
在这个系列文章中,我们将演示如何手工渗透测试web应用程序而不使用自动化工具。世界上大多数公司都非常关注对web应用程序的手工测试,而不是运行web应用程序扫描器——因为它会限制你的知识和技能,影响在测试中寻找漏洞的视野。
NOWASP Mutiliadae
BURP Proxy
在整个系列文章中,我将使用下面的程序:
NOWASP Mutiliadae
NOWASP Mutiliadae是一个包含了40多个漏洞的web应用程序。它包括OWASP的top 10漏洞,也有其它组织的列表中的漏洞。其中有可以利用web应用程序扫描器(比如Vega, Acunetix, Nikto, w3af等)扫描出的小型和中型漏洞。我将使用这个程序的最新版本,它以面向对象的方式设计,这可以让我们更好地理解web应用程序的所有漏洞。
Burp Suite
我将用到的另外一个工具是Burp Proxy。它是一个介于客户端(浏览器程序,比如Firefox或者Chrome)和网站或服务器之间的代理。它将在我的本地计算机上运行,截获浏览器和目标机(在我们的环境中,目标机是NOWASP Mutiliadae)之间的出站或入站流量。这个工具的主要作用在于,当你请求访问一个服务器时,Burp Suite拦截从你的机器发往服务器的请求,你可以根据需要改变请求的内容。它也可以显示请求的类型,是GET或是POST请求,或者是其它类型的请求。Burp也有另外一个功能,可以显示你发往网站的参数列表。你可以根据检查web应用程序的安全性的需要操作请求内容。为了拦截请求,你的Burp Proxy listener必须配置成监听127.0.0.1 localhost的8080端口。然后你还需要设置浏览器的代理配置,完成之后,选择Suite => proxy tab => Intercept,开启拦截。我不会深入介绍所有的tab选项卡以及他们的功能。你可以查看Burp的手册和文档。

Web的工作流程
在开始之前,你应该了解web在后端是如何工作的,这些你在web浏览器是看不到的。当你访问一个网站时,你的浏览器访问web服务器上的一个文件,这个文件可以是HTML, PHP, js (JavaScript), CSS, ASPX等等。使用Burp Suite,我们能观察到下图所示的请求。为了查看请求,我按上面的方法配置了Burp和浏览器,然后访问下图所示的HTML5 storage page。
一旦我点击了超链接,Burp就会拦截这个请求,内容如下。你可以看到它是一个访问服务器上的index.php页面的请求。这里的参数是page,参数的值是html5-storage.PHP。
