
回顾
我们在上一篇文章中讨论 TDD 开发渗透工具,并且完成了我们 HTTP 代理扫描器的一个功能模块。那么我们接下来就继续使用 TDD 完成接下来的部分,大家也深入理解一下这种开发方式的好处(可是代码量大啊~hhhh)。
如何继续上次的任务?
先运行测试用例!
如果上次的任务没有完成,你就需要继续调整你的代码,修改,通过测试用例,这就是你首先要做的,当然如果上次的任务你完成了,测试用例顺利通过,那么当然好啊,接下来你就可以直接再写一个测试用例,开始一个新的功能或者模块了。
继续
在之前的文章中我们完成了针对一个地址的代理验证,那么,我们接下来应该怎么做呢?如果我们有一堆地址需要检测,这样我们就要处理两大问题:
安全的多线程(多进程)并发
正确收取结果
短小精干的并发处理
这样的话,涉及到多线程编程,保证线程安全什么 BlaBla,对于一个渗透测试爱好者来说,可能会稍微有一点挑战:(我平时写的爆破甚至都是单线程的!),写多线程还是有点麻烦的!
当然我这里也有考虑到这一点,在写过很多类似的脚本之后,最近也算是首创了一种短小精悍的并发框架,具体的开发流程自然也是 TDD,这里我就不会和上次一样很细致的一步一步来讲到底是怎么写的。我们就一起来看一下吧!
def test_pool(self): '''测试并发''' #定义一个任务函数,参数 *args 不定长 def demo_task(*args): '''simulate the plugin.run''' print '[!] Computing!' time.sleep(args[0]) print 'Sleep : ', args[0] print '[!] Finished!' print returns = 'Runtime Length : %s' % str(args) return returns #基本使用方法 #1. 建立一个并发池对象, #2. 添加任务 #3. 启动 #4. 通过一个队列获取结果 pool = Pool()
pool.add_task(demo_task, 7)
pool.add_task(demo_task, 3)
q = pool.run()
self.assertIsInstance(q, Queue)
r = q.get() print r
self.assertIsInstance(r, str)
pool.add_task(demo_task, 4)
pool.add_task(demo_task, 2)
pool.add_task(demo_task, 1)
pool.add_task(demo_task, 6)
pool.add_task(demo_task, 7)
pool.add_task(demo_task, 1)
pool.add_task(demo_task, 6)
pool.run()
r = q.get() print '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~' ,r
大家会发现,在测试的过程中,已经写明了这个并发池的基本使用方法,当然这个使用方法不是根据 Pool 源代码写出的,而是我自己“瞎”写的:也就是说,我并不知道源代码,但是我设想我的小框架应该这么写,所以我就这么写了,至于怎么实现,不是我写测试用例需要考虑的问题。所以,现在觉得,这个框架是非常的用户友好啊:至少对我自己来说用起来是非常的舒服。
换句话来说,我在写上面的代码的时候,其实并不知道自己的控制并发的小玩意叫什么内部内部什么构造,需要什么模块,需要什么函数,或者有没有什么特殊属性之类的,就只是“我觉得他应该是这样的”而已。
至于写下了测试用例以后发生了什么我觉得就不用再多说了,大家都可以猜得到就是不停测试不停修改代码直到成功完成需要的功能。(当然这个测试程序的测试代码就不会面面俱到,满足我们需求的代码就OK)
期待的运行结果如下:
[!] Computing! [!] Computing! Sleep : 3 [!] Finished! Runtime Length : (3,) [!] Computing! [!] Computing! [!] Computing! [!] Computing! [!] Computing! [!] Computing! [!] Computing! Sleep : 1 Sleep : [!] Finished!
1 [!] Finished!
