0x00: 前言
近日接连几次接触到关于UTF-8的non-shortest form的安全问题,即UTF-8的非最短形式编码的非法多字节数据在系统的不同处理过程中,先后被依照不同标准被解释,而可能造成现有安全机制被绕过的问题。
查找相关中文资料,发现关于编码安全相关内容的文章资料较少,所以在查找其它相关资料后,按照自己的理解写下此文。
0x01: Unicode与UTF-8
为防止读者对两者概念有所混淆,不方面下文的理解,故先区分两者的意义。
总的来说,Unicode是容纳了多国众多不同字符的大一统字符集合,其核心是提供了一个数值与字符映射关系的超大编码表格,是一个抽象的标准;现 在使用的Unicode(UCS-2,以下说明默认使用little endian方式存放)大都是用2个字节,也就是16 bit来表示一个字符;
而UTF-8是一种编码方式,是针对Unicode字符集的一种具体实现,它规定了如何通过一个数值来准确的找到相应的Unicode字符;UTF-8编 码使用变长的字节来存储不同的字符,这样做的目的,主要是可以节省存储空间,但是这样就必须解决另一个问题:字符从中间开始匹配的问题;
对这个问题随意举个栗子:一个字符需要3个字节表示,16进制表示为【0x02a706】,一个字符需要2个字节表示,16进制表示为【0x02a7】,那么我解析字符时,是到0x02a7时结束,还是继续解析,到0x02a706结束呢?
看下图,UTF-8的解决办法:用不同的比特位模式来标识一个字符的开头,表示该字符解析到第几个字节结束:

从上图可以看到,UTF-8一个字符固定前端的0、10、110、1110和11110位来区分字符是使用多少字节存放的;可以发现,UTF-8编码后,
不同字节长度的字符拥有不同的取值范围,不会重合,从而避免了上面提到的”从中间开始解析”的情况;
对于上图:
1 每列的意义
第一列表示Unicode字符的码值范围;
第二列表示UTF-8编码Unicode字符遵照的比特位排列模式;
第三列表示UTF-8编码Unicode字符后,Unicode码值实际被使用的bit位数;
2 区分Unicode字符值与UTF-8编码值
可以看出当Unicode字符值的范围为”800—FFFF”时,只要2个字节便可表示Unicode字符,用UTF-8编码则需要3个字节(24 bit)来表示。
第一列Unicode符号值的范围的计算: 只计算用”x”占位的位数
|
|
第一行第二列中有<span class="hljs-number">7</span>个<span class="hljs-string">"x"</span>占位,所以UTF-<span class="hljs-number">8</span>编码中使用的有效Unicode码比特位长为<span class="hljs-number">7</span>;
用<span class="hljs-number">7</span>个<span class="hljs-number">0</span>和<span class="hljs-number">7</span>个<span class="hljs-number">1</span>可以表示的二进制范围【<span class="hljs-number">0000000</span>—<span class="hljs-number">1111111</span>】,即范围为<span class="hljs-number">16</span>进制的【<span class="hljs-number">0</span>—<span class="hljs-number">7F</span>】;
第二行第二列中有<span class="hljs-number">11</span>个<span class="hljs-string">"x"</span>占位,所以UTF-<span class="hljs-number">8</span>编码中使用的有效Unicode码比特位长为<span class="hljs-number">11</span>;用<span class="hljs-number">11</span>个<span class="hljs-number">0</span>和<span class="hljs-number">11</span>个<span class="hljs-number">1</span>,接着上一个最大的数<span class="hljs-number">7F</span>,可以表示的二进制范围为
【<span class="hljs-number">000</span> <span class="hljs-number">10000000</span>—<span class="hljs-number">111</span> <span class="hljs-number">11111111</span>】,即范围为<span class="hljs-number">16</span>进制的【<span class="hljs-number">80</span>—<span class="hljs-number">7F</span>F】;
