
xss在近几年的ctf形式中,越来越受到了人们的重视,但是出xss的题目最重要的可能就是xss bot的问题了,一个合格的xss bot要稳定还能避免搅屎。下面我们就来看看一个xss bot是怎么完成的。
bot之前
一般来说,对于xss bot来说,最重要的是要bot能够执行js,事情的本质是我们需要一个浏览器内核来解析js,这里我们一般会用selenium+webdriver。
而webdriver一般有3种chrome webdriver、firefox webdriver、phantomjs。
selenium
selenium是用来控制webdriver的接口的,网上搜到的大部分脚本大部门都是java控制的,下面我的所有脚本都使用python操作selenium,下面有份不太完整的文档。
http://www.seleniumhq.org/docs/03_webdriver.jsp)
只要在python文件前引入selenium模块。
import selenium from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.common.exceptions import WebDriverException chrome webdriver
如果我们想要使用chrome webdriver,除了安装chrome浏览器本身,还需要安装webdriver。
https://sites.google.com/a/chromium.org/chromedriver/downloads)
由于webdriver版本众多,api和语法也有所不同,这里推荐最新版chrome+最新版webdriver。
因为环境相异,所以我们可能需要在脚本里设置chrome webdriver的路径
#!/usr/bin/env python # -*- coding:utf-8 -*- import selenium from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.common.exceptions import WebDriverException import os
chromedriver = "C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chromedriver.exe" os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver)
url = "[http://xxxx](http://xxxx)" browser.get(url)
browser.quit() firefox webdriver
firefox和chrome相同,需要一个geckodriver来支持,和chrome类似。
https://github.com/mozilla/geckodriver/releases/)
在linux下,需要添加映射到/bin/
chmod +x geckodriver 在windows下,需要添加geckodriver到环境变量中。
#!/usr/bin/env python # -*- coding:utf-8 -*- import selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import WebDriverException
browser = webdriver.Firefox()
url = "[http://xxxx](http://xxxx)"
browser.get(url)
browser.quit() phantomjs
phantomjs和别的浏览器本质上没什么区别,差不多也是类似于浏览器的内核,优势其实是多平台支持,而且不需要浏览器支持,所以一般爬虫用的比较多。
下载地址
http://phantomjs.org/download.html)
#!/usr/bin/env python # -*- coding:utf-8 -*- import selenium
from selenium import webdriver
from selenium.common.exceptions import WebDriverException
phantomjs_path = "sssssssss/phantomjs"
driver = webdriver.PhantomJS(executable_path=phantomjs_path)
url = "[http://xxxx](http://xxxx)"
browser.get(url)
browser.quit() bot的背后
比起爬虫来不一样,因为一个爬虫只要打开一次获取数据就好了,但是作为xss bot必须周期性的打开页面,执行攻击者的相应payload,既然bot的持续时间一般是24小时-48小时,那bot就不可能时时刻刻都有人盯着,也就必须放在服务器上,我们来研究一下不同的webdriver在服务器的差异。
chrome和firefox的webdriver都有一个特点,就是需要桌面,如果执行脚本的服务器上不包含桌面,那么我就需要别的方法来构造一个虚拟的桌面。
如果在windows服务器上,windows服务器最大的特点就是自带桌面,我们一般通过rdp管理,所以windows服务器上跑xss bot的话不需要做专门的处理。
如果在linux服务器上,我们一般通过ssh管理linux服务器,那么我就需要一段神秘代码来执行xss bot脚本,这是一段火日聚聚教我的代码。
from pyvirtualdisplay import Display
display = Display(visible=0, size=(800,800))
display.start() 在phantomjs的webdriver下,就不会有这样的问题,因为phantomjs本身就是多平台的,只是很多时候xss bot需要保证浏览器的特性,这种时候,我们往往不会使用phantomjs作为xss bot的首选。
完成bot
上面我们着重讲了各种webdriver,下面我就来针对不同的xss题目来谈谈。
report bug型xss
一般来说,xss题目最常见的就是report bug或者是留言型xss,后台接口唯一,攻击者向目标发送信息,bot需要访问页面执行js。
在ctf比赛中,处理方式五花八门,这里我推荐1种解决办法。
在攻击者页面提供测试接口和攻击接口,然后攻击者接口设置验证码,避免攻击者无意义的刷payload。(具体可以见0ctf的处理方式)
为了避免干扰,最好将攻击者攻击数据存入数据库,添加标志位以判断数据是否被访问过,题目专门添加功能用作check数据库内是否存在未访问数据(最好添加此功能在题目中,因为bot有可能不在题目服务器,远程数据库连接是个危险的行为!!)