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Runtime Length : (1,)
. ---------------------------------------------------------------------- Ran 1 test in 4.033s OK Sleep : 2 [!] Finished! Sleep : 7 [!] Finished! Sleep : 4 [!] Finished! Sleep : 6 [!] Finished! Sleep : 6 [!] Finished! Sleep : 7 [!] Finished! 获取 3s 和 1s 的两个结果,其他的分开操作不去获取结果,测试在 4.033s 结束,其余的进程后台运行,但是不会被获取结果:成功达到了初衷。
源码在下面:
class Pool(object): """Thread or Proccess Pool to support the
concurrence of many tasks""" #---------------------------------------------------------------------- def __init__(self, thread_max=50, mode='Thread'): """Constructor""" modes = ['thread', 'process']
self.mode = mode.lower() if mode in modes else 'thread' self.task_list = []
self.result_queue = Queue()
self.signal_name = self._uuid1_str()
self.lock = threading.Lock() if self.mode == 'thread' else multiprocessing.Lock()
self.thread_max = thread_max
self.current_thread_count = 0 def _uuid1_str(self): '''Returns: random UUID tag ''' return str(uuid.uuid1()) def add_task(self, func, *args, **argv): '''Add task to Pool and wait to exec
Params:
func : A callable obj, the entity of the current task
args : the args of [func]
argv : the argv of [func]
''' assert callable(func), '[!] Function can \'t be called' ret = {}
ret['func'] = func
ret['args'] = args
ret['argv'] = argv
ret['uuid'] = self.signal_name
self.task_list.append(ret) def run(self): """""" self._init_signal()
Thread(target=self._run).start() return self.result_queue #---------------------------------------------------------------------- def _run(self): """""" for i in self.task_list: #print self.current_thread_count while self.thread_max <= self.current_thread_count:
time.sleep(0.3)
self._start_task(i) def _start_task(self, task): """""" self.current_thread_count = self.current_thread_count + 1 try: if self.mode == 'thread': #print 'Start' Thread(target=self._worker, args=(task,)).start() elif self.mode == 'process':
Process(target=self._worker, args=(task,)).start() except TypeError:
self.current_thread_count = self.current_thread_count - 1 def _worker(self, dictobj): """""" func = dictobj['func']
args = dictobj['args']
argv = dictobj['argv']
result = func(*args, **argv)
self.lock.acquire()
self._add_result_to_queue(result=result)
self.lock.release() def _add_result_to_queue(self, **kw): """""" assert kw.has_key('result'), '[!] Result Error!' self.result_queue.put(kw['result'])
self.current_thread_count = self.current_thread_count - 1 嗯,总之,这一百行不到代码可以实现:
控制线程数量监控:current_threads
简单易用的一次执行多个任务接口
异步获取结果
随时添加任务
我们想要的是批量执行扫描 IP 代理,所以上面的东西完全满足我们需求了。
下面我就简单来介绍一下上面的可以控制并发的 Pool 的流程,方便需要的读者可以参考一下:
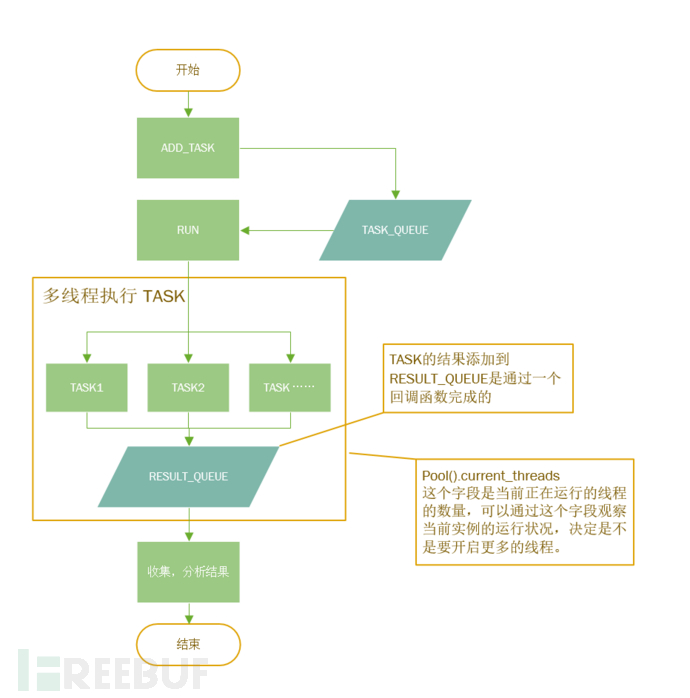
但是由于我们的工具是自己使用,或者说是实验用,就不考虑 Treading/eventlet/stackless 的选择问题了,也不纠结给这个小工具命名的问题。(虽然我觉得这样说是有一些不负责任的)
获取与解析目标
拿到目标地址,我们既然是扫描肯定是批量扫描,那么我们肯定是要批量获取 IP 地址。
我们说的获取 IP 地址当然不是 DNS 查询,我们说的当然是我们需要怎么处理很多个 IP 地址:用户指定一个范围;或者仅仅是随机扫描特定区域的网段。想想,大多也就这样了,不会有新的途径了吧。然后 IP 地址有了,端口呢?我们怎么样选择扫描的端口?首先,我们肯定不能扫描全部的端口,因为这样速度太慢了,而且比如 3306 5432 111 22 25 这些端口显然不可能是一个 http 代理端口,我们就没必要对这些端口进行检查,根据经验来说 80-90, 8080-8090 这些端口是一个 http 代理的可能行比较大,再缩小一点,80,8080,8123,3128,9000。 就先这么多吧!