第三行第二列中有<span class="hljs-number">16</span>个<span class="hljs-string">"x"</span>占位,所以UTF-<span class="hljs-number">8</span>编码中使用的有效Unicode码比特位长为<span class="hljs-number">16</span>;用<span class="hljs-number">16</span>个<span class="hljs-number">0</span>和<span class="hljs-number">16</span>个<span class="hljs-number">1</span>,接着上一个最大的数<span class="hljs-number">7F</span>F,可以表示的二进制范围为
【<span class="hljs-number">00001000</span> <span class="hljs-number">00000000</span>—<span class="hljs-number">11111111</span> <span class="hljs-number">11111111</span>】,即范围为<span class="hljs-number">16</span>进制的【<span class="hljs-number">800</span>—FFFF】;
第四行第二列中有<span class="hljs-number">21</span>个<span class="hljs-string">"x"</span>占位,所以UTF-<span class="hljs-number">8</span>编码中使用的有效Unicode码比特位长为<span class="hljs-number">21</span>;用<span class="hljs-number">21</span>个<span class="hljs-number">0</span>和<span class="hljs-number">21</span>个<span class="hljs-number">1</span>,接着上一个最大的数FFFF,用来表示的二进制范围到达
【<span class="hljs-number">00001</span> <span class="hljs-number">0000000</span> <span class="hljs-number">00000000</span>—<span class="hljs-number">10000</span> <span class="hljs-number">11111111</span> <span class="hljs-number">11111111</span>】结束,<span class="hljs-number">16</span>进制即为【<span class="hljs-number">10000</span>—<span class="hljs-number">10F</span>FFF】;
|
总体看起来像下面这样(注意进制):
|
|
Unicode符号范围 <span class="hljs-string">| UTF-8编码方式</span>
(十六进制) <span class="hljs-string">| (二进制)</span>
—————————————————————————————————————————————————————————
<span class="hljs-number">0000</span> <span class="hljs-number">0000</span>-<span class="hljs-number">0000</span> <span class="hljs-number">007</span>F <span class="hljs-string">| 0xxxxxxx</span>
<span class="hljs-number">0000</span> <span class="hljs-number">0080</span>-<span class="hljs-number">0000</span> <span class="hljs-number">07</span>FF <span class="hljs-string">| 110xxxxx 10xxxxxx</span>
<span class="hljs-number">0000</span> <span class="hljs-number">0800</span>-<span class="hljs-number">0000</span> FFFF <span class="hljs-string">| 1110xxxx 10xxxxxx 10xxxxxx</span>
