
Webshell一直都是网站管理员痛恨看到的东西,一旦在网站目录里看到了陌生的webshell基本说明网站已经被攻击者拿下了。站在攻击者的角度,要想渗透一台网站服务器,第一个目标也是想方设法的寻找漏洞上传webshell。
对于webshell的防护通常基于两点:一是在攻击者上传和访问时通过特征匹配进行检测拦截或限制文件类型阻止上传;二就是日常基于webshell文件特征的静态查杀(也有基于日志的,在这里不做讨论)。第一种方法不是我们今天要讨论的,waf、安全狗等一系列工具可以实现相应的功能。第二种方式静态查杀,通常会匹配一些关键字、危险函数、一些特征代码及他们的各种加密形式,以遍历文件的方式来进行查杀。然而还有很多种通过破坏遍历规则(使恶意文件无法被遍历到)的隐藏方式,通常可以达到避免被查杀的目的。今天我们要说的就是: 如何利用python实现针对这几种特定隐藏方式的webshell查杀。
0X01 ntfs交换数据流隐藏webshell
NTFS交换数据流(alternate data streams,简称ADS)是NTFS磁盘格式的一个特性,在NTFS文件系统下,每个文件都可以存在多个数据流,就是说除了主文件流之外还可以有许多非主文件流寄宿在主文件流中。它使用资源派生来维持与文件相关的信息,虽然我们无法看到数据流文件,但是它却是真实存在于我们的系统中的。
利用ntfs交换数据流隐藏文件的方式很久以前就出现了,介绍利用这种方式来隐藏webshell的文章也不少。这种隐藏方式主要针对一句话木马,因为如果被包含的文件为大马则失去了隐藏的意义(若被包含的文件为大马,会直接跳转到大马页面,原页面也就相当于被篡改了,很容易就会被发现)。前两天做了个测试,却发现自己手头经常使用的几个webshell查杀工具居然都检测不出来,最好的结果只报了一个可疑文件包含,便考虑自己动手写一写。
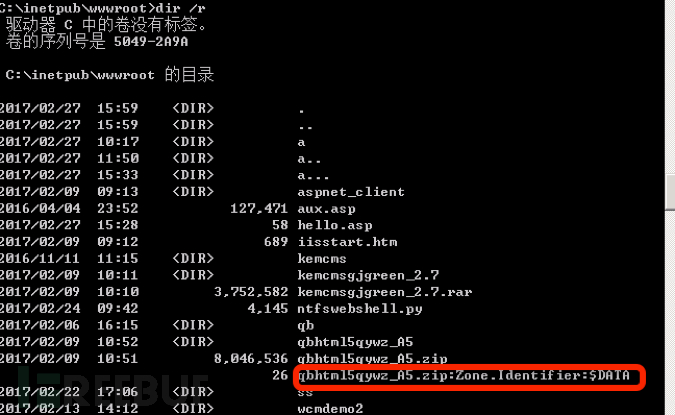
整体逻辑很简单,首先遍历web应用所在的文件夹,找出所有利用ntfs交换数据流隐藏的文件,组成一个list;其次遍历所有.asp文件(以asp为例),找出所有采用了包含头的.asp文件,将其路径作为value,将被包含的文件路径作为key,建立一个dict。与之前的list做对比,若在dict中发现了存在于list中的元素,则断定它为webshell,最后将其路径输出,并同时将包含它的.asp文件路径输出。说白了就是以这个包含了ntfs交换数据流文件的动作来断定它是否为webshell。
使用到的windows命令:dir /r #显示文件的备用数据流
# -*- coding: cp936 -*- import os,os.path import re
def searchNTFS(catalog): #搜索所有ntfs ads文件目录,返回list resultL= []
forroot,dirs,files in os.walk(catalog): #利用os.walk()递归遍历文件 line= '' command = 'cd '+ root + '&' + 'dir /r' r =os.popen(command)
info= r.readlines()
forl in info:
line = line + l
reN= '\s(\S+)\:\$DATA' res= re.findall(reN,line)
forre1 in res:
if re1 != '':
result = root + '\\' + re1
resultL.append(result)
returnresultL
def searchInclude(catalog): resultL= []
resultD= {}
forroot,dirs,files in os.walk(catalog):
forf in files:
dir = os.path.join(root,f)
if dir[-4:] == '.asp':
try :
fp = open(dir,'r')
for line in fp.readlines():
reN = '<\!--#include\S+="(\S+)"-->' res = re.findall(reN,line)
for re1 in res:
if re1 != '':
result = root +'\\' + re1
resultD[result]= root + '\\' +f
except:
print "File :" + dir + " can't be read" returnresultD
if __name__ == "__main__":
reD =searchInclude('C:\inetpub\wwwroot')
reN =list(set(reD.keys()).intersection(set(searchNTFS('C:\inetpub\wwwroot'))))
reI = []
for re1in reN:
reI.append(reD[re1])
if reI!= []:
forre2 in reN :
print '###############################################################' print "[+]Suspicious ADS files found : " + re2
for re3 in reI :
print '###############################################################' print "[+]Including files: " + re3 + " \n Please check it." else :
print "[+]No suspicious ADS files found." 0X02 畸形文件名、保留文件名隐藏webshell
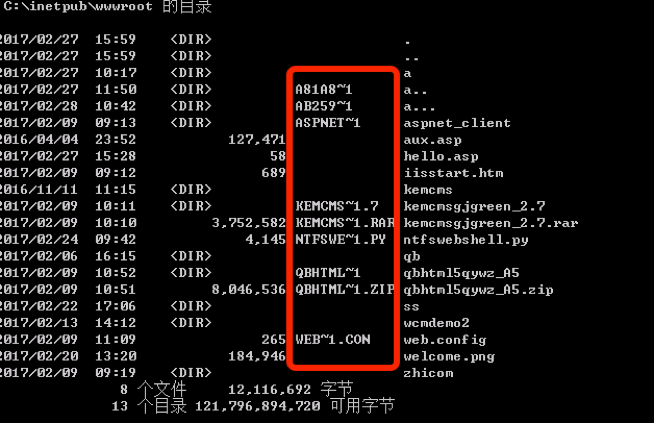
简单科普下,windows的畸形目录名有很多种,通常是指文件名中存在多个.号,例如\a…\,图形界面下无法访问和删除,命令行界面也只能通过windows的短文件名进行访问。