那么我们获取和解析目标的思路就有了: 获取一堆 IP 地址,然后用这一堆 IP 地址与想要检查的端口进行组合,然后把组合结果分配给我们上面刚刚完成的并发框架,然后收取结果。
好的,思路我们清楚之后,就需要开始动手完成这个部分了,没错,首先就是编写测试:
class ParseTargetTest(unittest.case.TestCase): """Test Parse Target""" #-------------------------------------------------------------- def runTest(self): IPs_1 = '123.1.2.0/24' IPs_2 = '123.1.2.3-123.1.3.5' ip_gen = generate_target(IPs_1, PORTS)
self.assertIsInstance(ip_gen, iter) for i in ip_gen:
ip_port = i.split(':') try:
IPy.IP(ip_port[0]) except ValueError: pass ip_gen = generate_target(IPs_2, PORTS)
self.assertIsInstance(ip_gen, iter) for i in ip_gen:
ip_port = i.split(':') try:
IPy.IP(ip_port[0]) except ValueError: pass
这样的测试如果跑通的话,我们只需要通过一个 generate_target 这个函数,就可以解析 IP 地址了,可以解析 IP 地址段,也可以解析单个 IP 地址,返回值是通过 yield 产生 generator。
根据这样的测试用例我们使用 IPy 模块,进行基本的 IP 运算(IP 地址网络运算),我们很容易就可以解决上面的问题:
import unittest import re import IPy from IPy import IP
PORTS = ['80', '8080', '8123', '3128', '82'] #---------------------------------------------------------------------- def generate_target(IPs, ports): """Generate the target for scanning HTTP proxy
Returns:
A Generator: """ gen = None if '-' in IPs:
pairs = IPs.split('-')
start = pairs[0]
end = pairs[1]
gen = int2ips(IP(start).int(), IP(end).int()) else:
gen = IP(IPs) for i in gen: for port in ports: yield ':'.join([i.__str__(), port]) #---------------------------------------------------------------------- def int2ips(start, end): """""" for i in xrange(int(start), int(end)): yield IPy.intToIp(i, version=4) 上面的代码,看起来甚至还要比测试代码还要短,其实这就是 TDD 的魅力之一啊,编写出最简洁最少的满足功能的代码。
架构探讨与整合功能
现在我们的基本功能都完成了,我们现在应该做什么呢?先想一下我们这个功能的具体流程:
生成目标
多线程扫描
收集结果
大致是这个样子,但是我们仔细想一想,好像还需要一点别的东西:
用户交互(命令行工具 or Web 接口工具?)
工具架构以及扩展性(万一我以后除了扫描代理,还想扫描别的东西呢?)
万幸的是,我们完成的功能是分离的,那么我们现在需要考虑的就是怎么把功能拼接起来。
我们一开始定位是一个代理扫描器,但是现在,我们如果改动一下检查代理(proxy_check)模块,如果改成针对某个端口的 EXP 利用的话,这个工具显然也是可以满足针对某个端口(或者针对某项服务)的扫描-探测-利用的。
换一句话来说,我们现在就想实现 proxy_check 的插件化,那么,问题就来了,现在想要实现我们为了实现插件化解耦(当然我们面对的情景很简单),就需要考虑一下如何插件化?