<span class="hljs-number">0001</span> <span class="hljs-number">0000</span>-<span class="hljs-number">0010</span> FFFF <span class="hljs-string">| 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx</span>
|
为方便理解,举个栗子:
中文简体”泽”字,如下图,它的Unicode字符值为”\u6cfd”,即16进制的”0x6cfd”,本来存储它需要2个字节:
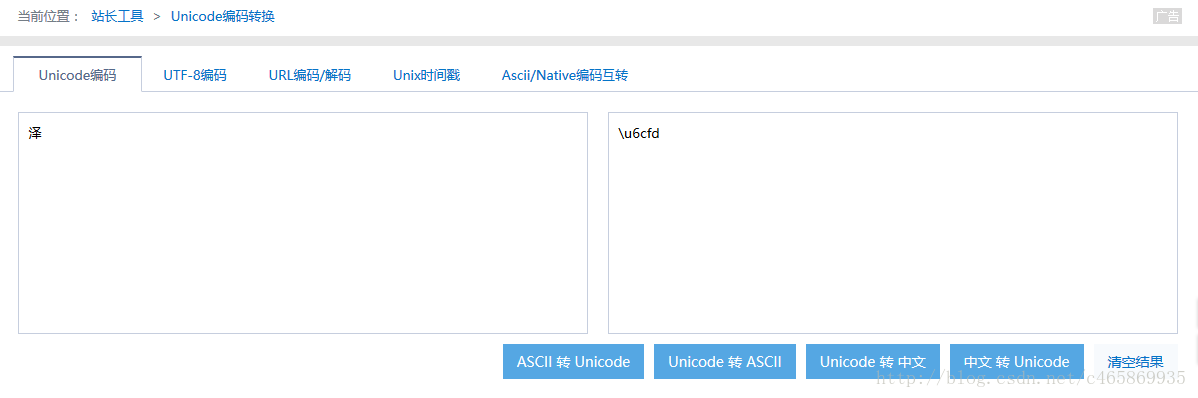
下面寻找它的UTF-8编码值:
|
|
<span class="hljs-number">0</span>x6cfd (二进制表示形式为:<span class="hljs-number">01101100</span> <span class="hljs-number">11111101</span>)处在<span class="hljs-number">800</span>—FFFF之间,UTF-<span class="hljs-number">8</span>编码方式存储则需要<span class="hljs-number">3</span>个字节;
由<span class="hljs-number">3</span>个字节所对应的UTF-<span class="hljs-number">8</span>编码的比特位模式:<span class="hljs-number">1110</span>xxxx <span class="hljs-number">10</span>xxxxxx <span class="hljs-number">10</span>xxxxxx;
可把<span class="hljs-number">16</span>个有效二进制位(分成<span class="hljs-number">0110</span>、<span class="hljs-number">110011</span>、<span class="hljs-number">111101</span>)对应取代模式中的<span class="hljs-number">16</span>个<span class="hljs-string">"x"</span>,得到<span class="hljs-string">"泽"</span>的UTF-<span class="hljs-number">8</span>编码值为:
<span class="hljs-number">11100110</span> <span class="hljs-number">10110011</span> <span class="hljs-number">10111101</span>,即<span class="hljs-number">16</span>进制的【E6B3BD】,故可知<span class="hljs-string">"泽"</span>字的UTF-<span class="hljs-number">8</span>编码值为:<span class="hljs-number">0</span>xE6B3BD
|
下图更为直观:

这样虽然UTF-8编码比Unicode字符集多用了一个字节来表示”泽”,但是清楚的知道”泽”字符占用两个字节,不会多或少解析一个字节,更不会不存在”从中间开始解析”的情况;
况且,UTF-8编码在表示ASCII码中的字符时,只需要1个字节(用Unicode一律是使用2个字节),可以节省存储空间。
弄懂了0x01部分的知识,我们可以发现:UTF-8默认都是用最短形式的编码值来表示一个Unicode字符,比如”/”字符,用UTF-8编码表示的话,值就是0x2F;所以0x2F就称为”/”字符的UTF-8编码最短形式值;
既然有最短形式,就有非最短形式,对于”/”字符的UTF-8编码值,
|
|
16进制 2进制
1个字节表示 0x2F 00101111
2个字节表示 0xC0AF 11000000 10101111
3个字节表示 0xE080AF 11100000 10000000 10101111
4个字节表示 0xF08080AF 11110000 10000000 10000000 10101111
|
可以看出,一个UTF-8编码的非最短形式的值,就是套用UTF-8编码比特位模式,将用不到的”x”占位都用0填充;
有的系统不会接受UTF-8非最短形式的编码,比如下图中的Python解析器,解析到上面讲到的”/”符号的非最短形式编码值,会报”非法多字节序列”的错误:
