为数据采集的时候是互联网上的泄露数据,有些数据无法确定真伪,数据采集的不规范导致了部分结果存在错误,比如fill.com这个密码不应该排名那么靠前,还有就是from91是个什么鬼。。。。。。。不过勉强还是能够让大家用用。
下面是传送门:
链接:http://pan.baidu.com/s/1c2go9l2 密码:9rxw
总结
除了FreeTalk展示的那个模型以外,我们还制作了针对财务,天气,畜牧业,种植业等相关的数据模型。如果你从事信息安全行业,数据清洗这个技能将会给你事半功倍的效果。Kettle Spoon采用图形化窗口操作,非常便捷,其中内置了大量数据清洗模块。要学习Kettle,单纯看文章教程还是非常难懂,建议大家最好实际操作一遍。如果有哪里不懂的欢迎在评论区留言。
这里只提供了前1000的弱口令集合。如果哪家单位需要完整的弱口令数据做风控或者相关研究的,可以私信我司(非个人外,我司免费无条件分享这批格式化数据)
* 本文作者:耿浩然@水熊科技(企业帐号)