万幸的是 Python 提供了一个 pluginbase 的模块,但是我们并不打算使用这一个模块,就编写一个插件基类,然后让所有的插件去继承这个基类,然后我们在工具中调用插件基类的接口就可以,这样就可以实现调用多种类型的功能模块了,现在也就只需要所有的功能模块都继承插件并且按照一定规范完成功能编写。
这样来想的话,我们的架构也就非常明朗了:
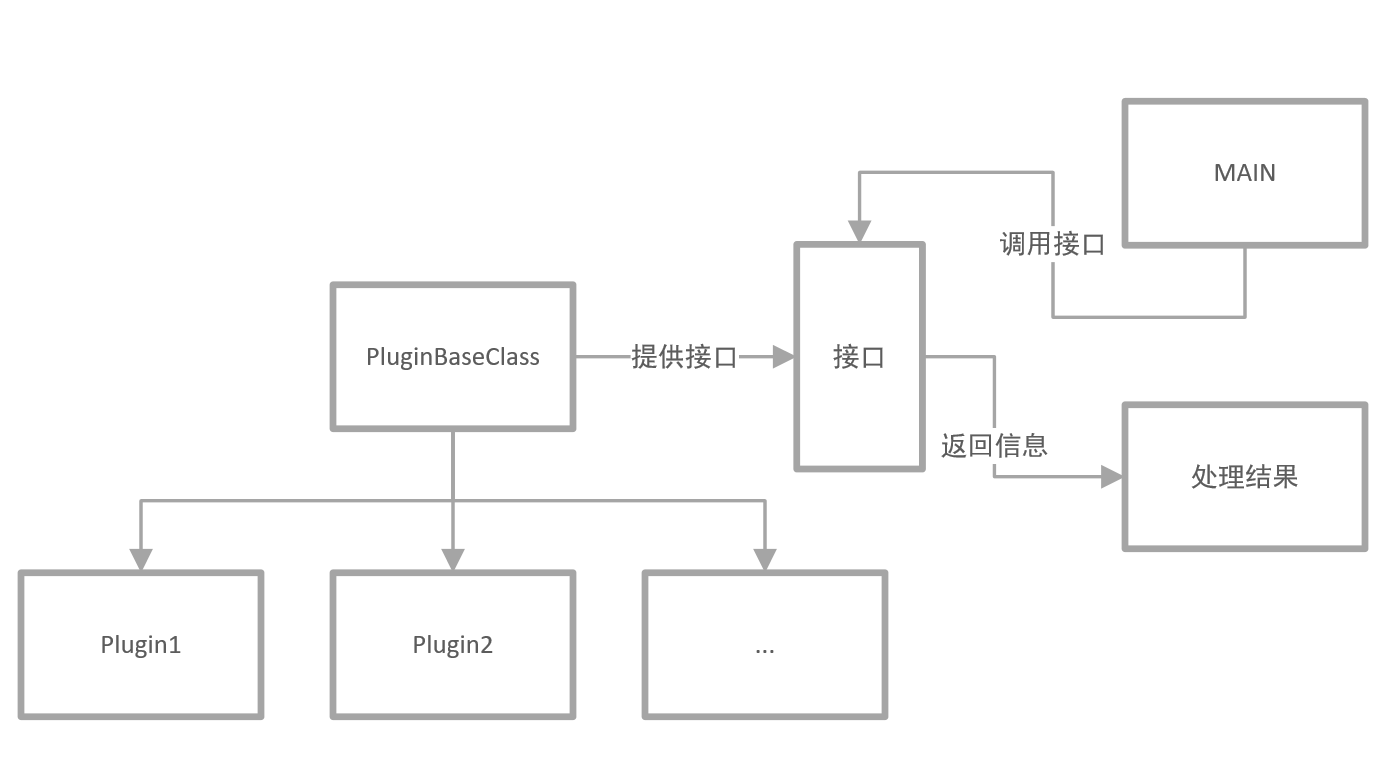
那么我们发现如果怕这样设计的话,显然我们需要重新编写基类,然后稍微改造一下原来的功能模块。
其实是非常简单的,我们的插件其实只需要传入参数->执行->处理输出就可以了,再加上基本的属性,什么插件名称,插件描述,就可以完成了不是么?