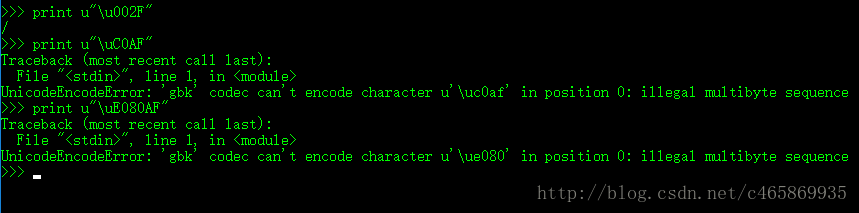
但是,有的系统又能解析UTF-8的非最短形式编码,双方对相同数据的理解存在歧义,从而有了0x03部分的安全隐患问题。
0x03: 非最短形式的安全隐患
1 产生原因
由于在安全检查时并未将UTF-8非最短形式编码的字符,如0xC0AF看作是 “/”正常字符,但是后续的处理中又将传入非最短形式编码的字符的0xC0AF看作”/”处理,从而引发安全问题。
2 真实案例
1. 在实际使用UTF-8非最短形式编码攻击的过程中,往往只将其中的一个Unicode字符进行UTF-8的非最短形式编码,其它尽量保持不变,即可绕过安全检查;
如攻击中常用的目录遍历的四个字符”/../”:
|
|
<span class="hljs-string">"/"</span>的UTF-<span class="hljs-number">8</span>最短形式编码值为<span class="hljs-number">0x2F</span>(二进制<span class="hljs-number">00101111</span>), <span class="hljs-string">"."</span>的UTF-<span class="hljs-number">8</span>最短形式编码值为<span class="hljs-number">0x2E</span>(二进制<span class="hljs-number">00101110</span>)
如果将上述四个攻击字符依次写成<span class="hljs-number">2F</span>2E2E2F,那么安全检查将识别出它为<span class="hljs-string">"/../"</span>,攻击就不会奏效;
但当我将其中的一个字符<span class="hljs-string">"."</span>用UTF-<span class="hljs-number">8</span>的非最短形式编码,按照两个字节形式编码成:C0AE(二进制<span class="hljs-number">11000000</span> <span class="hljs-number">10101110</span>),其余字符照旧写,则最后<span class="hljs-string">"/../"</span>可被写成:<span class="hljs-number">2F</span>C0AE2E2F,与最初的<span class="hljs-number">2F</span>2E2E2F值显然不一样,安全检查很可能会被绕过,但是当其它组件解析时,又可能将其解析成<span class="hljs-string">"/../"</span>,而被他人成功攻击;
|
2. 另一攻击真实案例Twitter HTTP Response Splitting如下:过程参考
这个案例虽然主要是利用了CRLF注入HTTP头和一个Firefox通常只解析HTTP响应头中一个ASCII字符的Bug,只是顺带用百分号编 码后的UTF-8编码绕过安全检查,并没涉及到UTF-8非最短形式编码引起的问题,但还是附带介绍下,希望读者重视因编码问题引起的程序安全隐患,如下 图:

本来一个正常”嘊”(U 560A)字的Unicode字符值为”0x560A”(最后一个字节为0x0A,最短形式表示换行符”\n”,用来断 行,实施CRLF注入,实现HTTP响应头的截断攻击),通过UTF-8正常编码后,值就变为了”0xE5988A”,漏洞作者输入百分号编码后的 UTF-8编码值%E5%98%8A,然后通过了安全检查,服务器将接收的值”0xE5988A”解码成Unicode字符值”0x560A”,在被放入 到HTTP响应头中时,因为上面说的Firefox的一个漏洞,移去了字符值超出ASCII码范围的部分,只留下了0A,故成功的实施了攻击。
附: 双字节表示的空字符问题
在C语言等语言程序中,单字节空字符”0x00”是用来标志字符串结尾的;如果使用双字节形式表示的空字符”0xc080”,就有可能使原来防范字符串截断攻击的安全检查失效,造成安全问题。
3 如何防范
-
在应用内使用统一的字符集
-
输入非法数据时报错并终止处理
-
处理数据时使用正确的编码方式
-
输出时设置正确的字符编码
-
在函数参数中明确设置编码方式
-
避免使用字符编码模糊检测功能
4 启示
上述攻击过程读者不必全部理解;需要明白的是:编码安全应当获得足够的重视,如果没有严格管控开发时使用的编码,特别是不对输入、输出部分进行有效的编码和解码,轻则留下程序Bug,重则埋下安全隐患,现有安全措施很可能因此而全部被绕过,安全事件一触即发。
作者: LandGrey
【via@LandGrey】 原文链接:http://blog.csdn.net/c465869935/article/details/54407084