Windows的保留文件名,例如aux、prn、con、nul、com1~9、lpt1~9等等,windows不允许用户以常规方式自行创建,但可以通过copy或者echo等命令加上网络位置\\.\来创建,访问也要在绝对路径前加上\\.\来访问(例如type \\.\C:\inetpub\wwwroot\aux.asp)。
利用的时候可以单种使用也可以一起使用,例如C:\inetpub\wwwroot\a…\aux.asp
我们需要用到命令:dir /x #显示为非 8.3 文件名产生的短名称
# -*- coding: cp936 -*- import os,os.path import re
def searchSFN(catalog): resultL = []
resultL2 = []
for root,dirs,files in os.walk(catalog): #利用os.walk()递归遍历文件 line = '' command = 'cd '+ root + '&' + 'dir/x' r = os.popen(command)
info = r.readlines()
for l in info:
line = line + l
reN1 = '\s+(\S+\~\S+)\s+\S+\.\.+' res = re.findall(reN1,line)
for re1 in res:
if re1 != '':
result = '\\\\.\\' + root + '\\'+ re1
resultL.append(result)
reN2
='\s+((aux|prn|con|nul|com1|com2|com3|com4|com5|com6|com7|com8|com9|lpt1|lpt2|lpt3|lpt4|lpt5|lpt6|lpt7|lpt8|lpt)\.\S+)\s+' res2 = re.findall(reN2,line)
for re2 in res2:
if re2 != '':
result2 = '\\\\.\\' + root +'\\' + re2[0]
resultL2.append(result2)
return resultL,resultL2
defdeleteSFN(list,list2):
for l1 in list :
str = raw_input('Do you want to delete: ' + l1 + '? (y/n)')
if str == 'y' :
command = 'rd /s /q ' + l1
r = os.popen(command)
else :
pass for l2 in list2 :
str = raw_input('Do you want to delete: ' + l2 + '? (y/n)')
if str == 'y' :
command = 'del /f /q /a ' + l2
r = os.popen(command)
else :
pass if __name__ =="__main__":
list,list1 =searchSFN('C:\inetpub\wwwroot')
deleteSFN(list,list1) 这里提供了两个函数,searchSFN()找出应用目录中所有畸形目录名对应的短文件名和所有windows保留文件名,返回两个目录列表,deleteSFN()决定是否删除他们。
0X03 驱动隐藏webshell(Easy File Locker)
驱动隐藏的原理是在windows的指针遍历到一个文件夹的时,增加一个文件夹大小的偏移量,直接跳过文件夹,从而达到隐藏的目的。现在最常见到的驱动隐藏通常是借助第三方软件Easy File Locker实现的,几年前也就存在了,但是说说我自己测试的结果吧,手头的webshell查杀工具全军覆没,没有一个能反映出一点痕迹的。简单写了个函数用于查看是否存在Easy File Locker的服务并删除。利用了windows下的sc qc xlkfs、net stop xlkfs和sc delete xlkfs三条命令,xlkfs是Easy File Locker的服务名。(这里写成脚本模式是为了方便后续写成插件加入传统查杀工具,否则直接使用命令即可)
# -*- coding: cp936 -*- import os,os.path import re
def searchEFL(): line = '' command1 = 'sc qc xlkfs' #插看是否存在xlkfs服务,返回1060则判定不存在
command2 = 'net stop xlkfs' + '&' + 'sc delete xlkfs' #停止并删除服务
r =os.popen(command1)
info = r.readlines()
for l in info:
line = line+ l
if"1060" in line:
print'[+]No XLKFS service found.' else :
r =os.popen(command2)
print'[+]XLKFS service found. Has been cleared.' if __name__ == "__main__":
searchEFL() 0X04 总结
对于这几种通过破坏遍历规则的隐藏方式,其实都可以从其隐藏的动作直接判定它就是不怀好意的文件,不然为什么要做贼心虚的隐藏呢?但更可靠的方式就是先恢复遍历,让被隐藏的文件都能够被遍历到,然后再对文件进行常规的查杀。第一部分和第二部分提供的函数的最终目的都是为了最后提供对应的可访问的目录名列表,第三部分停止并删除了Easy File Locker的服务,文件自然就恢复了可遍历性。这里提供的函数单独也可以使用,但更推荐的做法是将其写成插件的形式加入传统查杀的工具中,使文件能够被遍历后,再对文件进行常规查杀规则的匹配。Github上有很多python的webshell查杀项目,匹配的一些特征库什么的已经很全了,写成插件加入后亲测效果不错,大家有兴趣可以自己动动手去实现。
(以上实验环境基于windows server 2008r2 standard,iis 7.0)