class PluginBaseClass(object): """""" __mateclass__ = abc.ABCMeta #---------------------------------------------------------------------- def __init__(self): """Constructor""" pass #---------------------------------------------------------------------- @abc.abstractproperty def name(self): """""" return '...' #---------------------------------------------------------------------- @abc.abstractproperty def description(self): """""" return '...' #---------------------------------------------------------------------- @abc.abstractmethod def _work(self, *args, **kwargs): """""" return '...' #---------------------------------------------------------------------- @abc.abstractmethod def _parse_result(self, result): """""" return "..." #---------------------------------------------------------------------- def start(self, *args, **kwargs): """""" #print 'cl' ret = self._work(*args, **kwargs) #SOMETHING IF NEEDED return self._parse_result(ret) 这样我们定义了插件的基类,继承这个插件,必须复写的特性和方法有:
name 属性
description 属性
_work 方法
_parse_result 方法
这样满足了最基本插件的要求了吧:至少要有个名字,有个简单描述,有功能函数,结果解析函数。(关于结果解析的必要性呢?我们考虑如果以后需要添加更多的不同类型的功能插件的话,结果肯定不可能是完全统一的,因此我们需要一个解析结果的函数帮我们完成一些工作)。
那么我们主函数负责任务发布,只需要调用所有插件的 start 函数传入任意的参数就可以完成操作了(但是参数的处理我们肯定要先在程序中完成的对吧?)。
重构功能函数!
当然我们要把功能函数改造成(或者再次编写)一个插件才能丢给程序执行。怎么改造呢?上一节讲过的,就是继承插件,然后复写该复写的方法和属性就可以完成了。当然,我们动手肯定应该先去写测试方法对不对?先有测试后有代码。值得一说的是,这次在重写测试方法的时候就有点意思了,我们可以把自己暂且当成主程序,主程序来调用这个插件,应该怎么样调用呢?
def test_plugin_ins(self): '''''' pprint('Plugin Test')
ret = CheckProxyPlugin()
_result = ret.start('45.78.5.48:333') for _ in _result:
pprint(ret.name)
pprint(ret.description)
pprint(_) 大概这就我们理想的样子吧:接口简单完备,完成的功能什么大家心里有数,那么插件究竟是什么样子的呢?其实非常简单。并没有直接去复制代码,而是采用调用原功能的方法进行简单构造:
class CheckProxyPlugin(PluginBaseClass): """""" _name = 'Check Proxy' _description = 'Check if the specific addr(IP:PORT) is a \
HTTP(s) proxy' #---------------------------------------------------------------------- @property def name(self): """getter for self._name""" return self._name #---------------------------------------------------------------------- @property def description(self): """getter for self._description""" return self._description #---------------------------------------------------------------------- def _work(self, *args, **kwargs): """""" ret = CheckProxy(args[0]) return ret.test(timeout=int(kwargs['timeout']) if kwargs.has_key('timeout') else 3) #---------------------------------------------------------------------- def _parse_result(self, result): """""" return result 其实这样就完成了这个插件了,然后我们对这个插件的调用只有获取插件实例,调用方法,等结果了。
其他的一些小工作
(╯‵□′)╯︵┻━┻ 现在基本该有的东西都有了而且,接下来就来做一些“填充”之类的东西了:
解析命令行(交互编写)
主程序调用
结果处理
交互
这里既然是一个实验小程序,我们就简单写一个命令行解析吧,之前提到的采用 argparser 模块。
对于接下来收尾的小东西,TDD 当然也适用,但是为了解决时间,我们就简单过一下吧,剩下的都不是重点了。