判断存在时,bot开启webdriver访问相应的页面(通过添加cookie或者ip check的方式判断访问来源),相应的页面从数据库取出数据,bot访问完成后关闭。
大致流程如下:
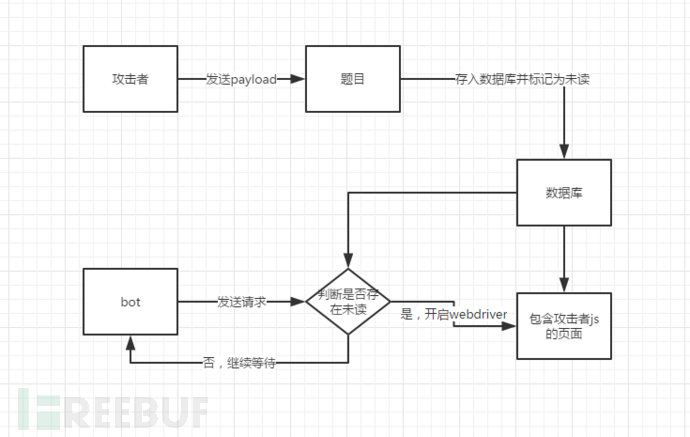
我这里贴上bot部分的代码
#!/usr/bin/env python # -*- coding:utf-8 -*- import selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import WebDriverException
import os
import time import requests
from pyvirtualdisplay import Display
display = Display(visible=0, size=(800,800))
display.start() while 1:
try: s = requests.Session()
url = '[http://xxx/checksql.php](http://xxx/checksql.php)' r = s.get(url) if "存在" in r.text:
try:
chromedriver = "C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chromedriver.exe" os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver)
browser.set_page_load_timeout(10)
browser.set_script_timeout(10)
url = "[http://xxxxxx/admin_321321321.php](http://xxxxxx/admin_321321321.php)" browser.get(url)
browser.add_cookie({'name': 'admin', 'value' : 'arandomstring', 'path' : '/'})
browser.get(url) while 1:
try:
browser.switch_to_alert().accept()
except selenium.common.exceptions.NoAlertPresentException: break print browser.title print time.strftime("%Y-%m-%d %X", time.localtime()) time.sleep(10)
browser.quit() time.sleep(1)
except Exception as e: print "[error] "+str(e)
browser.quit() else: print time.strftime("%Y-%m-%d %X", time.localtime()) print "[info] no unread messages" exit(0)
except Exception as e: print "[error] "+str(e) 上面的代码配合crontab应该可以很好的应付这类xss的各种问题
聊天类的交互式xss
这类xss最明显的特点就是admin用户和别的用户并没有区别,也就是说bot想要打开被攻击者注入的页面,也必须经过登录,服务端设置session来登录,那么上面的办法就行不通了,最好的办法就是模拟登录。
这类xss最大的问题其实就是信息的隔离方式,如果聊天的交互方式本身就是显示在同一页面上的话,很显然的问题就是,如果有一个攻击者试图干扰bot的运行,他只要再每个round发送<xmp>就可以导致js无法执行,这是个我到现在还没想明白的问题。先分享现在我使用的bot
#!/usr/bin/env python # -*- coding:utf-8 -*- import selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import WebDriverException
import os
import time import requests
from pyvirtualdisplay import Display
display = Display(visible=0, size=(800,800))
display.start() for i in xrange(2):
try:
browser = webdriver.Firefox()
browser.set_page_load_timeout(10)
browser.set_script_timeout(10)
url = "[http://52.80.63.91/login.php](http://52.80.63.91/login.php)" browser.get(url)
elem = browser.find_element_by_name("user")
elem.clear()
elem.send_keys('admin')
elem = browser.find_element_by_name("pass")
elem.clear()
elem.send_keys('admmin332indadmin33213')
elem = browser.find_element_by_name("login")
elem.click() print "login success" browser.add_cookie({'name': 'admin', 'value' : 'arandomstring', 'path' : '/adminshigesha233e3333/'}) while 1:
try:
browser.switch_to_alert().accept()
except selenium.common.exceptions.NoAlertPresentException: break print browser.title print time.strftime("%Y-%m-%d %X", time.localtime()) time.sleep(10)
browser.quit() time.sleep(1)
except Exception as e: print "[ERROR] "+str(e) #important browser.quit()
url2 = '[http://xxxx/cl33e3ar5ql.php](http://xxxx/cl33e3ar5ql.php)' r = s.get(url2) print r.text print time.strftime("%Y-%m-%d %X", time.localtime()) 上面的代码通过setkey模拟登录,然后设置后台的cookie,每次payload执行2次,然后清理掉admin除预留信息以外的所有payload,避免恶意payload导致的所有payload无效。
配合crontab可以保证bot的持久性,如果不放心bot的稳定性,还可以在脚本执行结束后,执行命令kill掉所有的firefox残留进程。
到此为止,一个完整的xss bot就完成了,虽然可能不是最完美的解决方案,希望会有更好的解决办法:>
*本文原创作者:LoRexxar