GET /chintan/index.php?page=html5-storage.php HTTP/1.1
Host: localhost
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:27.0) Gecko/20100101 Firefox/27.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://localhost/chintan/
Cookie: showhints=0; username=chintan; uid=19; PHPSESSID=j53u16lcdkjq0eec6nfijphkd4
Connection: keep-alive
我想要访问这个页面,所以我转发这个请求。如何你查看response选项卡,会发现我收到了一个“200 OK”的响应。
HTTP/1.1 200 OK
Date: Sat, 28 Dec 2013 23:30:08 GMT
Server: Apache/2.4.3 (Win32) OpenSSL/1.0.1c PHP/5.4.7
X-Powered-By: PHP/5.4.7
Logged-In-User: chintan
Keep-Alive: timeout=5, max=100
Connection: Keep-Alive
Content-Type: text/html
Content-Length: 46178
“200 OK”表示我的请求被成功执行,并给我返回了响应。如果观察浏览器,就会发现所有的web页面都已经加载了。
注意:你每次发送请求的时候,都会动态创建一个HTML文件。后台的PHP文件会接收到你的请求,创建一个HTML文件并发送给你的浏览器,浏览器负责渲染页面。你在web浏览器上看到的并不是一个web页面,而是浏览器对页面该怎样图形化展示的解释。
“不要只看在web浏览器上看到的图像,要经常练习以源代码的方式查看web页面以便熟悉它。你要尽可能熟悉JavaScript, XML, 以及所有的HTML标签。”
如何入手
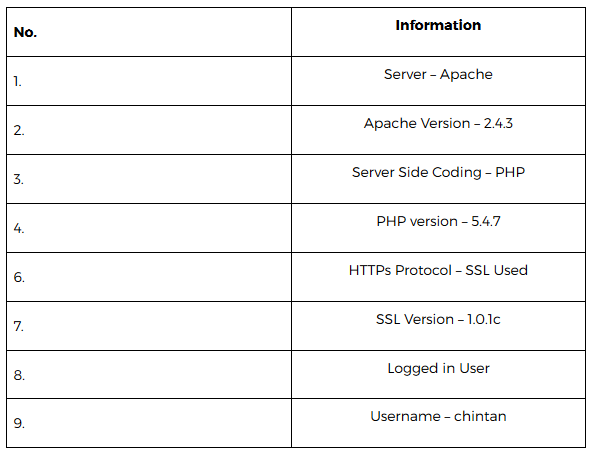
当开始测试时,初学者普遍存在的问题是该从哪里入手。我们都知道黑客的工作周期。第一个阶段是信息收集或者侦查。在这个例子中,我将尽可能多得获取关于网站和服务器的信息,并不需要浏览所有的web页面。如果你注意到上面的请求和响应,我们已经得到了一些东西。有如下信息:
有很多种收集信息的方法。人们大多使用Google,Recon-ng框架等应用程序安全测试工具。我将使用Burp Suite中的spider列出目标的所有页面和文件夹。首先,打开history,选中你访问的第一个页面。右击它,选择add to the scope选项。