#---------------------------------------------------------------------- def parse_args(): """""" parser = argparse.ArgumentParser(description='Pr0xy Scan and collect proxy info')
parser.add_argument('IP',
help='''The IP you want to check: \nINPUT format:\ 1.2.3.4-1.2.5.6 or 45.67.89.0/24 or
45.78.1.48''')
parser.add_argument('--ports', dest='ports',
help='The ports you want to check, Plz input single port\
or with a format like: 82,80 or 100-105')
parser.add_argument('--type', dest='type',
help='Type of scan [Now Just Support proxy]')
args = parser.parse_args()
args.IP #print args.ports #pprint(args) PORTS = []
raw_ports = args.ports if '-' in raw_ports:
_ = raw_ports.split('-')
_min = _[0]
_max = _[1]
PORTS = range(_min, _max) elif ',' in raw_ports:
_list = raw_ports.split(',') for _ in _list: if _.isdigit():
PORTS.append(int(_)) else: pass #PORTS.append(object) if PORTS == []:
PORTS = parse_target.PORTS else: if raw_ports.isdigit():
PORTS.append(int(raw_ports)) else:
PORTS = parse_target.PORTS #pprint(args.IP) #pprint(PORTS) return (args.IP, PORTS, args.type) 这里还是有必要解释一下参数:
-
IP 就表示 IP地址,你可以输入单个或者多个(必须是点分十进制),当然形式限制三种:
- 1.单个 IP 地址
- 2.短横线连接符表示的 IP 范围(例如 1.2.3.4-1.2.3.9 这表示 6 个 IP)
- 3.带有掩码的网络范围(例如1.2.3.0/24)
- 端口(略)
- 类型:这里的类型还是有必要解释的,万一以后需要添加其他的功能,就可以直接改动一张表添加新的模块,然后通过指定类型调用。
通过 type 调用插件
定义一张表,这张表纪录插件的地址以及插件的类名称
SCAN_TYPE_TABLE = { 'proxy': {'module':'lib.check_proxy', 'plugin_class':'CheckProxyPlugin'}
} 然后动态导入特定插件:
def get_pluginclass(type_name): """""" try: try:
plugin_class_path = SCAN_TYPE_TABLE[type_name] except KeyError:
pprint('[!] No Such Type')
exit()
module_name = plugin_class_path['module']
plugin_class_name = plugin_class_path['plugin_class']
module_tmp = __import__(module_name, fromlist=plugin_class_name)
ret = getattr(module_tmp, plugin_class_name) return ret except Exception, E:
traceback.format_exc()
exit() 导入之后就可以通过统一的接口去调用我们的插件了:
def main(): """Pr0xy main""" params = parse_args()
IP = params[0]
PORTS = params[1]
pool = Pool()
plugin_class = get_pluginclass(params[2]) for target in parse_target.generate_target(IP, PORTS):
_ = plugin_class(target)
pool.add_task(_.start)
result_queue = pool.run() while True: try:
ret = result_queue.get(timeout=0.3) # 这里出现了一个处理结果的函数 process_result(ret) except Empty: pass except KeyboardInterrupt:
pprint('ByeByeBye') 收工总结:
当然我承认这个工具实在是太简单了!
到现在,这个工具已经可以拿出去用了,而且,你如果觉得仅仅是扫描代理有点太 low 了吧!那么我们这一节探讨了架构与拓展方面的东西,我相信如果想把它拓展一下做成一个全网扫描特定端口,自动打 EXP 的插件真的是相当容易对不对?也就是照着上面的插件的样子写一个插件,然后填一下插件表,就可以直接去用了。
这算是对上一篇文章的一个比较好的交代了吧。
其实作为一个并不是职业开发的 WEB 狗,写安全工具应该算是一个不大不小的挑战了吧,我也是啊,一致梦想有一套专属的自己开发的渗透集成平台,最近在大家的帮助下经过了无数次重构,终于完成了框架,已经填了很多个插件自己在使用,下一步准备尝试部署在多个服务器上形成集群,我相信再有一段时间,自己的梦想就实现了~
笔者水平实在是不高,而且也不是专业开发,如果代码写的辣眼睛,也请有需要的读者多多包涵。
GITHUB 地址: https://github.com/VillanCh/pr0xy
*本文原创作者:VillanCh