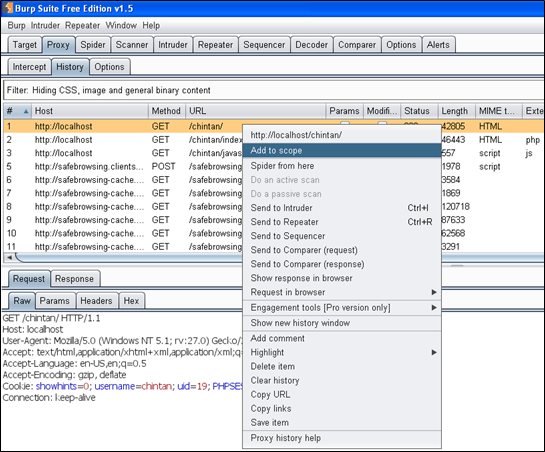
现在,如果你打开target选项卡,你会看到网站的范围。在我的例子中是localhost,如下图所示。
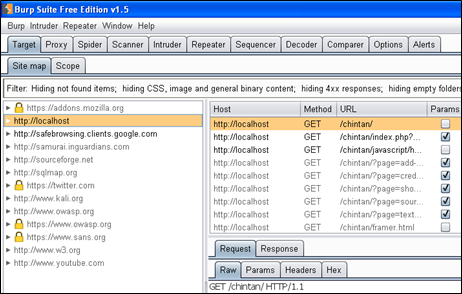
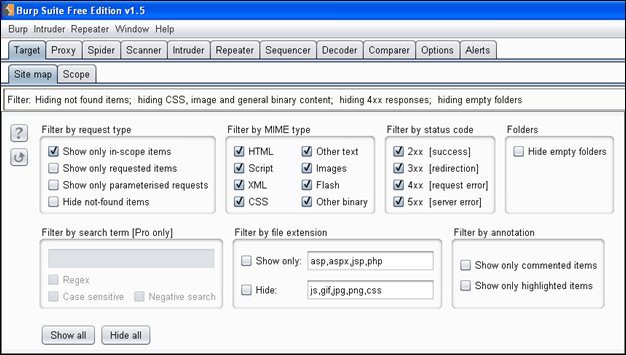
“它也会列出你不知道的访问过的其它网站。比如有一个网站:有“like”按钮,“share”按钮,或者有挂在网站上的广告。要想去除某些项,点击filter栏,根据下图设置你的选项,然后点击空白处任意位置,你的修改就会被应用”
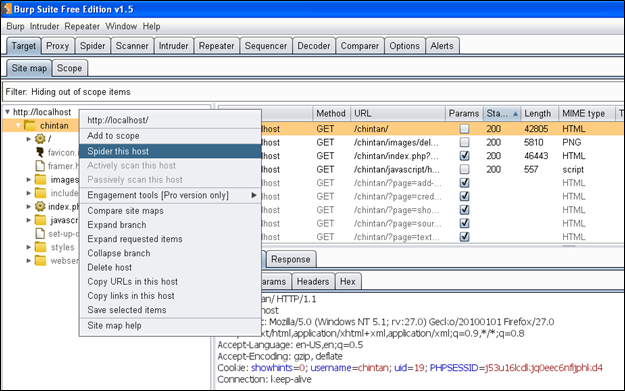
接着,正如我所说,我需要爬取这个主机。所以,我右击localhost,选择spider this host选项。如果目标应用程序中有表格,会弹出一个框,你需要填写并提交表格的值。
在点击之后,就会开始爬取你的目标主机。如果你打开spider选项卡,你会看到类似于下图的东西。
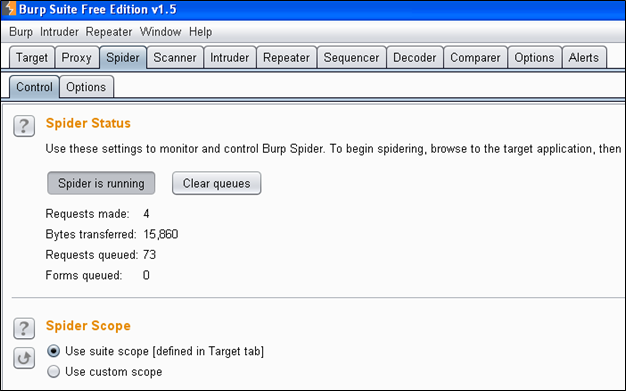
“如果请求队列变成了0,并且持续了足够的时间,就说明完成了对web应用程序的爬取”
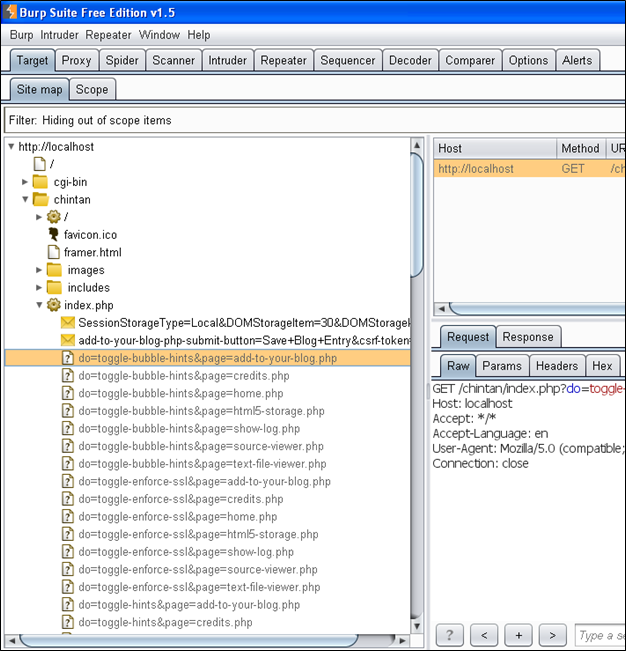
接着,打开target选项卡,你会看到web应用程序所有的页面列表。会增加一些新的页面。
代理设置
并没有特别的设置或配置,我的配置如下图。
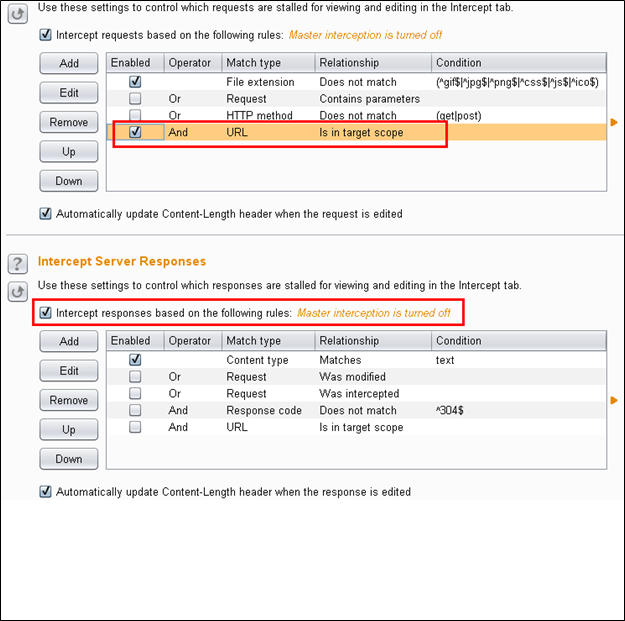
我这样设置的原因是,目标主机可能链接了其它网站的share按钮,广告等。我想拦截我自己和目标主机之间的所有通信,但是不需要其它网站的干扰。所以我选中了“Is in target scope.”复选框,只拦截在目标范围内的请求。我也想拦截服务器返回的所有响应,这样我就能知道我的请求被处理,或者重定向到了其它地方,等等。所以我选择了拦截所有响应的复选框。
下节预告
在本系列文章的下个部分,我将展示如何识别应用程序的入口点和注入点,以及服务器如何编码你的输入。
引用
http://sourceforge.net/projects/mutillidae/
翻译自:http://resources.infosecinstitute.com/manual-web-application-penetration-testing-introduction/